 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADCD-Net: Robust Document Image Forgery Localization via Adaptive DCT Feature and Hierarchical Content Disentanglement
Jul 22, 2025The advancement of image editing tools has enabled malicious manipulation of sensitive document images, underscoring the need for robust document image forgery detection.Though forgery detectors for natural images have been extensively studied, they struggle with document images, as the tampered regions can be seamlessly blended into the uniform document background (BG) and structured text. On the other hand, existing document-specific methods lack sufficient robustness against various degradations, which limits their practical deployment. This paper presents ADCD-Net, a robust document forgery localization model that adaptively leverages the RGB/DCT forensic traces and integrates key characteristics of document images. Specifically, to address the DCT traces' sensitivity to block misalignment, we adaptively modulate the DCT feature contribution based on a predicted alignment score, resulting in much improved resilience to various distortions, including resizing and cropping. Also, a hierarchical content disentanglement approach is proposed to boost the localization performance via mitigating the text-BG disparities. Furthermore, noticing the predominantly pristine nature of BG regions, we construct a pristine prototype capturing traces of untampered regions, and eventually enhance both the localization accuracy and robustness. Our proposed ADCD-Net demonstrates superior forgery localization performance, consistently outperforming state-of-the-art methods by 20.79\% averaged over 5 types of distortions. The code is available at https://github.com/KAHIMWONG/ACDC-Net.
Structure Disruption: Subverting Malicious Diffusion-Based Inpainting via Self-Attention Query Perturbation
May 26, 2025The rapid advancement of diffusion models has enhanced their image inpainting and editing capabilities but also introduced significant societal risks. Adversaries can exploit user images from social media to generate misleading or harmful content. While adversarial perturbations can disrupt inpainting, global perturbation-based methods fail in mask-guided editing tasks due to spatial constraints. To address these challenges, we propose Structure Disruption Attack (SDA), a powerful protection framework for safeguarding sensitive image regions against inpainting-based editing. Building upon the contour-focused nature of self-attention mechanisms of diffusion models, SDA optimizes perturbations by disrupting queries in self-attention during the initial denoising step to destroy the contour generation process. This targeted interference directly disrupts the structural generation capability of diffusion models, effectively preventing them from producing coherent images. We validate our motivation through visualization techniques and extensive experiments on public datasets, demonstrating that SDA achieves state-of-the-art (SOTA) protection performance while maintaining strong robustness.
Anti-Diffusion: Preventing Abuse of Modifications of Diffusion-Based Models
Mar 07, 2025Although diffusion-based techniques have shown remarkable success in image generation and editing tasks, their abuse can lead to severe negative social impacts. Recently, some works have been proposed to provide defense against the abuse of diffusion-based methods. However, their protection may be limited in specific scenarios by manually defined prompts or the stable diffusion (SD) version. Furthermore, these methods solely focus on tuning methods, overlooking editing methods that could also pose a significant threat. In this work, we propose Anti-Diffusion, a privacy protection system designed for general diffusion-based methods, applicable to both tuning and editing techniques. To mitigate the limitations of manually defined prompts on defense performance, we introduce the prompt tuning (PT) strategy that enables precise expression of original images. To provide defense against both tuning and editing methods, we propose the semantic disturbance loss (SDL) to disrupt the semantic information of protected images. Given the limited research on the defense against editing methods, we develop a dataset named Defense-Edit to assess the defense performance of various methods. Experiments demonstrate that our Anti-Diffusion achieves superior defense performance across a wide range of diffusion-based techniques in different scenarios.
DAT: Improving Adversarial Robustness via Generative Amplitude Mix-up in Frequency Domain
Oct 16, 2024



To protect deep neural networks (DNNs) from adversarial attacks, adversarial training (AT) is developed by incorporating adversarial examples (AEs) into model training. Recent studies show that adversarial attacks disproportionately impact the patterns within the phase of the sample's frequency spectrum -- typically containing crucial semantic information -- more than those in the amplitude, resulting in the model's erroneous categorization of AEs. We find that, by mixing the amplitude of training samples' frequency spectrum with those of distractor images for AT, the model can be guided to focus on phase patterns unaffected by adversarial perturbations. As a result, the model's robustness can be improved. Unfortunately, it is still challenging to select appropriate distractor images, which should mix the amplitude without affecting the phase patterns. To this end, in this paper, we propose an optimized Adversarial Amplitude Generator (AAG) to achieve a better tradeoff between improving the model's robustness and retaining phase patterns. Based on this generator, together with an efficient AE production procedure, we design a new Dual Adversarial Training (DAT) strategy. Experiments on various datasets show that our proposed DAT leads to significantly improved robustness against diverse adversarial attacks.
