 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePull Requests as a Training Signal for Repo-Level Code Editing
Feb 07, 2026Repository-level code editing requires models to understand complex dependencies and execute precise multi-file modifications across a large codebase. While recent gains on SWE-bench rely heavily on complex agent scaffolding, it remains unclear how much of this capability can be internalised via high-quality training signals. To address this, we propose Clean Pull Request (Clean-PR), a mid-training paradigm that leverages real-world GitHub pull requests as a training signal for repository-level editing. We introduce a scalable pipeline that converts noisy pull request diffs into Search/Replace edit blocks through reconstruction and validation, resulting in the largest publicly available corpus of 2 million pull requests spanning 12 programming languages. Using this training signal, we perform a mid-training stage followed by an agentless-aligned supervised fine-tuning process with error-driven data augmentation. On SWE-bench, our model significantly outperforms the instruction-tuned baseline, achieving absolute improvements of 13.6% on SWE-bench Lite and 12.3% on SWE-bench Verified. These results demonstrate that repository-level code understanding and editing capabilities can be effectively internalised into model weights under a simplified, agentless protocol, without relying on heavy inference-time scaffolding.
Few-Shot Precise Event Spotting via Unified Multi-Entity Graph and Distillation
Nov 18, 2025Precise event spotting (PES) aims to recognize fine-grained events at exact moments and has become a key component of sports analytics. This task is particularly challenging due to rapid succession, motion blur, and subtle visual differences. Consequently, most existing methods rely on domain-specific, end-to-end training with large labeled datasets and often struggle in few-shot conditions due to their dependence on pixel- or pose-based inputs alone. However, obtaining large labeled datasets is practically hard. We propose a Unified Multi-Entity Graph Network (UMEG-Net) for few-shot PES. UMEG-Net integrates human skeletons and sport-specific object keypoints into a unified graph and features an efficient spatio-temporal extraction module based on advanced GCN and multi-scale temporal shift. To further enhance performance, we employ multimodal distillation to transfer knowledge from keypoint-based graphs to visual representations. Our approach achieves robust performance with limited labeled data and significantly outperforms baseline models in few-shot settings, providing a scalable and effective solution for few-shot PES. Code is publicly available at https://github.com/LZYAndy/UMEG-Net.
F$^3$Set: Towards Analyzing Fast, Frequent, and Fine-grained Events from Videos
Apr 15, 2025Analyzing Fast, Frequent, and Fine-grained (F$^3$) events presents a significant challenge in video analytics and multi-modal LLMs. Current methods struggle to identify events that satisfy all the F$^3$ criteria with high accuracy due to challenges such as motion blur and subtle visual discrepancies. To advance research in video understanding, we introduce F$^3$Set, a benchmark that consists of video datasets for precise F$^3$ event detection. Datasets in F$^3$Set are characterized by their extensive scale and comprehensive detail, usually encompassing over 1,000 event types with precise timestamps and supporting multi-level granularity. Currently, F$^3$Set contains several sports datasets, and this framework may be extended to other applications as well. We evaluated popular temporal action understanding methods on F$^3$Set, revealing substantial challenges for existing techniques. Additionally, we propose a new method, F$^3$ED, for F$^3$ event detections, achieving superior performance. The dataset, model, and benchmark code are available at https://github.com/F3Set/F3Set.
Novel View Synthesis for High-fidelity Headshot Scenes
May 31, 2022
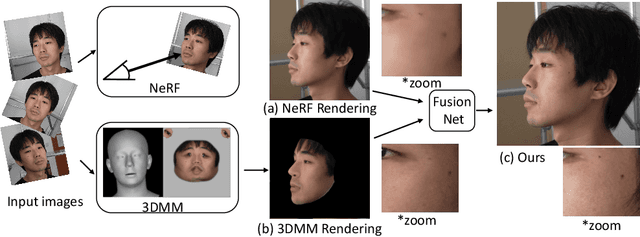
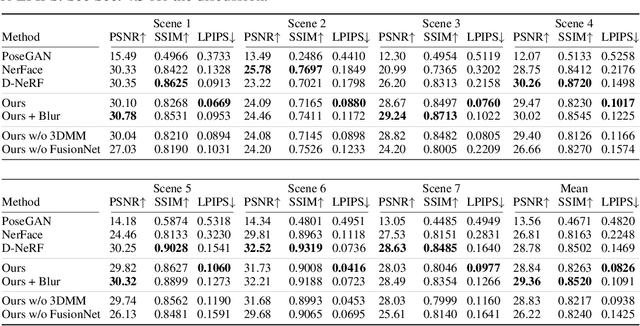
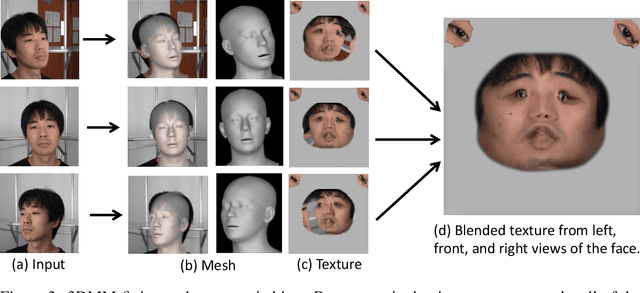
Rendering scenes with a high-quality human face from arbitrary viewpoints is a practical and useful technique for many real-world applications. Recently, Neural Radiance Fields (NeRF), a rendering technique that uses neural networks to approximate classical ray tracing, have been considered as one of the promising approaches for synthesizing novel views from a sparse set of images. We find that NeRF can render new views while maintaining geometric consistency, but it does not properly maintain skin details, such as moles and pores. These details are important particularly for faces because when we look at an image of a face, we are much more sensitive to details than when we look at other objects. On the other hand, 3D Morpable Models (3DMMs) based on traditional meshes and textures can perform well in terms of skin detail despite that it has less precise geometry and cannot cover the head and the entire scene with background. Based on these observations, we propose a method to use both NeRF and 3DMM to synthesize a high-fidelity novel view of a scene with a face. Our method learns a Generative Adversarial Network (GAN) to mix a NeRF-synthesized image and a 3DMM-rendered image and produces a photorealistic scene with a face preserving the skin details. Experiments with various real-world scenes demonstrate the effectiveness of our approach. The code will be available on https://github.com/showlab/headshot .
