 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiLorE-SSL: Scaling Multilingual Capabilities in Self-Supervised Models without Forgetting
Jan 28, 2026Self-supervised learning (SSL) has greatly advanced speech representation learning, but multilingual SSL models remain constrained to languages encountered during pretraining. Retraining from scratch to incorporate new languages is computationally expensive, while sequential training without migitation strategies often leads to catastrophic forgetting. To address this, we propose MiLorE-SSL, a lightweight framework that combines LoRA modules with a soft mixture-of-experts (MoE) mechanism for efficient continual multilingual training. LoRA provides efficient low-rank adaptation, while soft MoE promotes flexible expert sharing across languages, reducing cross-lingual interference. To further mitigate forgetting, we introduce limited replay data from existing languages, avoiding reliance on large historical corpora. Experiments on ML-SUPERB demonstrate that MiLorE-SSL achieves strong performance in new languages and improves the ability in existing ones with only 2.14% trainable parameters.
Speech Discrete Tokens or Continuous Features? A Comparative Analysis for Spoken Language Understanding in SpeechLLMs
Aug 25, 2025With the rise of Speech Large Language Models (SpeechLLMs), two dominant approaches have emerged for speech processing: discrete tokens and continuous features. Each approach has demonstrated strong capabilities in audio-related processing tasks. However, the performance gap between these two paradigms has not been thoroughly explored. To address this gap, we present a fair comparison of self-supervised learning (SSL)-based discrete and continuous features under the same experimental settings. We evaluate their performance across six spoken language understanding-related tasks using both small and large-scale LLMs (Qwen1.5-0.5B and Llama3.1-8B). We further conduct in-depth analyses, including efficient comparison, SSL layer analysis, LLM layer analysis, and robustness comparison. Our findings reveal that continuous features generally outperform discrete tokens in various tasks. Each speech processing method exhibits distinct characteristics and patterns in how it learns and processes speech information. We hope our results will provide valuable insights to advance spoken language understanding in SpeechLLMs.
MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
Jun 05, 2025Speech inherently contains rich acoustic information that extends far beyond the textual language. In real-world spoken language understanding, effective interpretation often requires integrating semantic meaning (e.g., content), paralinguistic features (e.g., emotions, speed, pitch) and phonological characteristics (e.g., prosody, intonation, rhythm), which are embedded in speech. While recent multimodal Speech Large Language Models (SpeechLLMs) have demonstrated remarkable capabilities in processing audio information, their ability to perform fine-grained perception and complex reasoning in natural speech remains largely unexplored. To address this gap, we introduce MMSU, a comprehensive benchmark designed specifically for understanding and reasoning in spoken language. MMSU comprises 5,000 meticulously curated audio-question-answer triplets across 47 distinct tasks. To ground our benchmark in linguistic theory, we systematically incorporate a wide range of linguistic phenomena, including phonetics, prosody, rhetoric, syntactics, semantics, and paralinguistics. Through a rigorous evaluation of 14 advanced SpeechLLMs, we identify substantial room for improvement in existing models, highlighting meaningful directions for future optimization. MMSU establishes a new standard for comprehensive assessment of spoken language understanding, providing valuable insights for developing more sophisticated human-AI speech interaction systems. MMSU benchmark is available at https://huggingface.co/datasets/ddwang2000/MMSU. Evaluation Code is available at https://github.com/dingdongwang/MMSU_Bench.
$C^2$AV-TSE: Context and Confidence-aware Audio Visual Target Speaker Extraction
Apr 01, 2025Audio-Visual Target Speaker Extraction (AV-TSE) aims to mimic the human ability to enhance auditory perception using visual cues. Although numerous models have been proposed recently, most of them estimate target signals by primarily relying on local dependencies within acoustic features, underutilizing the human-like capacity to infer unclear parts of speech through contextual information. This limitation results in not only suboptimal performance but also inconsistent extraction quality across the utterance, with some segments exhibiting poor quality or inadequate suppression of interfering speakers. To close this gap, we propose a model-agnostic strategy called the Mask-And-Recover (MAR). It integrates both inter- and intra-modality contextual correlations to enable global inference within extraction modules. Additionally, to better target challenging parts within each sample, we introduce a Fine-grained Confidence Score (FCS) model to assess extraction quality and guide extraction modules to emphasize improvement on low-quality segments. To validate the effectiveness of our proposed model-agnostic training paradigm, six popular AV-TSE backbones were adopted for evaluation on the VoxCeleb2 dataset, demonstrating consistent performance improvements across various metrics.