Progressive Poisoned Data Isolation for Training-time Backdoor Defense
Dec 20, 2023



Deep Neural Networks (DNN) are susceptible to backdoor attacks where malicious attackers manipulate the model's predictions via data poisoning. It is hence imperative to develop a strategy for training a clean model using a potentially poisoned dataset. Previous training-time defense mechanisms typically employ an one-time isolation process, often leading to suboptimal isolation outcomes. In this study, we present a novel and efficacious defense method, termed Progressive Isolation of Poisoned Data (PIPD), that progressively isolates poisoned data to enhance the isolation accuracy and mitigate the risk of benign samples being misclassified as poisoned ones. Once the poisoned portion of the dataset has been identified, we introduce a selective training process to train a clean model. Through the implementation of these techniques, we ensure that the trained model manifests a significantly diminished attack success rate against the poisoned data. Extensive experiments on multiple benchmark datasets and DNN models, assessed against nine state-of-the-art backdoor attacks, demonstrate the superior performance of our PIPD method for backdoor defense. For instance, our PIPD achieves an average True Positive Rate (TPR) of 99.95% and an average False Positive Rate (FPR) of 0.06% for diverse attacks over CIFAR-10 dataset, markedly surpassing the performance of state-of-the-art methods.
Generating Robust Adversarial Examples against Online Social Networks (OSNs)
Oct 19, 2023Online Social Networks (OSNs) have blossomed into prevailing transmission channels for images in the modern era. Adversarial examples (AEs) deliberately designed to mislead deep neural networks (DNNs) are found to be fragile against the inevitable lossy operations conducted by OSNs. As a result, the AEs would lose their attack capabilities after being transmitted over OSNs. In this work, we aim to design a new framework for generating robust AEs that can survive the OSN transmission; namely, the AEs before and after the OSN transmission both possess strong attack capabilities. To this end, we first propose a differentiable network termed SImulated OSN (SIO) to simulate the various operations conducted by an OSN. Specifically, the SIO network consists of two modules: 1) a differentiable JPEG layer for approximating the ubiquitous JPEG compression and 2) an encoder-decoder subnetwork for mimicking the remaining operations. Based upon the SIO network, we then formulate an optimization framework to generate robust AEs by enforcing model outputs with and without passing through the SIO to be both misled. Extensive experiments conducted over Facebook, WeChat and QQ demonstrate that our attack methods produce more robust AEs than existing approaches, especially under small distortion constraints; the performance gain in terms of Attack Success Rate (ASR) could be more than 60%. Furthermore, we build a public dataset containing more than 10,000 pairs of AEs processed by Facebook, WeChat or QQ, facilitating future research in the robust AEs generation. The dataset and code are available at https://github.com/csjunjun/RobustOSNAttack.git.
Rethinking Image Forgery Detection via Contrastive Learning and Unsupervised Clustering
Aug 18, 2023Image forgery detection aims to detect and locate forged regions in an image. Most existing forgery detection algorithms formulate classification problems to classify pixels into forged or pristine. However, the definition of forged and pristine pixels is only relative within one single image, e.g., a forged region in image A is actually a pristine one in its source image B (splicing forgery). Such a relative definition has been severely overlooked by existing methods, which unnecessarily mix forged (pristine) regions across different images into the same category. To resolve this dilemma, we propose the FOrensic ContrAstive cLustering (FOCAL) method, a novel, simple yet very effective paradigm based on contrastive learning and unsupervised clustering for the image forgery detection. Specifically, FOCAL 1) utilizes pixel-level contrastive learning to supervise the high-level forensic feature extraction in an image-by-image manner, explicitly reflecting the above relative definition; 2) employs an on-the-fly unsupervised clustering algorithm (instead of a trained one) to cluster the learned features into forged/pristine categories, further suppressing the cross-image influence from training data; and 3) allows to further boost the detection performance via simple feature-level concatenation without the need of retraining. Extensive experimental results over six public testing datasets demonstrate that our proposed FOCAL significantly outperforms the state-of-the-art competing algorithms by big margins: +24.3% on Coverage, +18.6% on Columbia, +17.5% on FF++, +14.2% on MISD, +13.5% on CASIA and +10.3% on NIST in terms of IoU. The paradigm of FOCAL could bring fresh insights and serve as a novel benchmark for the image forgery detection task. The code is available at https://github.com/HighwayWu/FOCAL.
