 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic IDs for Recommender Systems at Snapchat: Use Cases, Technical Challenges, and Design Choices
Apr 05, 2026Effective item identifiers (IDs) are an important component for recommender systems (RecSys) in practice, and are commonly adopted in many use cases such as retrieval and ranking. IDs can encode collaborative filtering signals within training data, such that RecSys models can extrapolate during the inference and personalize the prediction based on users' behavioral histories. Recently, Semantic IDs (SIDs) have become a trending paradigm for RecSys. In comparison to the conventional atomic ID, an SID is an ordered list of codes, derived from tokenizers such as residual quantization, applied to semantic representations commonly extracted from foundation models or collaborative signals. SIDs have drastically smaller cardinality than the atomic counterpart, and induce semantic clustering in the ID space. At Snapchat, we apply SIDs as auxiliary features for ranking models, and also explore SIDs as additional retrieval sources in different ML applications. In this paper, we discuss practical technical challenges we encountered while applying SIDs, experiments we have conducted, and design choices we have iterated to mitigate these challenges. Backed by promising offline results on both internal data and academic benchmarks as well as online A/B studies, SID variants have been launched in multiple production models with positive metrics impact.
Agentic Cognitive Profiling: Realigning Automated Alzheimer's Disease Detection with Clinical Construct Validity
Mar 18, 2026Automated Alzheimer's Disease (AD) screening has predominantly followed the inductive paradigm of pattern recognition, which directly maps the input signal to the outcome label. This paradigm sacrifices construct validity of clinical protocol for statistical shortcuts. This paper proposes Agentic Cognitive Profiling (ACP), an agentic framework that realigns automated screening with clinical protocol logic across multiple cognitive domains. Rather than learning opaque mappings from transcripts to labels, the framework decomposes standardized assessments into atomic cognitive tasks and orchestrates specialized LLM agents to extract verifiable scoring primitives. Central to our design is decoupling semantic understanding from measurement by delegating all quantification to deterministic function calling, thereby mitigating hallucination and restoring construct validity. Unlike popular datasets that typically comprise around a hundred participants under a single task, we evaluate on a clinically-annotated corpus of 402 participants across eight structured cognitive tasks spanning multiple cognitive domains. The framework achieves 90.5% score match rate in task examination and 85.3% accuracy in AD prediction, surpassing popular baselines while generating interpretable cognitive profiles grounded in behavioral evidence. This work demonstrates that construct validity and predictive performance need not be traded off, charting a path toward AD screening systems that explain rather than merely predict.
Detecting Neurocognitive Disorders through Analyses of Topic Evolution and Cross-modal Consistency in Visual-Stimulated Narratives
Jan 07, 2025



Early detection of neurocognitive disorders (NCDs) is crucial for timely intervention and disease management. Speech analysis offers a non-intrusive and scalable screening method, particularly through narrative tasks in neuropsychological assessment tools. Traditional narrative analysis often focuses on local indicators in microstructure, such as word usage and syntax. While these features provide insights into language production abilities, they often fail to capture global narrative patterns, or microstructures. Macrostructures include coherence, thematic organization, and logical progressions, reflecting essential cognitive skills potentially critical for recognizing NCDs. Addressing this gap, we propose to investigate specific cognitive and linguistic challenges by analyzing topical shifts, temporal dynamics, and the coherence of narratives over time, aiming to reveal cognitive deficits by identifying narrative impairments, and exploring their impact on communication and cognition. The investigation is based on the CU-MARVEL Rabbit Story corpus, which comprises recordings of a story-telling task from 758 older adults. We developed two approaches: the Dynamic Topic Models (DTM)-based temporal analysis to examine the evolution of topics over time, and the Text-Image Temporal Alignment Network (TITAN) to evaluate the coherence between spoken narratives and visual stimuli. DTM-based approach validated the effectiveness of dynamic topic consistency as a macrostructural metric (F1=0.61, AUC=0.78). The TITAN approach achieved the highest performance (F1=0.72, AUC=0.81), surpassing established microstructural and macrostructural feature sets. Cross-comparison and regression tasks further demonstrated the effectiveness of proposed dynamic macrostructural modeling approaches for NCD detection.