The DKU System Description for The Interspeech 2021 Auto-KWS Challenge
Apr 11, 2021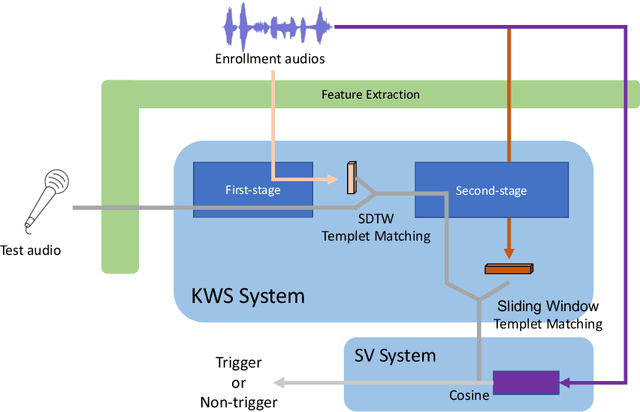
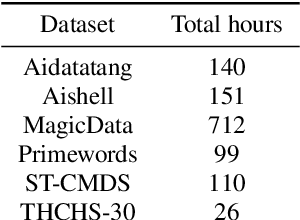
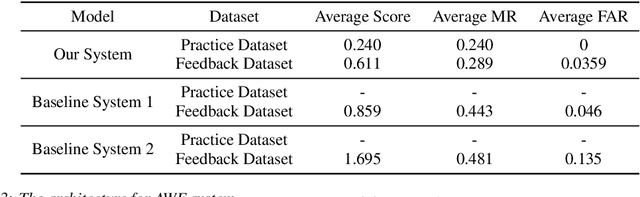
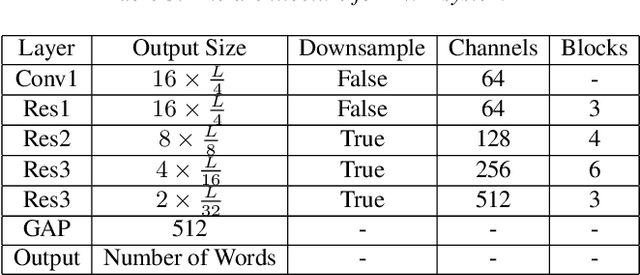
This paper introduces the system submitted by the DKU-SMIIP team for the Auto-KWS 2021 Challenge. Our implementation consists of a two-stage keyword spotting system based on query-by-example spoken term detection and a speaker verification system. We employ two different detection algorithms in our proposed keyword spotting system. The first stage adopts subsequence dynamic time warping for template matching based on frame-level language-independent bottleneck feature and phoneme posterior probability. We use a sliding window template matching algorithm based on acoustic word embeddings to further verify the detection from the first stage. As a result, our KWS system achieves an average score of 0.61 on the feedback dataset, which outperforms the baseline1 system by 0.25.