Generalizable Synthetic Image Detection via Language-guided Contrastive Learning
May 23, 2023The heightened realism of AI-generated images can be attributed to the rapid development of synthetic models, including generative adversarial networks (GANs) and diffusion models (DMs). The malevolent use of synthetic images, such as the dissemination of fake news or the creation of fake profiles, however, raises significant concerns regarding the authenticity of images. Though many forensic algorithms have been developed for detecting synthetic images, their performance, especially the generalization capability, is still far from being adequate to cope with the increasing number of synthetic models. In this work, we propose a simple yet very effective synthetic image detection method via a language-guided contrastive learning and a new formulation of the detection problem. We first augment the training images with carefully-designed textual labels, enabling us to use a joint image-text contrastive learning for the forensic feature extraction. In addition, we formulate the synthetic image detection as an identification problem, which is vastly different from the traditional classification-based approaches. It is shown that our proposed LanguAge-guided SynThEsis Detection (LASTED) model achieves much improved generalizability to unseen image generation models and delivers promising performance that far exceeds state-of-the-art competitors by +22.66% accuracy and +15.24% AUC. The code is available at https://github.com/HighwayWu/LASTED.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022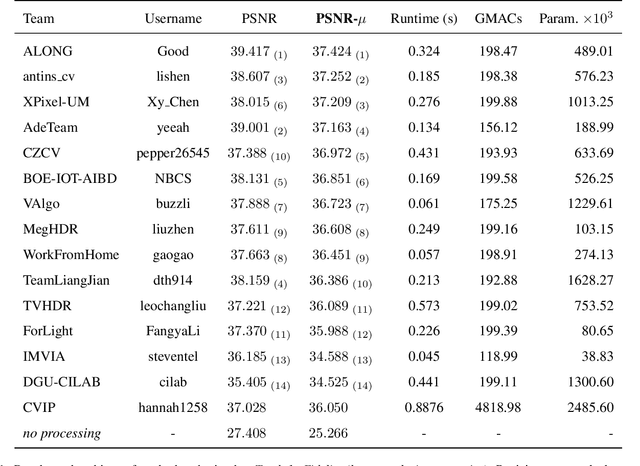
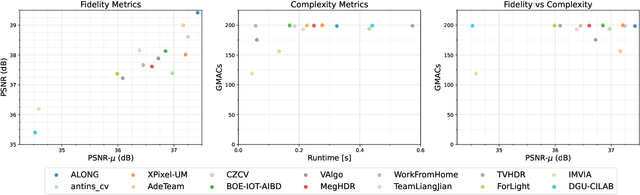
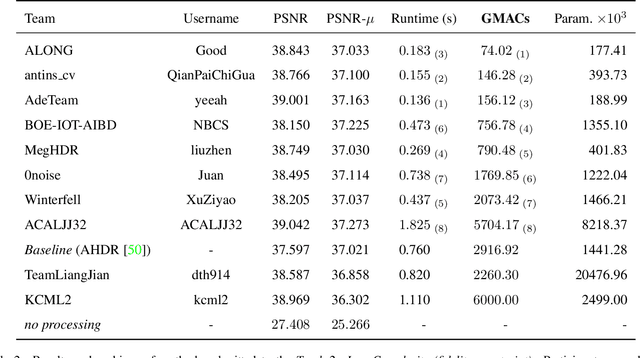
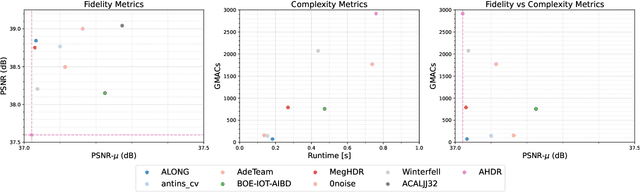
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
GIID-Net: Generalizable Image Inpainting Detection via Neural Architecture Search and Attention
Jan 29, 2021



Deep learning (DL) has demonstrated its powerful capabilities in the field of image inpainting, which could produce visually plausible results. Meanwhile, the malicious use of advanced image inpainting tools (e.g. removing key objects to report fake news) has led to increasing threats to the reliability of image data. To fight against the inpainting forgeries, in this work, we propose a novel end-to-end Generalizable Image Inpainting Detection Network (GIID-Net), to detect the inpainted regions at pixel accuracy. The proposed GIID-Net consists of three sub-blocks: the enhancement block, the extraction block and the decision block. Specifically, the enhancement block aims to enhance the inpainting traces by using hierarchically combined special layers. The extraction block, automatically designed by Neural Architecture Search (NAS) algorithm, is targeted to extract features for the actual inpainting detection tasks. In order to further optimize the extracted latent features, we integrate global and local attention modules in the decision block, where the global attention reduces the intra-class differences by measuring the similarity of global features, while the local attention strengthens the consistency of local features. Furthermore, we thoroughly study the generalizability of our GIID-Net, and find that different training data could result in vastly different generalization capability. Extensive experimental results are presented to validate the superiority of the proposed GIID-Net, compared with the state-of-the-art competitors. Our results would suggest that common artifacts are shared across diverse image inpainting methods. Finally, we build a public inpainting dataset of 10K image pairs for the future research in this area.