Not All Errors Are Equal: Investigation of Speech Recognition Errors in Alzheimer's Disease Detection
Dec 09, 2024Automatic Speech Recognition (ASR) plays an important role in speech-based automatic detection of Alzheimer's disease (AD). However, recognition errors could propagate downstream, potentially impacting the detection decisions. Recent studies have revealed a non-linear relationship between word error rates (WER) and AD detection performance, where ASR transcriptions with notable errors could still yield AD detection accuracy equivalent to that based on manual transcriptions. This work presents a series of analyses to explore the effect of ASR transcription errors in BERT-based AD detection systems. Our investigation reveals that not all ASR errors contribute equally to detection performance. Certain words, such as stopwords, despite constituting a large proportion of errors, are shown to play a limited role in distinguishing AD. In contrast, the keywords related to diagnosis tasks exhibit significantly greater importance relative to other words. These findings provide insights into the interplay between ASR errors and the downstream detection model.
Towards Within-Class Variation in Alzheimer's Disease Detection from Spontaneous Speech
Sep 22, 2024



Alzheimer's Disease (AD) detection has emerged as a promising research area that employs machine learning classification models to distinguish between individuals with AD and those without. Unlike conventional classification tasks, we identify within-class variation as a critical challenge in AD detection: individuals with AD exhibit a spectrum of cognitive impairments. Given that many AD detection tasks lack fine-grained labels, simplistic binary classification may overlook two crucial aspects: within-class differences and instance-level imbalance. The former compels the model to map AD samples with varying degrees of impairment to a single diagnostic label, disregarding certain changes in cognitive function. While the latter biases the model towards overrepresented severity levels. This work presents early efforts to address these challenges. We propose two novel methods: Soft Target Distillation (SoTD) and Instance-level Re-balancing (InRe), targeting two problems respectively. Experiments on the ADReSS and ADReSSo datasets demonstrate that the proposed methods significantly improve detection accuracy. Further analysis reveals that SoTD effectively harnesses the strengths of multiple component models, while InRe substantially alleviates model over-fitting. These findings provide insights for developing more robust and reliable AD detection models.
emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation
Dec 23, 2023



We propose emotion2vec, a universal speech emotion representation model. emotion2vec is pre-trained on open-source unlabeled emotion data through self-supervised online distillation, combining utterance-level loss and frame-level loss during pre-training. emotion2vec outperforms state-of-the-art pre-trained universal models and emotion specialist models by only training linear layers for the speech emotion recognition task on the mainstream IEMOCAP dataset. In addition, emotion2vec shows consistent improvements among 10 different languages of speech emotion recognition datasets. emotion2vec also shows excellent results on other emotion tasks, such as song emotion recognition, emotion prediction in conversation, and sentiment analysis. Comparison experiments, ablation experiments, and visualization comprehensively demonstrate the universal capability of the proposed emotion2vec. To the best of our knowledge, emotion2vec is the first universal representation model in various emotion-related tasks, filling a gap in the field.
Resprompt: Residual Connection Prompting Advances Multi-Step Reasoning in Large Language Models
Oct 07, 2023Chain-of-thought (CoT) prompting, which offers step-by-step problem-solving rationales, has impressively unlocked the reasoning potential of large language models (LLMs). Yet, the standard CoT is less effective in problems demanding multiple reasoning steps. This limitation arises from the complex reasoning process in multi-step problems: later stages often depend on the results of several steps earlier, not just the results of the immediately preceding step. Such complexities suggest the reasoning process is naturally represented as a graph. The almost linear and straightforward structure of CoT prompting, however, struggles to capture this complex reasoning graph. To address this challenge, we propose Residual Connection Prompting (RESPROMPT), a new prompting strategy that advances multi-step reasoning in LLMs. Our key idea is to reconstruct the reasoning graph within prompts. We achieve this by integrating necessary connections-links present in the reasoning graph but missing in the linear CoT flow-into the prompts. Termed "residual connections", these links are pivotal in morphing the linear CoT structure into a graph representation, effectively capturing the complex reasoning graphs inherent in multi-step problems. We evaluate RESPROMPT on six benchmarks across three diverse domains: math, sequential, and commonsense reasoning. For the open-sourced LLaMA family of models, RESPROMPT yields a significant average reasoning accuracy improvement of 12.5% on LLaMA-65B and 6.8% on LLaMA2-70B. Breakdown analysis further highlights RESPROMPT particularly excels in complex multi-step reasoning: for questions demanding at least five reasoning steps, RESPROMPT outperforms the best CoT based benchmarks by a remarkable average improvement of 21.1% on LLaMA-65B and 14.3% on LLaMA2-70B. Through extensive ablation studies and analyses, we pinpoint how to most effectively build residual connections.
