 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixelGen: Pixel Diffusion Beats Latent Diffusion with Perceptual Loss
Feb 02, 2026Pixel diffusion generates images directly in pixel space in an end-to-end manner, avoiding the artifacts and bottlenecks introduced by VAEs in two-stage latent diffusion. However, it is challenging to optimize high-dimensional pixel manifolds that contain many perceptually irrelevant signals, leaving existing pixel diffusion methods lagging behind latent diffusion models. We propose PixelGen, a simple pixel diffusion framework with perceptual supervision. Instead of modeling the full image manifold, PixelGen introduces two complementary perceptual losses to guide diffusion model towards learning a more meaningful perceptual manifold. An LPIPS loss facilitates learning better local patterns, while a DINO-based perceptual loss strengthens global semantics. With perceptual supervision, PixelGen surpasses strong latent diffusion baselines. It achieves an FID of 5.11 on ImageNet-256 without classifier-free guidance using only 80 training epochs, and demonstrates favorable scaling performance on large-scale text-to-image generation with a GenEval score of 0.79. PixelGen requires no VAEs, no latent representations, and no auxiliary stages, providing a simpler yet more powerful generative paradigm. Codes are publicly available at https://github.com/Zehong-Ma/PixelGen.
SLAM-LLM: A Modular, Open-Source Multimodal Large Language Model Framework and Best Practice for Speech, Language, Audio and Music Processing
Jan 14, 2026The recent surge in open-source Multimodal Large Language Models (MLLM) frameworks, such as LLaVA, provides a convenient kickoff for artificial intelligence developers and researchers. However, most of the MLLM frameworks take vision as the main input modality, and provide limited in-depth support for the modality of speech, audio, and music. This situation hinders the development of audio-language models, and forces researchers to spend a lot of effort on code writing and hyperparameter tuning. We present SLAM-LLM, an open-source deep learning framework designed to train customized MLLMs, focused on speech, language, audio, and music processing. SLAM-LLM provides a modular configuration of different encoders, projectors, LLMs, and parameter-efficient fine-tuning plugins. SLAM-LLM also includes detailed training and inference recipes for mainstream tasks, along with high-performance checkpoints like LLM-based Automatic Speech Recognition (ASR), Automated Audio Captioning (AAC), and Music Captioning (MC). Some of these recipes have already reached or are nearing state-of-the-art performance, and some relevant techniques have also been accepted by academic papers. We hope SLAM-LLM will accelerate iteration, development, data engineering, and model training for researchers. We are committed to continually pushing forward audio-based MLLMs through this open-source framework, and call on the community to contribute to the LLM-based speech, audio and music processing.
MoCo: Motion-Consistent Human Video Generation via Structure-Appearance Decoupling
Aug 24, 2025Generating human videos with consistent motion from text prompts remains a significant challenge, particularly for whole-body or long-range motion. Existing video generation models prioritize appearance fidelity, resulting in unrealistic or physically implausible human movements with poor structural coherence. Additionally, most existing human video datasets primarily focus on facial or upper-body motions, or consist of vertically oriented dance videos, limiting the scope of corresponding generation methods to simple movements. To overcome these challenges, we propose MoCo, which decouples the process of human video generation into two components: structure generation and appearance generation. Specifically, our method first employs an efficient 3D structure generator to produce a human motion sequence from a text prompt. The remaining video appearance is then synthesized under the guidance of the generated structural sequence. To improve fine-grained control over sparse human structures, we introduce Human-Aware Dynamic Control modules and integrate dense tracking constraints during training. Furthermore, recognizing the limitations of existing datasets, we construct a large-scale whole-body human video dataset featuring complex and diverse motions. Extensive experiments demonstrate that MoCo outperforms existing approaches in generating realistic and structurally coherent human videos.
