 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Anything: 4D Face Reconstruction from Any Image Sequence
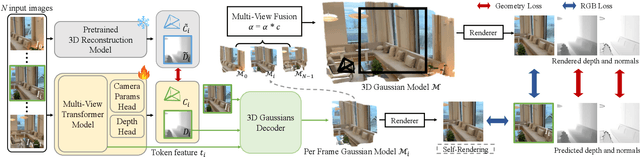
Apr 21, 2026Accurate reconstruction and tracking of dynamic human faces from image sequences is challenging because non-rigid deformations, expression changes, and viewpoint variations occur simultaneously, creating significant ambiguity in geometry and correspondence estimation. We present a unified method for high-fidelity 4D facial reconstruction based on canonical facial point prediction, a representation that assigns each pixel a normalized facial coordinate in a shared canonical space. This formulation transforms dense tracking and dynamic reconstruction into a canonical reconstruction problem, enabling temporally consistent geometry and reliable correspondences within a single feed-forward model. By jointly predicting depth and canonical coordinates, our method enables accurate depth estimation, temporally stable reconstruction, dense 3D geometry, and robust facial point tracking within a single architecture. We implement this formulation using a transformer-based model that jointly predicts depth and canonical facial coordinates, trained using multi-view geometry data that non-rigidly warps into the canonical space. Extensive experiments on image and video benchmarks demonstrate state-of-the-art performance across reconstruction and tracking tasks, achieving approximately 3$\times$ lower correspondence error and faster inference than prior dynamic reconstruction methods, while improving depth accuracy by 16%. These results highlight canonical facial point prediction as an effective foundation for unified feed-forward 4D facial reconstruction.
ICo3D: An Interactive Conversational 3D Virtual Human
Jan 19, 2026This work presents Interactive Conversational 3D Virtual Human (ICo3D), a method for generating an interactive, conversational, and photorealistic 3D human avatar. Based on multi-view captures of a subject, we create an animatable 3D face model and a dynamic 3D body model, both rendered by splatting Gaussian primitives. Once merged together, they represent a lifelike virtual human avatar suitable for real-time user interactions. We equip our avatar with an LLM for conversational ability. During conversation, the audio speech of the avatar is used as a driving signal to animate the face model, enabling precise synchronization. We describe improvements to our dynamic Gaussian models that enhance photorealism: SWinGS++ for body reconstruction and HeadGaS++ for face reconstruction, and provide as well a solution to merge the separate face and body models without artifacts. We also present a demo of the complete system, showcasing several use cases of real-time conversation with the 3D avatar. Our approach offers a fully integrated virtual avatar experience, supporting both oral and written form interactions in immersive environments. ICo3D is applicable to a wide range of fields, including gaming, virtual assistance, and personalized education, among others. Project page: https://ico3d.github.io/
Off The Grid: Detection of Primitives for Feed-Forward 3D Gaussian Splatting
Dec 17, 2025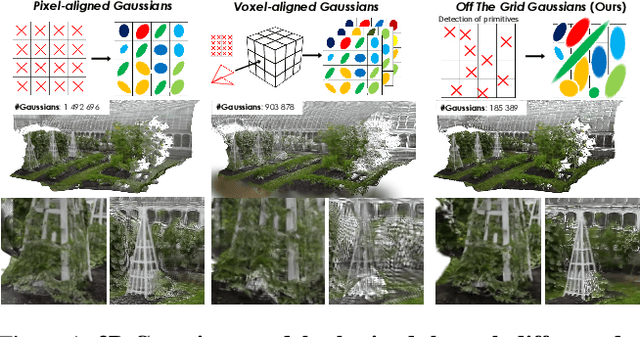


Feed-forward 3D Gaussian Splatting (3DGS) models enable real-time scene generation but are hindered by suboptimal pixel-aligned primitive placement, which relies on a dense, rigid grid and limits both quality and efficiency. We introduce a new feed-forward architecture that detects 3D Gaussian primitives at a sub-pixel level, replacing the pixel grid with an adaptive, "Off The Grid" distribution. Inspired by keypoint detection, our multi-resolution decoder learns to distribute primitives across image patches. This module is trained end-to-end with a 3D reconstruction backbone using self-supervised learning. Our resulting pose-free model generates photorealistic scenes in seconds, achieving state-of-the-art novel view synthesis for feed-forward models. It outperforms competitors while using far fewer primitives, demonstrating a more accurate and efficient allocation that captures fine details and reduces artifacts. Moreover, we observe that by learning to render 3D Gaussians, our 3D reconstruction backbone improves camera pose estimation, suggesting opportunities to train these foundational models without labels.