Leveraging Pretrained Representations with Task-related Keywords for Alzheimer's Disease Detection
Mar 14, 2023With the global population aging rapidly, Alzheimer's disease (AD) is particularly prominent in older adults, which has an insidious onset and leads to a gradual, irreversible deterioration in cognitive domains (memory, communication, etc.). Speech-based AD detection opens up the possibility of widespread screening and timely disease intervention. Recent advances in pre-trained models motivate AD detection modeling to shift from low-level features to high-level representations. This paper presents several efficient methods to extract better AD-related cues from high-level acoustic and linguistic features. Based on these features, the paper also proposes a novel task-oriented approach by modeling the relationship between the participants' description and the cognitive task. Experiments are carried out on the ADReSS dataset in a binary classification setup, and models are evaluated on the unseen test set. Results and comparison with recent literature demonstrate the efficiency and superior performance of proposed acoustic, linguistic and task-oriented methods. The findings also show the importance of semantic and syntactic information, and feasibility of automation and generalization with the promising audio-only and task-oriented methods for the AD detection task.
A Hierarchical Regression Chain Framework for Affective Vocal Burst Recognition
Mar 14, 2023



As a common way of emotion signaling via non-linguistic vocalizations, vocal burst (VB) plays an important role in daily social interaction. Understanding and modeling human vocal bursts are indispensable for developing robust and general artificial intelligence. Exploring computational approaches for understanding vocal bursts is attracting increasing research attention. In this work, we propose a hierarchical framework, based on chain regression models, for affective recognition from VBs, that explicitly considers multiple relationships: (i) between emotional states and diverse cultures; (ii) between low-dimensional (arousal & valence) and high-dimensional (10 emotion classes) emotion spaces; and (iii) between various emotion classes within the high-dimensional space. To address the challenge of data sparsity, we also use self-supervised learning (SSL) representations with layer-wise and temporal aggregation modules. The proposed systems participated in the ACII Affective Vocal Burst (A-VB) Challenge 2022 and ranked first in the "TWO'' and "CULTURE'' tasks. Experimental results based on the ACII Challenge 2022 dataset demonstrate the superior performance of the proposed system and the effectiveness of considering multiple relationships using hierarchical regression chain models.
Spoofing-Aware Speaker Verification by Multi-Level Fusion
Mar 29, 2022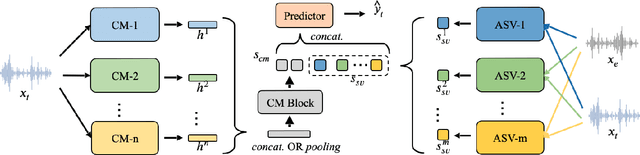
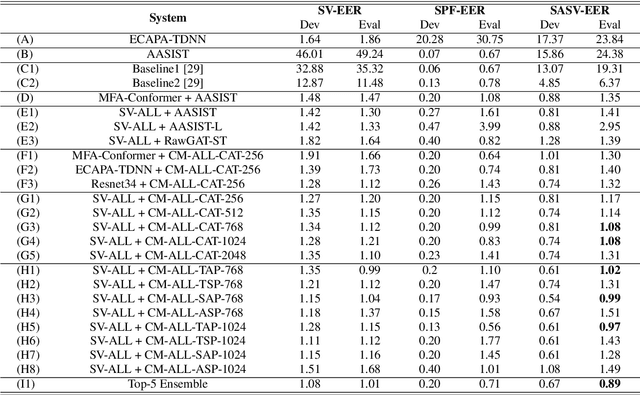
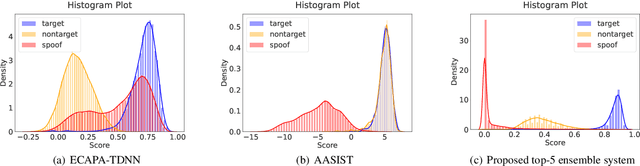
Recently, many novel techniques have been introduced to deal with spoofing attacks, and achieve promising countermeasure (CM) performances. However, these works only take the stand-alone CM models into account. Nowadays, a spoofing aware speaker verification (SASV) challenge which aims to facilitate the research of integrated CM and ASV models, arguing that jointly optimizing CM and ASV models will lead to better performance, is taking place. In this paper, we propose a novel multi-model and multi-level fusion strategy to tackle the SASV task. Compared with purely scoring fusion and embedding fusion methods, this framework first utilizes embeddings from CM models, propagating CM embeddings into a CM block to obtain a CM score. In the second-level fusion, the CM score and ASV scores directly from ASV systems will be concatenated into a prediction block for the final decision. As a result, the best single fusion system has achieved the SASV-EER of 0.97% on the evaluation set. Then by ensembling the top-5 fusion systems, the final SASV-EER reached 0.89%.