NN-Former: Rethinking Graph Structure in Neural Architecture Representation
Jul 01, 2025
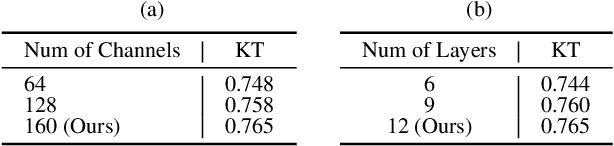
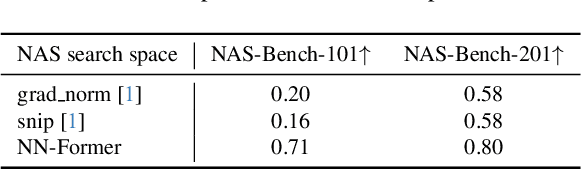
The growing use of deep learning necessitates efficient network design and deployment, making neural predictors vital for estimating attributes such as accuracy and latency. Recently, Graph Neural Networks (GNNs) and transformers have shown promising performance in representing neural architectures. However, each of both methods has its disadvantages. GNNs lack the capabilities to represent complicated features, while transformers face poor generalization when the depth of architecture grows. To mitigate the above issues, we rethink neural architecture topology and show that sibling nodes are pivotal while overlooked in previous research. We thus propose a novel predictor leveraging the strengths of GNNs and transformers to learn the enhanced topology. We introduce a novel token mixer that considers siblings, and a new channel mixer named bidirectional graph isomorphism feed-forward network. Our approach consistently achieves promising performance in both accuracy and latency prediction, providing valuable insights for learning Directed Acyclic Graph (DAG) topology. The code is available at https://github.com/XuRuihan/NNFormer.
MagCache: Fast Video Generation with Magnitude-Aware Cache
Jun 10, 2025Existing acceleration techniques for video diffusion models often rely on uniform heuristics or time-embedding variants to skip timesteps and reuse cached features. These approaches typically require extensive calibration with curated prompts and risk inconsistent outputs due to prompt-specific overfitting. In this paper, we introduce a novel and robust discovery: a unified magnitude law observed across different models and prompts. Specifically, the magnitude ratio of successive residual outputs decreases monotonically and steadily in most timesteps while rapidly in the last several steps. Leveraging this insight, we introduce a Magnitude-aware Cache (MagCache) that adaptively skips unimportant timesteps using an error modeling mechanism and adaptive caching strategy. Unlike existing methods requiring dozens of curated samples for calibration, MagCache only requires a single sample for calibration. Experimental results show that MagCache achieves 2.1x and 2.68x speedups on Open-Sora and Wan 2.1, respectively, while preserving superior visual fidelity. It significantly outperforms existing methods in LPIPS, SSIM, and PSNR, under comparable computational budgets.
Efficient Multi-modal Long Context Learning for Training-free Adaptation
May 26, 2025Traditional approaches to adapting multi-modal large language models (MLLMs) to new tasks have relied heavily on fine-tuning. This paper introduces Efficient Multi-Modal Long Context Learning (EMLoC), a novel training-free alternative that embeds demonstration examples directly into the model input. EMLoC offers a more efficient, flexible, and scalable solution for task adaptation. Because extremely lengthy inputs introduce prohibitive computational and memory overhead, EMLoC contributes a chunk-wise compression mechanism combined with layer-wise adaptive pruning. It condenses long-context multimodal inputs into compact, task-specific memory representations. By adaptively pruning tokens at each layer under a Jensen-Shannon divergence constraint, our method achieves a dramatic reduction in inference complexity without sacrificing performance. This approach is the first to seamlessly integrate compression and pruning techniques for multi-modal long-context learning, offering a scalable and efficient solution for real-world applications. Extensive experiments on diverse vision-language benchmarks demonstrate that EMLoC achieves performance on par with or superior to naive long-context approaches. Our results highlight the potential of EMLoC as a groundbreaking framework for efficient and flexible adaptation of multi-modal models in resource-constrained environments. Codes are publicly available at https://github.com/Zehong-Ma/EMLoC.
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
May 23, 2025In our prior works, we introduced a scalable streaming speech synthesis model, CosyVoice 2, which integrates a large language model (LLM) and a chunk-aware flow matching (FM) model, and achieves low-latency bi-streaming speech synthesis and human-parity quality. Despite these advancements, CosyVoice 2 exhibits limitations in language coverage, domain diversity, data volume, text formats, and post-training techniques. In this paper, we present CosyVoice 3, an improved model designed for zero-shot multilingual speech synthesis in the wild, surpassing its predecessor in content consistency, speaker similarity, and prosody naturalness. Key features of CosyVoice 3 include: 1) A novel speech tokenizer to improve prosody naturalness, developed via supervised multi-task training, including automatic speech recognition, speech emotion recognition, language identification, audio event detection, and speaker analysis. 2) A new differentiable reward model for post-training applicable not only to CosyVoice 3 but also to other LLM-based speech synthesis models. 3) Dataset Size Scaling: Training data is expanded from ten thousand hours to one million hours, encompassing 9 languages and 18 Chinese dialects across various domains and text formats. 4) Model Size Scaling: Model parameters are increased from 0.5 billion to 1.5 billion, resulting in enhanced performance on our multilingual benchmark due to the larger model capacity. These advancements contribute significantly to the progress of speech synthesis in the wild. We encourage readers to listen to the demo at https://funaudiollm.github.io/cosyvoice3.
