 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaturalistic Language-related Movie-Watching fMRI Task for Detecting Neurocognitive Decline and Disorder
Jun 10, 2025Early detection is crucial for timely intervention aimed at preventing and slowing the progression of neurocognitive disorder (NCD), a common and significant health problem among the aging population. Recent evidence has suggested that language-related functional magnetic resonance imaging (fMRI) may be a promising approach for detecting cognitive decline and early NCD. In this paper, we proposed a novel, naturalistic language-related fMRI task for this purpose. We examined the effectiveness of this task among 97 non-demented Chinese older adults from Hong Kong. The results showed that machine-learning classification models based on fMRI features extracted from the task and demographics (age, gender, and education year) achieved an average area under the curve of 0.86 when classifying participants' cognitive status (labeled as NORMAL vs DECLINE based on their scores on a standard neurcognitive test). Feature localization revealed that the fMRI features most frequently selected by the data-driven approach came primarily from brain regions associated with language processing, such as the superior temporal gyrus, middle temporal gyrus, and right cerebellum. The study demonstrated the potential of the naturalistic language-related fMRI task for early detection of aging-related cognitive decline and NCD.
Detecting Neurocognitive Disorders through Analyses of Topic Evolution and Cross-modal Consistency in Visual-Stimulated Narratives
Jan 07, 2025



Early detection of neurocognitive disorders (NCDs) is crucial for timely intervention and disease management. Speech analysis offers a non-intrusive and scalable screening method, particularly through narrative tasks in neuropsychological assessment tools. Traditional narrative analysis often focuses on local indicators in microstructure, such as word usage and syntax. While these features provide insights into language production abilities, they often fail to capture global narrative patterns, or microstructures. Macrostructures include coherence, thematic organization, and logical progressions, reflecting essential cognitive skills potentially critical for recognizing NCDs. Addressing this gap, we propose to investigate specific cognitive and linguistic challenges by analyzing topical shifts, temporal dynamics, and the coherence of narratives over time, aiming to reveal cognitive deficits by identifying narrative impairments, and exploring their impact on communication and cognition. The investigation is based on the CU-MARVEL Rabbit Story corpus, which comprises recordings of a story-telling task from 758 older adults. We developed two approaches: the Dynamic Topic Models (DTM)-based temporal analysis to examine the evolution of topics over time, and the Text-Image Temporal Alignment Network (TITAN) to evaluate the coherence between spoken narratives and visual stimuli. DTM-based approach validated the effectiveness of dynamic topic consistency as a macrostructural metric (F1=0.61, AUC=0.78). The TITAN approach achieved the highest performance (F1=0.72, AUC=0.81), surpassing established microstructural and macrostructural feature sets. Cross-comparison and regression tasks further demonstrated the effectiveness of proposed dynamic macrostructural modeling approaches for NCD detection.
Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Sep 13, 2024



Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Large Language Model-based FMRI Encoding of Language Functions for Subjects with Neurocognitive Disorder
Jul 15, 2024Functional magnetic resonance imaging (fMRI) is essential for developing encoding models that identify functional changes in language-related brain areas of individuals with Neurocognitive Disorders (NCD). While large language model (LLM)-based fMRI encoding has shown promise, existing studies predominantly focus on healthy, young adults, overlooking older NCD populations and cognitive level correlations. This paper explores language-related functional changes in older NCD adults using LLM-based fMRI encoding and brain scores, addressing current limitations. We analyze the correlation between brain scores and cognitive scores at both whole-brain and language-related ROI levels. Our findings reveal that higher cognitive abilities correspond to better brain scores, with correlations peaking in the middle temporal gyrus. This study highlights the potential of fMRI encoding models and brain scores for detecting early functional changes in NCD patients.
Empowering Whisper as a Joint Multi-Talker and Target-Talker Speech Recognition System
Jul 13, 2024Multi-talker speech recognition and target-talker speech recognition, both involve transcription in multi-talker contexts, remain significant challenges. However, existing methods rarely attempt to simultaneously address both tasks. In this study, we propose a pioneering approach to empower Whisper, which is a speech foundation model, to tackle joint multi-talker and target-talker speech recognition tasks. Specifically, (i) we freeze Whisper and plug a Sidecar separator into its encoder to separate mixed embedding for multiple talkers; (ii) a Target Talker Identifier is introduced to identify the embedding flow of the target talker on the fly, requiring only three-second enrollment speech as a cue; (iii) soft prompt tuning for decoder is explored for better task adaptation. Our method outperforms previous methods on two- and three-talker LibriMix and LibriSpeechMix datasets for both tasks, and delivers acceptable zero-shot performance on multi-talker ASR on AishellMix Mandarin dataset.
Exploiting Audio-Visual Features with Pretrained AV-HuBERT for Multi-Modal Dysarthric Speech Reconstruction
Jan 31, 2024Dysarthric speech reconstruction (DSR) aims to transform dysarthric speech into normal speech by improving the intelligibility and naturalness. This is a challenging task especially for patients with severe dysarthria and speaking in complex, noisy acoustic environments. To address these challenges, we propose a novel multi-modal framework to utilize visual information, e.g., lip movements, in DSR as extra clues for reconstructing the highly abnormal pronunciations. The multi-modal framework consists of: (i) a multi-modal encoder to extract robust phoneme embeddings from dysarthric speech with auxiliary visual features; (ii) a variance adaptor to infer the normal phoneme duration and pitch contour from the extracted phoneme embeddings; (iii) a speaker encoder to encode the speaker's voice characteristics; and (iv) a mel-decoder to generate the reconstructed mel-spectrogram based on the extracted phoneme embeddings, prosodic features and speaker embeddings. Both objective and subjective evaluations conducted on the commonly used UASpeech corpus show that our proposed approach can achieve significant improvements over baseline systems in terms of speech intelligibility and naturalness, especially for the speakers with more severe symptoms. Compared with original dysarthric speech, the reconstructed speech achieves 42.1\% absolute word error rate reduction for patients with more severe dysarthria levels.
UNIT-DSR: Dysarthric Speech Reconstruction System Using Speech Unit Normalization
Jan 26, 2024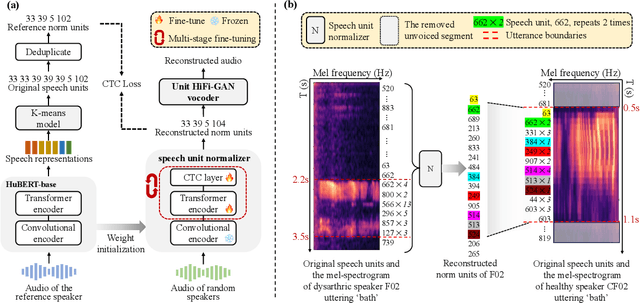

