 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Keyboard: An improved Bayesian design for phase I clinical trials via Beta kernel process
May 24, 2026Model-assisted interval designs such as the Keyboard design are transparent and easy to implement in phase I oncology trials. However, interim decisions based solely on data from the current dose may overlook informative signals from neighbouring doses, leading to unnecessary escalation or de-escalation. We propose the shared Keyboard design, a Bayesian model-assisted design that replaces the independent beta--binomial updating scheme at each dose with a posterior induced by a Beta kernel process using kernel-weighted pseudo-counts. The design preserves the decision structure of the Keyboard design while enabling controlled borrowing across nearby doses. To prioritise overdose control, we propose an asymmetric kernel that assigns greater weight to toxicities observed at higher doses during escalation. We further extend the proposed design to accommodate adaptive dose insertion when the initial dose grid is inadequate and time-to-event outcomes when late-onset toxicities are present. Extensive simulation studies demonstrate substantial improvements in both accuracy and safety for identifying the maximum tolerated dose. In settings involving dose insertion, the proposed design identifies inserted target doses more effectively than adaptive dose modification while maintaining a comparable modification rate.
Semantic-Aware Interruption Detection in Spoken Dialogue Systems: Benchmark, Metric, and Model
Mar 25, 2026Achieving natural full-duplex interaction in spoken dialogue systems (SDS) remains a challenge due to the difficulty of accurately detecting user interruptions. Current solutions are polarized between "trigger-happy" VAD-based methods that misinterpret backchannels and robust end-to-end models that exhibit unacceptable response delays. Moreover, the absence of real-world benchmarks and holistic metrics hinders progress in the field. This paper presents a comprehensive frame-work to overcome these limitations. We first introduce SID-Bench, the first benchmark for semantic-aware interruption detection built entirely from real-world human dialogues. To provide a rigorous assessment of the responsiveness-robustness trade-off, we propose the Average Penalty Time (APT) metric, which assigns a temporal cost to both false alarms and late responses. Building on this framework, we design an LLM-based detection model optimized through a novel training paradigm to capture subtle semantic cues of intent. Experimental results show that our model significantly outperforms mainstream baselines, achieving a nearly threefold reduction in APT. By successfully resolving the long-standing tension between speed and stability, our work establishes a new state-of-the-art for intelligent interruption handling in SDS. To facilitate future research, SID-Bench and the associated code are available at: https://github.com/xkx-hub/SID-bench.
Qwen3-ASR Technical Report
Jan 29, 2026In this report, we introduce Qwen3-ASR family, which includes two powerful all-in-one speech recognition models and a novel non-autoregressive speech forced alignment model. Qwen3-ASR-1.7B and Qwen3-ASR-0.6B are ASR models that support language identification and ASR for 52 languages and dialects. Both of them leverage large-scale speech training data and the strong audio understanding ability of their foundation model Qwen3-Omni. We conduct comprehensive internal evaluation besides the open-sourced benchmarks as ASR models might differ little on open-sourced benchmark scores but exhibit significant quality differences in real-world scenarios. The experiments reveal that the 1.7B version achieves SOTA performance among open-sourced ASR models and is competitive with the strongest proprietary APIs while the 0.6B version offers the best accuracy-efficiency trade-off. Qwen3-ASR-0.6B can achieve an average TTFT as low as 92ms and transcribe 2000 seconds speech in 1 second at a concurrency of 128. Qwen3-ForcedAligner-0.6B is an LLM based NAR timestamp predictor that is able to align text-speech pairs in 11 languages. Timestamp accuracy experiments show that the proposed model outperforms the three strongest force alignment models and takes more advantages in efficiency and versatility. To further accelerate the community research of ASR and audio understanding, we release these models under the Apache 2.0 license.
LLM-ForcedAligner: A Non-Autoregressive and Accurate LLM-Based Forced Aligner for Multilingual and Long-Form Speech
Jan 26, 2026Forced alignment (FA) predicts start and end timestamps for words or characters in speech, but existing methods are language-specific and prone to cumulative temporal shifts. The multilingual speech understanding and long-sequence processing abilities of speech large language models (SLLMs) make them promising for FA in multilingual, crosslingual, and long-form speech settings. However, directly applying the next-token prediction paradigm of SLLMs to FA results in hallucinations and slow inference. To bridge the gap, we propose LLM-ForcedAligner, reformulating FA as a slot-filling paradigm: timestamps are treated as discrete indices, and special timestamp tokens are inserted as slots into the transcript. Conditioned on the speech embeddings and the transcript with slots, the SLLM directly predicts the time indices at slots. During training, causal attention masking with non-shifted input and label sequences allows each slot to predict its own timestamp index based on itself and preceding context, with loss computed only at slot positions. Dynamic slot insertion enables FA at arbitrary positions. Moreover, non-autoregressive inference is supported, avoiding hallucinations and improving speed. Experiments across multilingual, crosslingual, and long-form speech scenarios show that LLM-ForcedAligner achieves a 69%~78% relative reduction in accumulated averaging shift compared with prior methods. The checkpoint and inference code will be released later.
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
May 23, 2025In our prior works, we introduced a scalable streaming speech synthesis model, CosyVoice 2, which integrates a large language model (LLM) and a chunk-aware flow matching (FM) model, and achieves low-latency bi-streaming speech synthesis and human-parity quality. Despite these advancements, CosyVoice 2 exhibits limitations in language coverage, domain diversity, data volume, text formats, and post-training techniques. In this paper, we present CosyVoice 3, an improved model designed for zero-shot multilingual speech synthesis in the wild, surpassing its predecessor in content consistency, speaker similarity, and prosody naturalness. Key features of CosyVoice 3 include: 1) A novel speech tokenizer to improve prosody naturalness, developed via supervised multi-task training, including automatic speech recognition, speech emotion recognition, language identification, audio event detection, and speaker analysis. 2) A new differentiable reward model for post-training applicable not only to CosyVoice 3 but also to other LLM-based speech synthesis models. 3) Dataset Size Scaling: Training data is expanded from ten thousand hours to one million hours, encompassing 9 languages and 18 Chinese dialects across various domains and text formats. 4) Model Size Scaling: Model parameters are increased from 0.5 billion to 1.5 billion, resulting in enhanced performance on our multilingual benchmark due to the larger model capacity. These advancements contribute significantly to the progress of speech synthesis in the wild. We encourage readers to listen to the demo at https://funaudiollm.github.io/cosyvoice3.
ThermoONet -- a deep learning-based small body thermophysical network: applications to modelling water activity of comets
May 20, 2025Cometary activity is a compelling subject of study, with thermophysical models playing a pivotal role in its understanding. However, traditional numerical solutions for small body thermophysical models are computationally intensive, posing challenges for investigations requiring high-resolution or repetitive modeling. To address this limitation, we employed a machine learning approach to develop ThermoONet - a neural network designed to predict the temperature and water ice sublimation flux of comets. Performance evaluations indicate that ThermoONet achieves a low average error in subsurface temperature of approximately 2% relative to the numerical simulation, while reducing computational time by nearly six orders of magnitude. We applied ThermoONet to model the water activity of comets 67P/Churyumov-Gerasimenko and 21P/Giacobini-Zinner. By successfully fitting the water production rate curves of these comets, as obtained by the Rosetta mission and the SOHO telescope, respectively, we demonstrate the network's effectiveness and efficiency. Furthermore, when combined with a global optimization algorithm, ThermoONet proves capable of retrieving the physical properties of target bodies.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Dec 13, 2024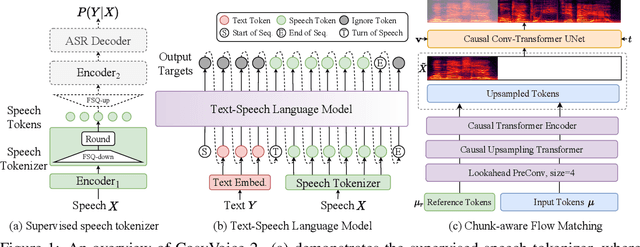

