 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuSeeL: Language-queried Binaural Universal Sound Event Extraction and Localization
Jan 27, 2026Most universal sound extraction algorithms focus on isolating a target sound event from single-channel audio mixtures. However, the real world is three-dimensional, and binaural audio, which mimics human hearing, can capture richer spatial information, including sound source location. This spatial context is crucial for understanding and modeling complex auditory scenes, as it inherently informs sound detection and extraction. In this work, we propose a language-driven universal sound extraction network that isolates text-described sound events from binaural mixtures by effectively leveraging the spatial cues present in binaural signals. Additionally, we jointly predict the direction of arrival (DoA) of the target sound using spatial features from the extraction network. This dual-task approach exploits complementary location information to improve extraction performance while enabling accurate DoA estimation. Experimental results on the in-the-wild AudioCaps dataset show that our proposed LuSeeL model significantly outperforms single-channel and uni-task baselines.
FlowSE-GRPO: Training Flow Matching Speech Enhancement via Online Reinforcement Learning
Jan 23, 2026Generative speech enhancement offers a promising alternative to traditional discriminative methods by modeling the distribution of clean speech conditioned on noisy inputs. Post-training alignment via reinforcement learning (RL) effectively aligns generative models with human preferences and downstream metrics in domains such as natural language processing, but its use in speech enhancement remains limited, especially for online RL. Prior work explores offline methods like Direct Preference Optimization (DPO); online methods such as Group Relative Policy Optimization (GRPO) remain largely uninvestigated. In this paper, we present the first successful integration of online GRPO into a flow-matching speech enhancement framework, enabling efficient post-training alignment to perceptual and task-oriented metrics with few update steps. Unlike prior GRPO work on Large Language Models, we adapt the algorithm to the continuous, time-series nature of speech and to the dynamics of flow-matching generative models. We show that optimizing a single reward yields rapid metric gains but often induces reward hacking that degrades audio fidelity despite higher scores. To mitigate this, we propose a multi-metric reward optimization strategy that balances competing objectives, substantially reducing overfitting and improving overall performance. Our experiments validate online GRPO for speech enhancement and provide practical guidance for RL-based post-training of generative audio models.
E2E-AEC: Implementing an end-to-end neural network learning approach for acoustic echo cancellation
Jan 23, 2026We propose a novel neural network-based end-to-end acoustic echo cancellation (E2E-AEC) method capable of streaming inference, which operates effectively without reliance on traditional linear AEC (LAEC) techniques and time delay estimation. Our approach includes several key strategies: First, we introduce and refine progressive learning to gradually enhance echo suppression. Second, our model employs knowledge transfer by initializing with a pre-trained LAECbased model, harnessing the insights gained from LAEC training. Third, we optimize the attention mechanism with a loss function applied on attention weights to achieve precise time alignment between the reference and microphone signals. Lastly, we incorporate voice activity detection to enhance speech quality and improve echo removal by masking the network output when near-end speech is absent. The effectiveness of our approach is validated through experiments conducted on public datasets.
TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times
Dec 18, 2025We introduce TurboDiffusion, a video generation acceleration framework that can speed up end-to-end diffusion generation by 100-200x while maintaining video quality. TurboDiffusion mainly relies on several components for acceleration: (1) Attention acceleration: TurboDiffusion uses low-bit SageAttention and trainable Sparse-Linear Attention (SLA) to speed up attention computation. (2) Step distillation: TurboDiffusion adopts rCM for efficient step distillation. (3) W8A8 quantization: TurboDiffusion quantizes model parameters and activations to 8 bits to accelerate linear layers and compress the model. In addition, TurboDiffusion incorporates several other engineering optimizations. We conduct experiments on the Wan2.2-I2V-14B-720P, Wan2.1-T2V-1.3B-480P, Wan2.1-T2V-14B-720P, and Wan2.1-T2V-14B-480P models. Experimental results show that TurboDiffusion achieves 100-200x speedup for video generation even on a single RTX 5090 GPU, while maintaining comparable video quality. The GitHub repository, which includes model checkpoints and easy-to-use code, is available at https://github.com/thu-ml/TurboDiffusion.
MELA-TTS: Joint transformer-diffusion model with representation alignment for speech synthesis
Sep 18, 2025This work introduces MELA-TTS, a novel joint transformer-diffusion framework for end-to-end text-to-speech synthesis. By autoregressively generating continuous mel-spectrogram frames from linguistic and speaker conditions, our architecture eliminates the need for speech tokenization and multi-stage processing pipelines. To address the inherent difficulties of modeling continuous features, we propose a representation alignment module that aligns output representations of the transformer decoder with semantic embeddings from a pretrained ASR encoder during training. This mechanism not only speeds up training convergence, but also enhances cross-modal coherence between the textual and acoustic domains. Comprehensive experiments demonstrate that MELA-TTS achieves state-of-the-art performance across multiple evaluation metrics while maintaining robust zero-shot voice cloning capabilities, in both offline and streaming synthesis modes. Our results establish a new benchmark for continuous feature generation approaches in TTS, offering a compelling alternative to discrete-token-based paradigms.
FLASepformer: Efficient Speech Separation with Gated Focused Linear Attention Transformer
Aug 27, 2025Speech separation always faces the challenge of handling prolonged time sequences. Past methods try to reduce sequence lengths and use the Transformer to capture global information. However, due to the quadratic time complexity of the attention module, memory usage and inference time still increase significantly with longer segments. To tackle this, we introduce Focused Linear Attention and build FLASepformer with linear complexity for efficient speech separation. Inspired by SepReformer and TF-Locoformer, we have two variants: FLA-SepReformer and FLA-TFLocoformer. We also add a new Gated module to improve performance further. Experimental results on various datasets show that FLASepformer matches state-of-the-art performance with less memory consumption and faster inference. FLA-SepReformer-T/B/L increases speed by 2.29x, 1.91x, and 1.49x, with 15.8%, 20.9%, and 31.9% GPU memory usage, proving our model's effectiveness.