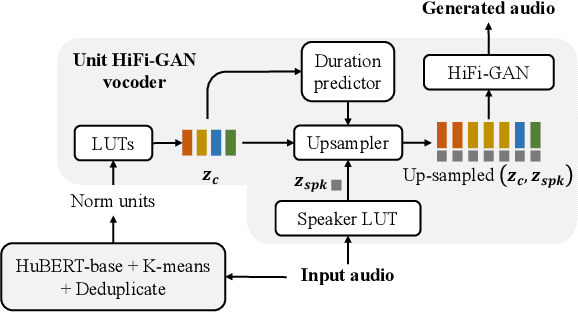
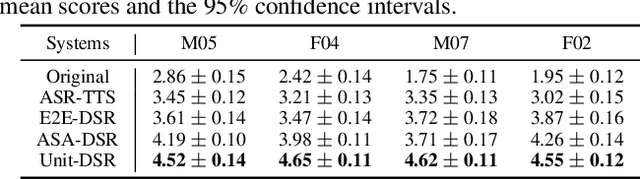
Dysarthric speech reconstruction (DSR) systems aim to automatically convert dysarthric speech into normal-sounding speech. The technology eases communication with speakers affected by the neuromotor disorder and enhances their social inclusion. NED-based (Neural Encoder-Decoder) systems have significantly improved the intelligibility of the reconstructed speech as compared with GAN-based (Generative Adversarial Network) approaches, but the approach is still limited by training inefficiency caused by the cascaded pipeline and auxiliary tasks of the content encoder, which may in turn affect the quality of reconstruction. Inspired by self-supervised speech representation learning and discrete speech units, we propose a Unit-DSR system, which harnesses the powerful domain-adaptation capacity of HuBERT for training efficiency improvement and utilizes speech units to constrain the dysarthric content restoration in a discrete linguistic space. Compared with NED approaches, the Unit-DSR system only consists of a speech unit normalizer and a Unit HiFi-GAN vocoder, which is considerably simpler without cascaded sub-modules or auxiliary tasks. Results on the UASpeech corpus indicate that Unit-DSR outperforms competitive baselines in terms of content restoration, reaching a 28.2% relative average word error rate reduction when compared to original dysarthric speech, and shows robustness against speed perturbation and noise.
A Sidecar Separator Can Convert a Single-Talker Speech Recognition System to a Multi-Talker One
Mar 05, 2023Although automatic speech recognition (ASR) can perform well in common non-overlapping environments, sustaining performance in multi-talker overlapping speech recognition remains challenging. Recent research revealed that ASR model's encoder captures different levels of information with different layers -- the lower layers tend to have more acoustic information, and the upper layers more linguistic. This inspires us to develop a Sidecar separator to empower a well-trained ASR model for multi-talker scenarios by separating the mixed speech embedding between two suitable layers. We experimented with a wav2vec 2.0-based ASR model with a Sidecar mounted. By freezing the parameters of the original model and training only the Sidecar (8.7 M, 8.4% of all parameters), the proposed approach outperforms the previous state-of-the-art by a large margin for the 2-speaker mixed LibriMix dataset, reaching a word error rate (WER) of 10.36%; and obtains comparable results (7.56%) for LibriSpeechMix dataset when limited training.