Better Together: Unified Motion Capture and 3D Avatar Reconstruction
Mar 12, 2025We present Better Together, a method that simultaneously solves the human pose estimation problem while reconstructing a photorealistic 3D human avatar from multi-view videos. While prior art usually solves these problems separately, we argue that joint optimization of skeletal motion with a 3D renderable body model brings synergistic effects, i.e. yields more precise motion capture and improved visual quality of real-time rendering of avatars. To achieve this, we introduce a novel animatable avatar with 3D Gaussians rigged on a personalized mesh and propose to optimize the motion sequence with time-dependent MLPs that provide accurate and temporally consistent pose estimates. We first evaluate our method on highly challenging yoga poses and demonstrate state-of-the-art accuracy on multi-view human pose estimation, reducing error by 35% on body joints and 45% on hand joints compared to keypoint-based methods. At the same time, our method significantly boosts the visual quality of animatable avatars (+2dB PSNR on novel view synthesis) on diverse challenging subjects.
RoGUENeRF: A Robust Geometry-Consistent Universal Enhancer for NeRF
Mar 18, 2024
Recent advances in neural rendering have enabled highly photorealistic 3D scene reconstruction and novel view synthesis. Despite this progress, current state-of-the-art methods struggle to reconstruct high frequency detail, due to factors such as a low-frequency bias of radiance fields and inaccurate camera calibration. One approach to mitigate this issue is to enhance images post-rendering. 2D enhancers can be pre-trained to recover some detail but are agnostic to scene geometry and do not easily generalize to new distributions of image degradation. Conversely, existing 3D enhancers are able to transfer detail from nearby training images in a generalizable manner, but suffer from inaccurate camera calibration and can propagate errors from the geometry into rendered images. We propose a neural rendering enhancer, RoGUENeRF, which exploits the best of both paradigms. Our method is pre-trained to learn a general enhancer while also leveraging information from nearby training images via robust 3D alignment and geometry-aware fusion. Our approach restores high-frequency textures while maintaining geometric consistency and is also robust to inaccurate camera calibration. We show that RoGUENeRF substantially enhances the rendering quality of a wide range of neural rendering baselines, e.g. improving the PSNR of MipNeRF360 by 0.63dB and Nerfacto by 1.34dB on the real world 360v2 dataset.
SWAGS: Sampling Windows Adaptively for Dynamic 3D Gaussian Splatting
Dec 20, 2023Novel view synthesis has shown rapid progress recently, with methods capable of producing evermore photo-realistic results. 3D Gaussian Splatting has emerged as a particularly promising method, producing high-quality renderings of static scenes and enabling interactive viewing at real-time frame rates. However, it is currently limited to static scenes only. In this work, we extend 3D Gaussian Splatting to reconstruct dynamic scenes. We model the dynamics of a scene using a tunable MLP, which learns the deformation field from a canonical space to a set of 3D Gaussians per frame. To disentangle the static and dynamic parts of the scene, we learn a tuneable parameter for each Gaussian, which weighs the respective MLP parameters to focus attention on the dynamic parts. This improves the model's ability to capture dynamics in scenes with an imbalance of static to dynamic regions. To handle scenes of arbitrary length whilst maintaining high rendering quality, we introduce an adaptive window sampling strategy to partition the sequence into windows based on the amount of movement in the sequence. We train a separate dynamic Gaussian Splatting model for each window, allowing the canonical representation to change, thus enabling the reconstruction of scenes with significant geometric or topological changes. Temporal consistency is enforced using a fine-tuning step with self-supervising consistency loss on randomly sampled novel views. As a result, our method produces high-quality renderings of general dynamic scenes with competitive quantitative performance, which can be viewed in real-time with our dynamic interactive viewer.
HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian Splatting
Dec 05, 2023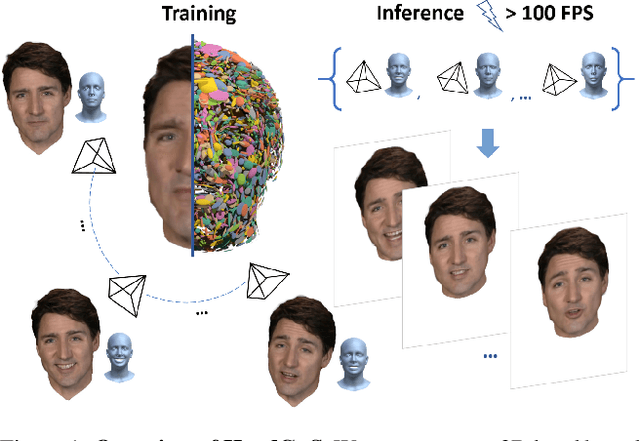
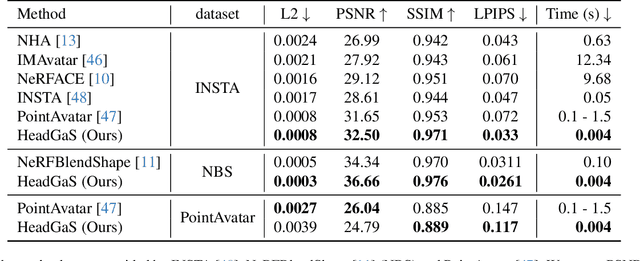
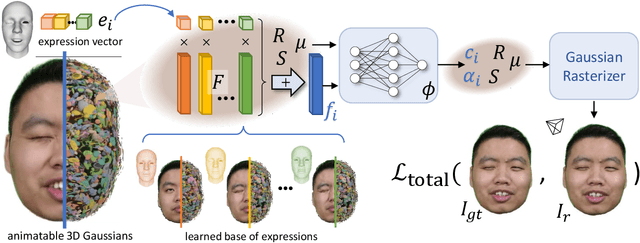
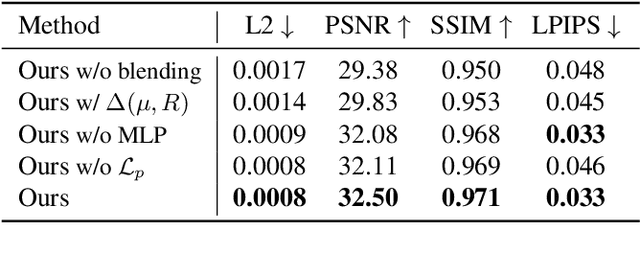
3D head animation has seen major quality and runtime improvements over the last few years, particularly empowered by the advances in differentiable rendering and neural radiance fields. Real-time rendering is a highly desirable goal for real-world applications. We propose HeadGaS, the first model to use 3D Gaussian Splats (3DGS) for 3D head reconstruction and animation. In this paper we introduce a hybrid model that extends the explicit representation from 3DGS with a base of learnable latent features, which can be linearly blended with low-dimensional parameters from parametric head models to obtain expression-dependent final color and opacity values. We demonstrate that HeadGaS delivers state-of-the-art results in real-time inference frame rates, which surpasses baselines by up to ~2dB, while accelerating rendering speed by over x10.
Human Gaussian Splatting: Real-time Rendering of Animatable Avatars
Nov 28, 2023



This work addresses the problem of real-time rendering of photorealistic human body avatars learned from multi-view videos. While the classical approaches to model and render virtual humans generally use a textured mesh, recent research has developed neural body representations that achieve impressive visual quality. However, these models are difficult to render in real-time and their quality degrades when the character is animated with body poses different than the training observations. We propose the first animatable human model based on 3D Gaussian Splatting, that has recently emerged as a very efficient alternative to neural radiance fields. Our body is represented by a set of gaussian primitives in a canonical space which are deformed in a coarse to fine approach that combines forward skinning and local non-rigid refinement. We describe how to learn our Human Gaussian Splatting (\OURS) model in an end-to-end fashion from multi-view observations, and evaluate it against the state-of-the-art approaches for novel pose synthesis of clothed body. Our method presents a PSNR 1.5dbB better than the state-of-the-art on THuman4 dataset while being able to render at 20fps or more.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022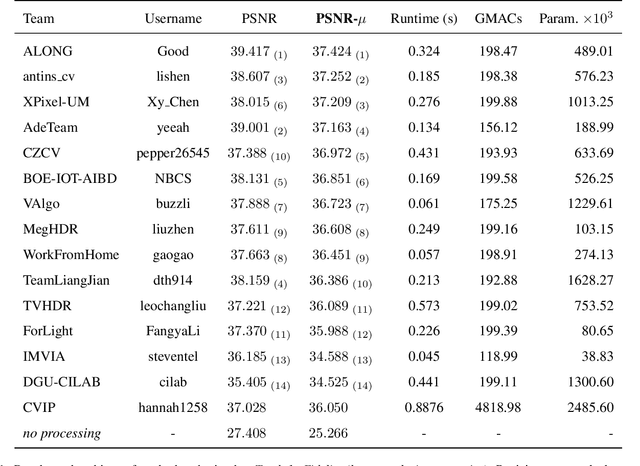