Exploring Efficient Directional and Distance Cues for Regional Speech Separation
Aug 11, 2025In this paper, we introduce a neural network-based method for regional speech separation using a microphone array. This approach leverages novel spatial cues to extract the sound source not only from specified direction but also within defined distance. Specifically, our method employs an improved delay-and-sum technique to obtain directional cues, substantially enhancing the signal from the target direction. We further enhance separation by incorporating the direct-to-reverberant ratio into the input features, enabling the model to better discriminate sources within and beyond a specified distance. Experimental results demonstrate that our proposed method leads to substantial gains across multiple objective metrics. Furthermore, our method achieves state-of-the-art performance on the CHiME-8 MMCSG dataset, which was recorded in real-world conversational scenarios, underscoring its effectiveness for speech separation in practical applications.
SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
May 16, 2025The efficiency of attention is important due to its quadratic time complexity. We enhance the efficiency of attention through two key contributions: First, we leverage the new FP4 Tensor Cores in Blackwell GPUs to accelerate attention computation. Our implementation achieves 1038 TOPS on RTX5090, which is a 5x speedup over the fastest FlashAttention on RTX5090. Experiments show that our FP4 attention can accelerate inference of various models in a plug-and-play way. Second, we pioneer low-bit attention to training tasks. Existing low-bit attention works like FlashAttention3 and SageAttention focus only on inference. However, the efficiency of training large models is also important. To explore whether low-bit attention can be effectively applied to training tasks, we design an accurate and efficient 8-bit attention for both forward and backward propagation. Experiments indicate that 8-bit attention achieves lossless performance in fine-tuning tasks but exhibits slower convergence in pretraining tasks. The code will be available at https://github.com/thu-ml/SageAttention.
ZipEnhancer: Dual-Path Down-Up Sampling-based Zipformer for Monaural Speech Enhancement
Jan 09, 2025

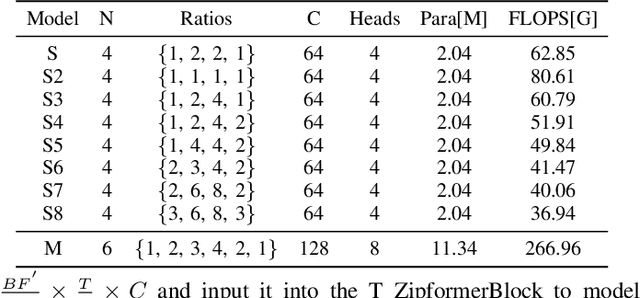
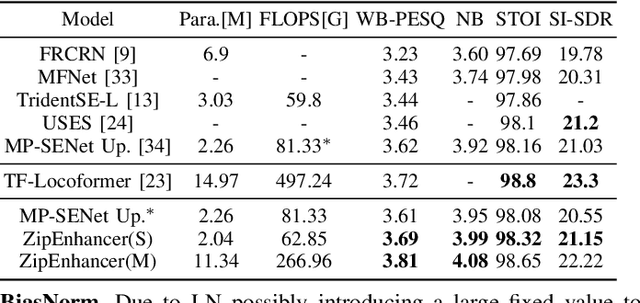
In contrast to other sequence tasks modeling hidden layer features with three axes, Dual-Path time and time-frequency domain speech enhancement models are effective and have low parameters but are computationally demanding due to their hidden layer features with four axes. We propose ZipEnhancer, which is Dual-Path Down-Up Sampling-based Zipformer for Monaural Speech Enhancement, incorporating time and frequency domain Down-Up sampling to reduce computational costs. We introduce the ZipformerBlock as the core block and propose the design of the Dual-Path DownSampleStacks that symmetrically scale down and scale up. Also, we introduce the ScaleAdam optimizer and Eden learning rate scheduler to improve the performance further. Our model achieves new state-of-the-art results on the DNS 2020 Challenge and Voicebank+DEMAND datasets, with a perceptual evaluation of speech quality (PESQ) of 3.69 and 3.63, using 2.04M parameters and 62.41G FLOPS, outperforming other methods with similar complexity levels.
Memory-Efficient and Secure DNN Inference on TrustZone-enabled Consumer IoT Devices
Mar 19, 2024



Edge intelligence enables resource-demanding Deep Neural Network (DNN) inference without transferring original data, addressing concerns about data privacy in consumer Internet of Things (IoT) devices. For privacy-sensitive applications, deploying models in hardware-isolated trusted execution environments (TEEs) becomes essential. However, the limited secure memory in TEEs poses challenges for deploying DNN inference, and alternative techniques like model partitioning and offloading introduce performance degradation and security issues. In this paper, we present a novel approach for advanced model deployment in TrustZone that ensures comprehensive privacy preservation during model inference. We design a memory-efficient management method to support memory-demanding inference in TEEs. By adjusting the memory priority, we effectively mitigate memory leakage risks and memory overlap conflicts, resulting in 32 lines of code alterations in the trusted operating system. Additionally, we leverage two tiny libraries: S-Tinylib (2,538 LoCs), a tiny deep learning library, and Tinylibm (827 LoCs), a tiny math library, to support efficient inference in TEEs. We implemented a prototype on Raspberry Pi 3B+ and evaluated it using three well-known lightweight DNN models. The experimental results demonstrate that our design significantly improves inference speed by 3.13 times and reduces power consumption by over 66.5% compared to non-memory optimization method in TEEs.