Training Wake Word Detection with Synthesized Speech Data on Confusion Words
Nov 03, 2020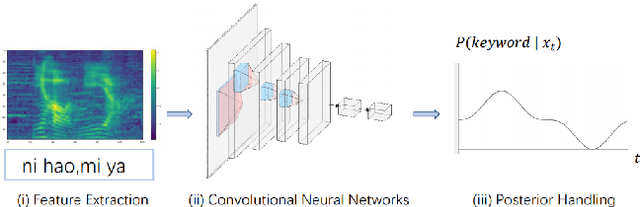
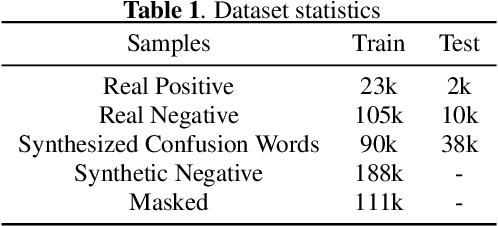
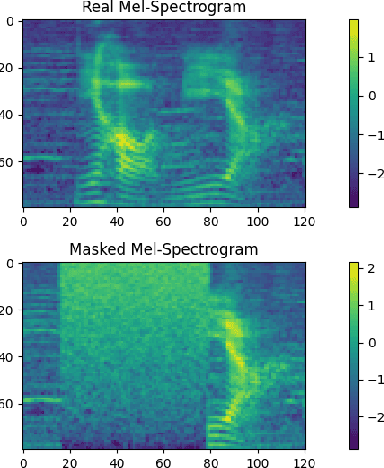
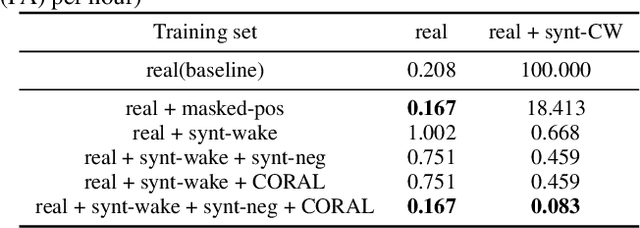
Confusing-words are commonly encountered in real-life keyword spotting applications, which causes severe degradation of performance due to complex spoken terms and various kinds of words that sound similar to the predefined keywords. To enhance the wake word detection system's robustness on such scenarios, we investigate two data augmentation setups for training end-to-end KWS systems. One is involving the synthesized data from a multi-speaker speech synthesis system, and the other augmentation is performed by adding random noise to the acoustic feature. Experimental results show that augmentations help improve the system's robustness. Moreover, by augmenting the training set with the synthetic data generated by the multi-speaker text-to-speech system, we achieve a significant improvement regarding confusing words scenario.
Acoustic Word Embedding System for Code-Switching Query-by-example Spoken Term Detection
May 24, 2020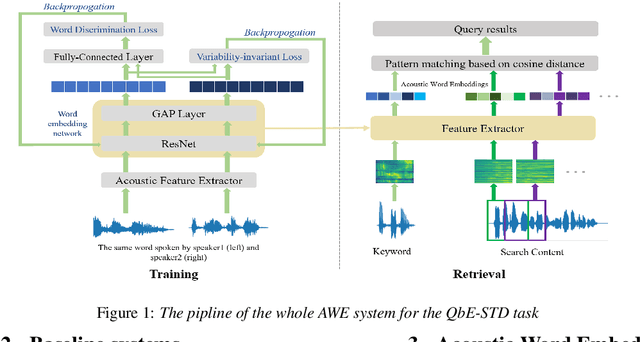
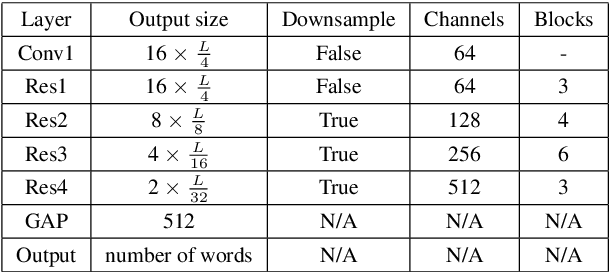
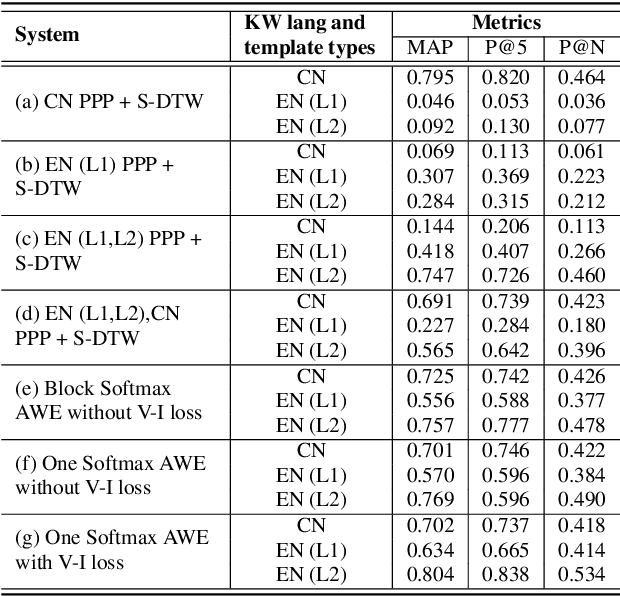
In this paper, we propose a deep convolutional neural network-based acoustic word embedding system on code-switching query by example spoken term detection. Different from previous configurations, we combine audio data in two languages for training instead of only using one single language. We transform the acoustic features of keyword templates and searching content to fixed-dimensional vectors and calculate the distances between keyword segments and searching content segments obtained in a sliding manner. An auxiliary variability-invariant loss is also applied to training data within the same word but different speakers. This strategy is used to prevent the extractor from encoding undesired speaker- or accent-related information into the acoustic word embeddings. Experimental results show that our proposed system produces promising searching results in the code-switching test scenario. With the increased number of templates and the employment of variability-invariant loss, the searching performance is further enhanced.