Molecular Graph Contrastive Learning with Line Graph
Jan 15, 2025Trapped by the label scarcity in molecular property prediction and drug design, graph contrastive learning (GCL) came forward. Leading contrastive learning works show two kinds of view generators, that is, random or learnable data corruption and domain knowledge incorporation. While effective, the two ways also lead to molecular semantics altering and limited generalization capability, respectively. To this end, we relate the \textbf{L}in\textbf{E} graph with \textbf{MO}lecular graph co\textbf{N}trastive learning and propose a novel method termed \textit{LEMON}. Specifically, by contrasting the given graph with the corresponding line graph, the graph encoder can freely encode the molecular semantics without omission. Furthermore, we present a new patch with edge attribute fusion and two local contrastive losses enhance information transmission and tackle hard negative samples. Compared with state-of-the-art (SOTA) methods for view generation, superior performance on molecular property prediction suggests the effectiveness of our proposed framework.
A Comparative Study of Discrete Speech Tokens for Semantic-Related Tasks with Large Language Models
Nov 13, 2024
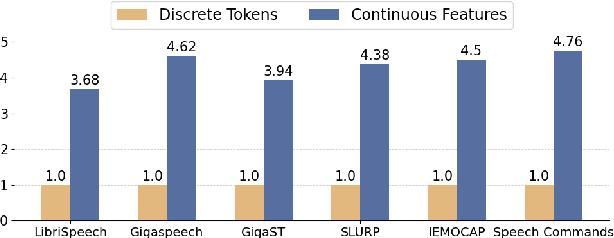


With the rise of Speech Large Language Models (Speech LLMs), there has been growing interest in discrete speech tokens for their ability to integrate with text-based tokens seamlessly. Compared to most studies that focus on continuous speech features, although discrete-token based LLMs have shown promising results on certain tasks, the performance gap between these two paradigms is rarely explored. In this paper, we present a fair and thorough comparison between discrete and continuous features across a variety of semantic-related tasks using a light-weight LLM (Qwen1.5-0.5B). Our findings reveal that continuous features generally outperform discrete tokens, particularly in tasks requiring fine-grained semantic understanding. Moreover, this study goes beyond surface-level comparison by identifying key factors behind the under-performance of discrete tokens, such as limited token granularity and inefficient information retention. To enhance the performance of discrete tokens, we explore potential aspects based on our analysis. We hope our results can offer new insights into the opportunities for advancing discrete speech tokens in Speech LLMs.
NC-NCD: Novel Class Discovery for Node Classification
Jul 25, 2024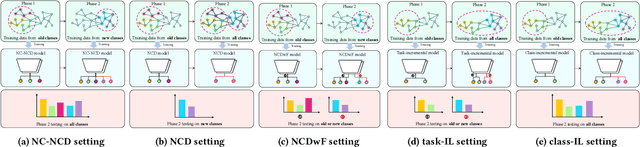

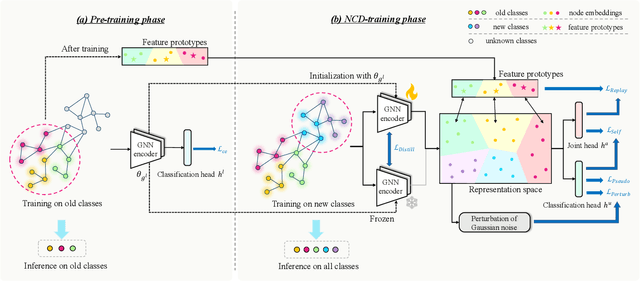
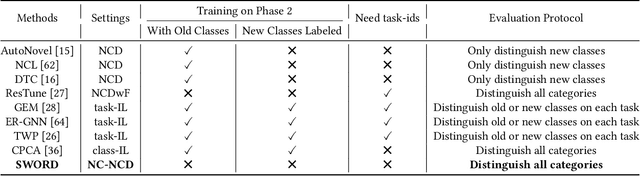
Novel Class Discovery (NCD) involves identifying new categories within unlabeled data by utilizing knowledge acquired from previously established categories. However, existing NCD methods often struggle to maintain a balance between the performance of old and new categories. Discovering unlabeled new categories in a class-incremental way is more practical but also more challenging, as it is frequently hindered by either catastrophic forgetting of old categories or an inability to learn new ones. Furthermore, the implementation of NCD on continuously scalable graph-structured data remains an under-explored area. In response to these challenges, we introduce for the first time a more practical NCD scenario for node classification (i.e., NC-NCD), and propose a novel self-training framework with prototype replay and distillation called SWORD, adopted to our NC-NCD setting. Our approach enables the model to cluster unlabeled new category nodes after learning labeled nodes while preserving performance on old categories without reliance on old category nodes. SWORD achieves this by employing a self-training strategy to learn new categories and preventing the forgetting of old categories through the joint use of feature prototypes and knowledge distillation. Extensive experiments on four common benchmarks demonstrate the superiority of SWORD over other state-of-the-art methods.