Adaptive Fault-tolerant Control of Underwater Vehicles with Thruster Failures
Apr 22, 2025
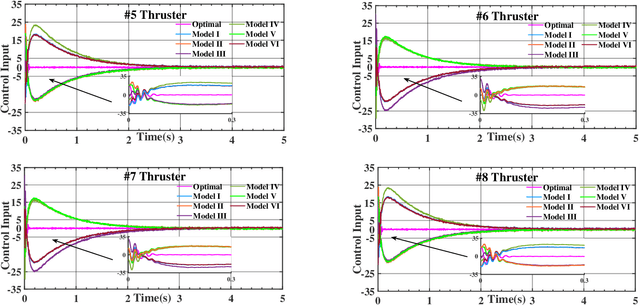
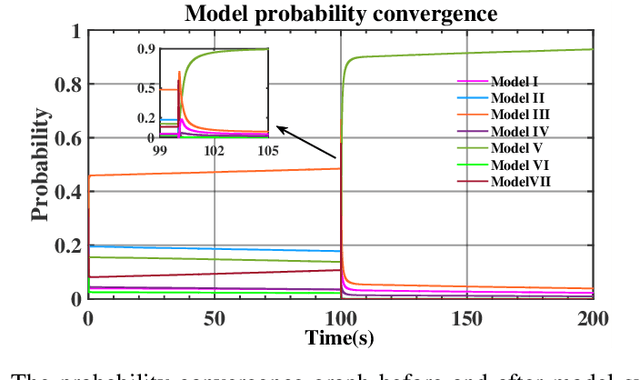
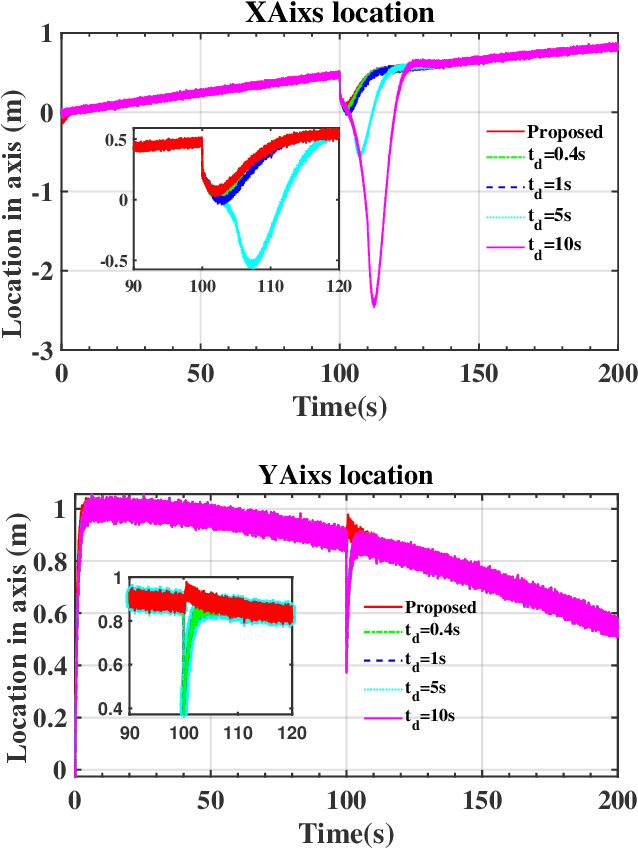
This paper presents a fault-tolerant control for the trajectory tracking of autonomous underwater vehicles (AUVs) against thruster failures. We formulate faults in AUV thrusters as discrete switching events during a UAV mission, and develop a soft-switching approach in facilitating shift of control strategies across fault scenarios. We mathematically define AUV thruster fault scenarios, and develop the fault-tolerant control that captures the fault scenario via Bayesian approach. Particularly, when the AUV fault type switches from one to another, the developed control captures the fault states and maintains the control by a linear quadratic tracking controller. With the captured fault states by Bayesian approach, we derive the control law by aggregating the control outputs for individual fault scenarios weighted by their Bayesian posterior probability. The developed fault-tolerant control works in an adaptive way and guarantees soft-switching across fault scenarios, and requires no complicated fault detection dedicated to different type of faults. The entailed soft-switching ensures stable AUV trajectory tracking when fault type shifts, which otherwise leads to reduced control under hard-switching control strategies. We conduct numerical simulations with diverse AUV thruster fault settings. The results demonstrate that the proposed control can provide smooth transition across thruster failures, and effectively sustain AUV trajectory tracking control in case of thruster failures and failure shifts.
OmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025
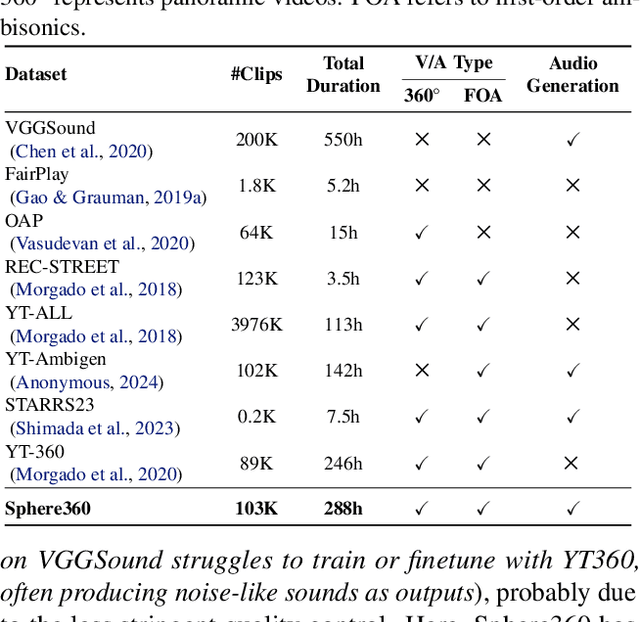
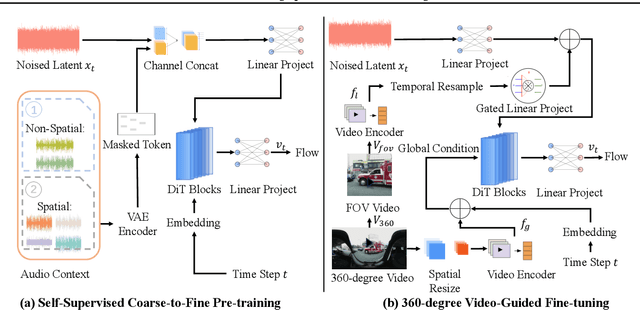
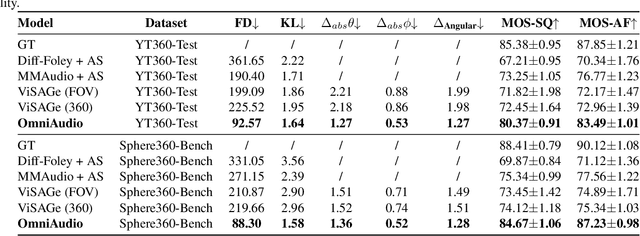
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
Evolved Hierarchical Masking for Self-Supervised Learning
Apr 12, 2025Existing Masked Image Modeling methods apply fixed mask patterns to guide the self-supervised training. As those mask patterns resort to different criteria to depict image contents, sticking to a fixed pattern leads to a limited vision cues modeling capability.This paper introduces an evolved hierarchical masking method to pursue general visual cues modeling in self-supervised learning. The proposed method leverages the vision model being trained to parse the input visual cues into a hierarchy structure, which is hence adopted to generate masks accordingly. The accuracy of hierarchy is on par with the capability of the model being trained, leading to evolved mask patterns at different training stages. Initially, generated masks focus on low-level visual cues to grasp basic textures, then gradually evolve to depict higher-level cues to reinforce the learning of more complicated object semantics and contexts. Our method does not require extra pre-trained models or annotations and ensures training efficiency by evolving the training difficulty. We conduct extensive experiments on seven downstream tasks including partial-duplicate image retrieval relying on low-level details, as well as image classification and semantic segmentation that require semantic parsing capability. Experimental results demonstrate that it substantially boosts performance across these tasks. For instance, it surpasses the recent MAE by 1.1\% in imageNet-1K classification and 1.4\% in ADE20K segmentation with the same training epochs. We also align the proposed method with the current research focus on LLMs. The proposed approach bridges the gap with large-scale pre-training on semantic demanding tasks and enhances intricate detail perception in tasks requiring low-level feature recognition.