 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Adversarial Samples For Training Wake-up Word Detection Systems Against Confusing Words
Jan 01, 2022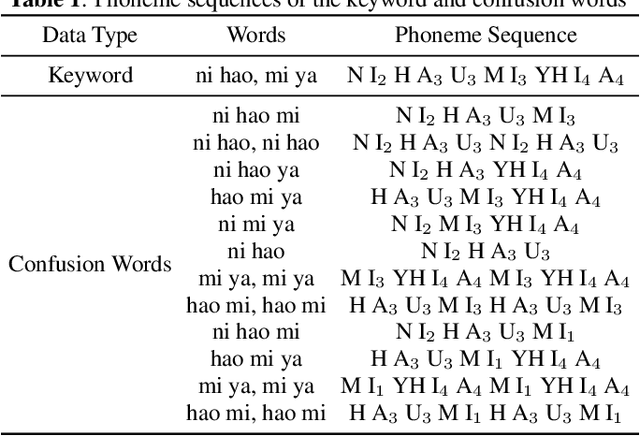
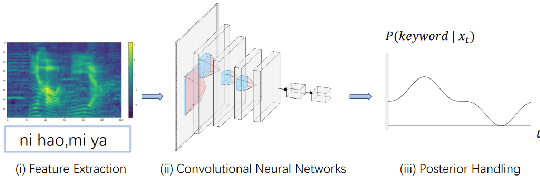


Wake-up word detection models are widely used in real life, but suffer from severe performance degradation when encountering adversarial samples. In this paper we discuss the concept of confusing words in adversarial samples. Confusing words are commonly encountered, which are various kinds of words that sound similar to the predefined keywords. To enhance the wake word detection system's robustness against confusing words, we propose several methods to generate the adversarial confusing samples for simulating real confusing words scenarios in which we usually do not have any real confusing samples in the training set. The generated samples include concatenated audio, synthesized data, and partially masked keywords. Moreover, we use a domain embedding concatenated system to improve the performance. Experimental results show that the adversarial samples generated in our approach help improve the system's robustness in both the common scenario and the confusing words scenario. In addition, we release the confusing words testing database called HI-MIA-CW for future research.
Training Wake Word Detection with Synthesized Speech Data on Confusion Words
Nov 03, 2020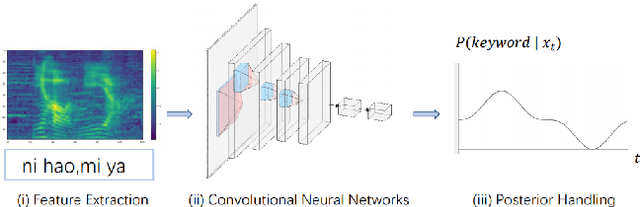
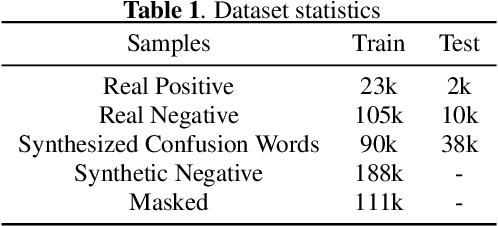
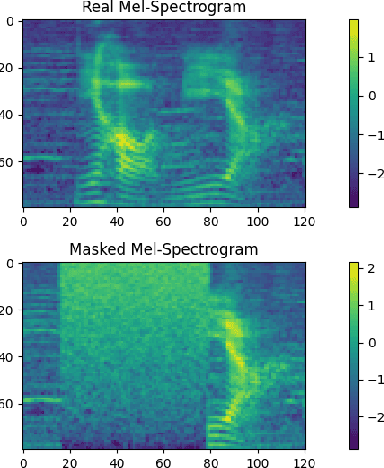
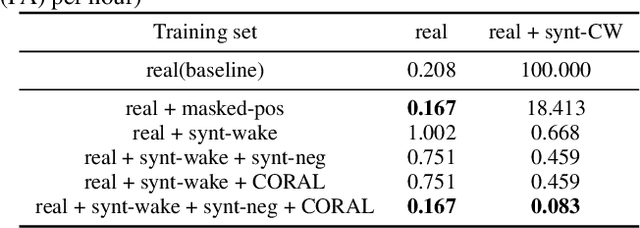
Confusing-words are commonly encountered in real-life keyword spotting applications, which causes severe degradation of performance due to complex spoken terms and various kinds of words that sound similar to the predefined keywords. To enhance the wake word detection system's robustness on such scenarios, we investigate two data augmentation setups for training end-to-end KWS systems. One is involving the synthesized data from a multi-speaker speech synthesis system, and the other augmentation is performed by adding random noise to the acoustic feature. Experimental results show that augmentations help improve the system's robustness. Moreover, by augmenting the training set with the synthetic data generated by the multi-speaker text-to-speech system, we achieve a significant improvement regarding confusing words scenario.