CoLM-DSR: Leveraging Neural Codec Language Modeling for Multi-Modal Dysarthric Speech Reconstruction
Jun 12, 2024



Dysarthric speech reconstruction (DSR) aims to transform dysarthric speech into normal speech. It still suffers from low speaker similarity and poor prosody naturalness. In this paper, we propose a multi-modal DSR model by leveraging neural codec language modeling to improve the reconstruction results, especially for the speaker similarity and prosody naturalness. Our proposed model consists of: (i) a multi-modal content encoder to extract robust phoneme embeddings from dysarthric speech with auxiliary visual inputs; (ii) a speaker codec encoder to extract and normalize the speaker-aware codecs from the dysarthric speech, in order to provide original timbre and normal prosody; (iii) a codec language model based speech decoder to reconstruct the speech based on the extracted phoneme embeddings and normalized codecs. Evaluations on the commonly used UASpeech corpus show that our proposed model can achieve significant improvements in terms of speaker similarity and prosody naturalness.
SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
Jun 04, 2024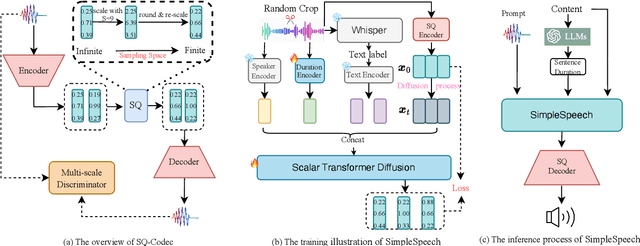
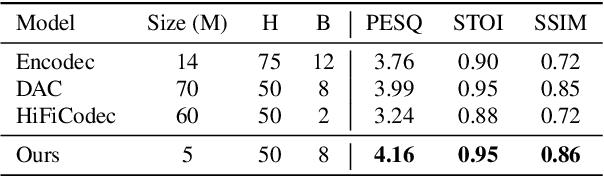
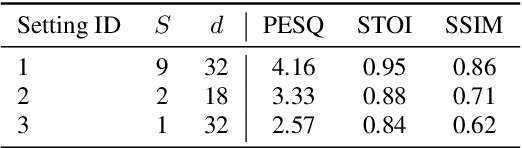

In this study, we propose a simple and efficient Non-Autoregressive (NAR) text-to-speech (TTS) system based on diffusion, named SimpleSpeech. Its simpleness shows in three aspects: (1) It can be trained on the speech-only dataset, without any alignment information; (2) It directly takes plain text as input and generates speech through an NAR way; (3) It tries to model speech in a finite and compact latent space, which alleviates the modeling difficulty of diffusion. More specifically, we propose a novel speech codec model (SQ-Codec) with scalar quantization, SQ-Codec effectively maps the complex speech signal into a finite and compact latent space, named scalar latent space. Benefits from SQ-Codec, we apply a novel transformer diffusion model in the scalar latent space of SQ-Codec. We train SimpleSpeech on 4k hours of a speech-only dataset, it shows natural prosody and voice cloning ability. Compared with previous large-scale TTS models, it presents significant speech quality and generation speed improvement. Demos are released.
Target Speech Extraction with Pre-trained AV-HuBERT and Mask-And-Recover Strategy
Mar 24, 2024Audio-visual target speech extraction (AV-TSE) is one of the enabling technologies in robotics and many audio-visual applications. One of the challenges of AV-TSE is how to effectively utilize audio-visual synchronization information in the process. AV-HuBERT can be a useful pre-trained model for lip-reading, which has not been adopted by AV-TSE. In this paper, we would like to explore the way to integrate a pre-trained AV-HuBERT into our AV-TSE system. We have good reasons to expect an improved performance. To benefit from the inter and intra-modality correlations, we also propose a novel Mask-And-Recover (MAR) strategy for self-supervised learning. The experimental results on the VoxCeleb2 dataset show that our proposed model outperforms the baselines both in terms of subjective and objective metrics, suggesting that the pre-trained AV-HuBERT model provides more informative visual cues for target speech extraction. Furthermore, through a comparative study, we confirm that the proposed Mask-And-Recover strategy is significantly effective.