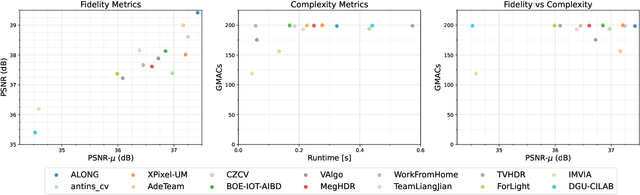
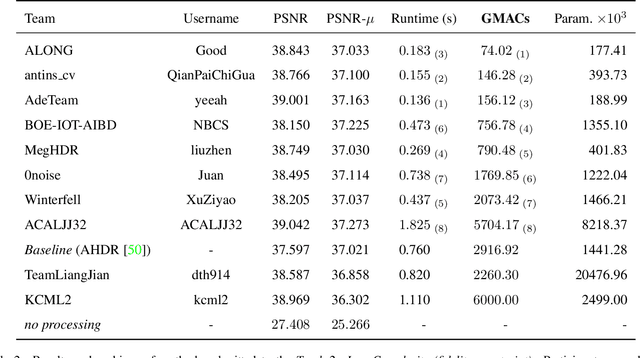
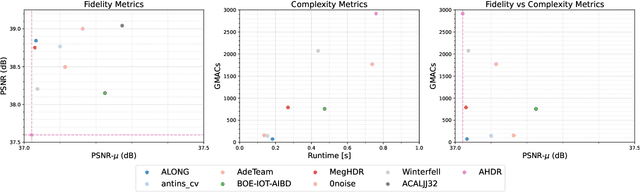
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
HDR Reconstruction from Bracketed Exposures and Events
Mar 28, 2022
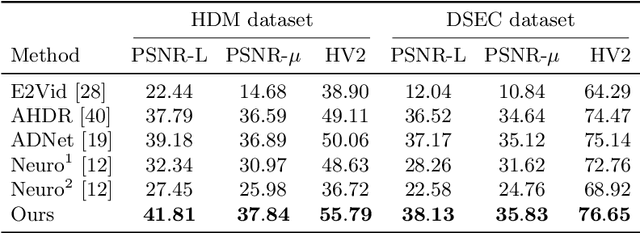
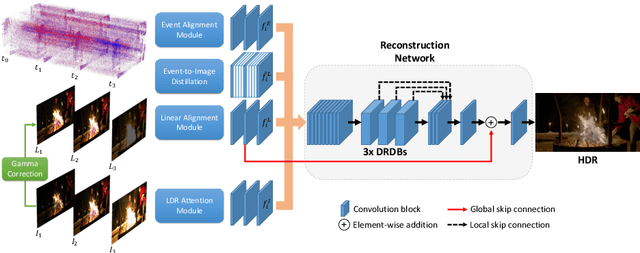
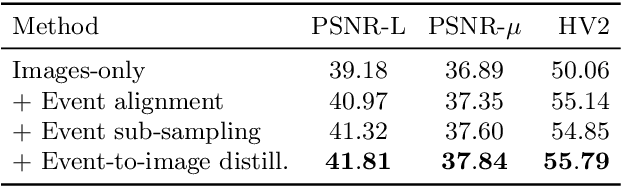
Reconstruction of high-quality HDR images is at the core of modern computational photography. Significant progress has been made with multi-frame HDR reconstruction methods, producing high-resolution, rich and accurate color reconstructions with high-frequency details. However, they are still prone to fail in dynamic or largely over-exposed scenes, where frame misalignment often results in visible ghosting artifacts. Recent approaches attempt to alleviate this by utilizing an event-based camera (EBC), which measures only binary changes of illuminations. Despite their desirable high temporal resolution and dynamic range characteristics, such approaches have not outperformed traditional multi-frame reconstruction methods, mainly due to the lack of color information and low-resolution sensors. In this paper, we propose to leverage both bracketed LDR images and simultaneously captured events to obtain the best of both worlds: high-quality RGB information from bracketed LDRs and complementary high frequency and dynamic range information from events. We present a multi-modal end-to-end learning-based HDR imaging system that fuses bracketed images and event modalities in the feature domain using attention and multi-scale spatial alignment modules. We propose a novel event-to-image feature distillation module that learns to translate event features into the image-feature space with self-supervision. Our framework exploits the higher temporal resolution of events by sub-sampling the input event streams using a sliding window, enriching our combined feature representation. Our proposed approach surpasses SoTA multi-frame HDR reconstruction methods using synthetic and real events, with a 2dB and 1dB improvement in PSNR-L and PSNR-mu on the HdM HDR dataset, respectively.