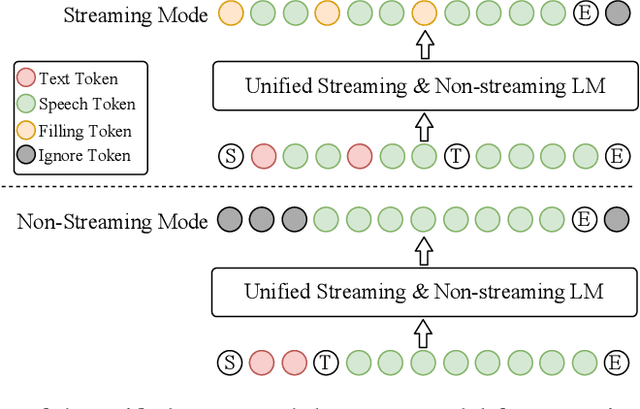

In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
Deep operator neural network applied to efficient computation of asteroid surface temperature and the Yarkovsky effect
Nov 04, 2024



Surface temperature distribution is crucial for thermal property-based studies about irregular asteroids in our Solar System. While direct numerical simulations could model surface temperatures with high fidelity, they often take a significant amount of computational time, especially for problems where temperature distributions are required to be repeatedly calculated. To this end, deep operator neural network (DeepONet) provides a powerful tool due to its high computational efficiency and generalization ability. In this work, we applied DeepONet to the modelling of asteroid surface temperatures. Results show that the trained network is able to predict temperature with an accuracy of ~1% on average, while the computational cost is five orders of magnitude lower, hence enabling thermal property analysis in a multidimensional parameter space. As a preliminary application, we analyzed the orbital evolution of asteroids through direct N-body simulations embedded with instantaneous Yarkovsky effect inferred by DeepONet-based thermophysical modelling.Taking asteroids (3200) Phaethon and (89433) 2001 WM41 as examples, we show the efficacy and efficiency of our AI-based approach.
LCB-net: Long-Context Biasing for Audio-Visual Speech Recognition
Jan 12, 2024The growing prevalence of online conferences and courses presents a new challenge in improving automatic speech recognition (ASR) with enriched textual information from video slides. In contrast to rare phrase lists, the slides within videos are synchronized in real-time with the speech, enabling the extraction of long contextual bias. Therefore, we propose a novel long-context biasing network (LCB-net) for audio-visual speech recognition (AVSR) to leverage the long-context information available in videos effectively. Specifically, we adopt a bi-encoder architecture to simultaneously model audio and long-context biasing. Besides, we also propose a biasing prediction module that utilizes binary cross entropy (BCE) loss to explicitly determine biased phrases in the long-context biasing. Furthermore, we introduce a dynamic contextual phrases simulation to enhance the generalization and robustness of our LCB-net. Experiments on the SlideSpeech, a large-scale audio-visual corpus enriched with slides, reveal that our proposed LCB-net outperforms general ASR model by 9.4%/9.1%/10.9% relative WER/U-WER/B-WER reduction on test set, which enjoys high unbiased and biased performance. Moreover, we also evaluate our model on LibriSpeech corpus, leading to 23.8%/19.2%/35.4% relative WER/U-WER/B-WER reduction over the ASR model.