 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan segmentation models be trained with fully synthetically generated data?
Sep 17, 2022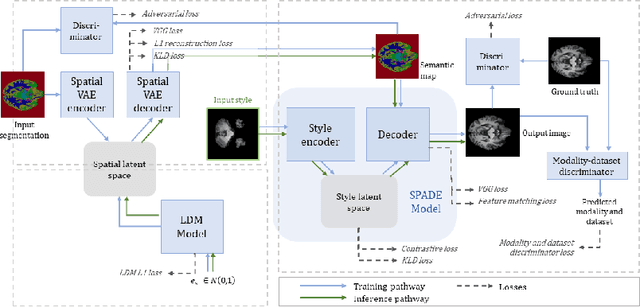

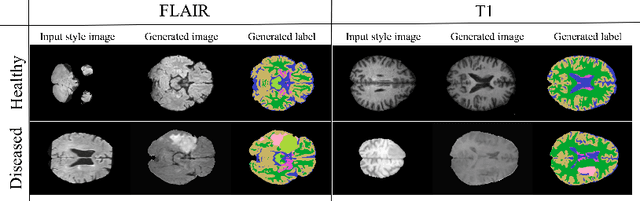
In order to achieve good performance and generalisability, medical image segmentation models should be trained on sizeable datasets with sufficient variability. Due to ethics and governance restrictions, and the costs associated with labelling data, scientific development is often stifled, with models trained and tested on limited data. Data augmentation is often used to artificially increase the variability in the data distribution and improve model generalisability. Recent works have explored deep generative models for image synthesis, as such an approach would enable the generation of an effectively infinite amount of varied data, addressing the generalisability and data access problems. However, many proposed solutions limit the user's control over what is generated. In this work, we propose brainSPADE, a model which combines a synthetic diffusion-based label generator with a semantic image generator. Our model can produce fully synthetic brain labels on-demand, with or without pathology of interest, and then generate a corresponding MRI image of an arbitrary guided style. Experiments show that brainSPADE synthetic data can be used to train segmentation models with performance comparable to that of models trained on real data.
Transformer-based out-of-distribution detection for clinically safe segmentation
May 21, 2022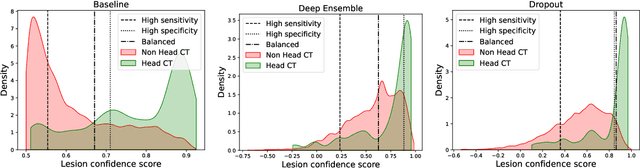
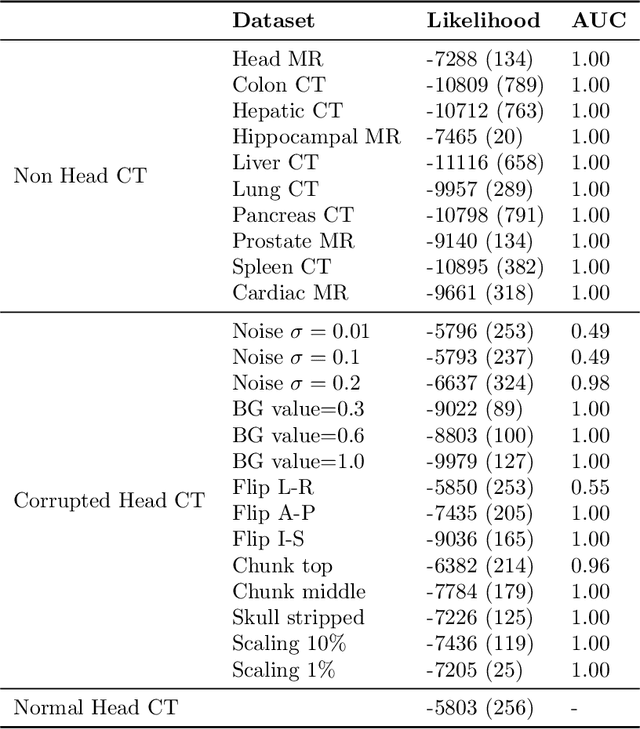
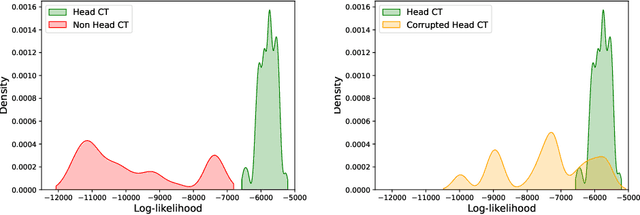
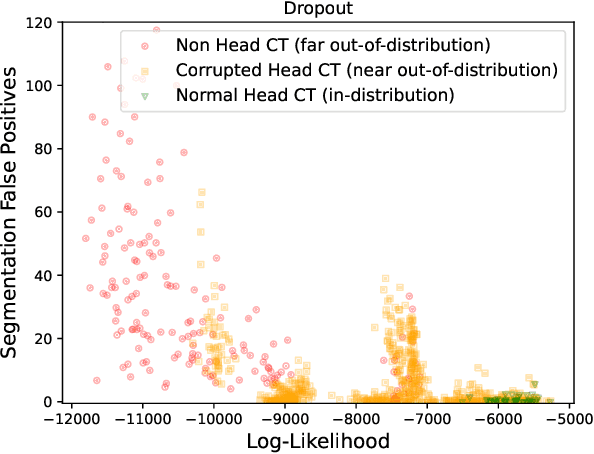
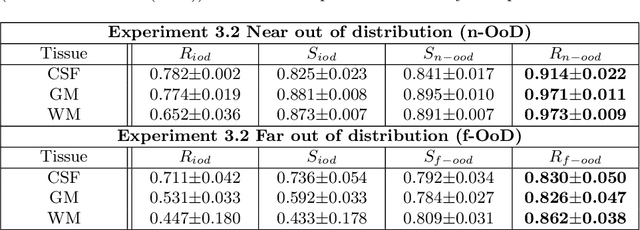
In a clinical setting it is essential that deployed image processing systems are robust to the full range of inputs they might encounter and, in particular, do not make confidently wrong predictions. The most popular approach to safe processing is to train networks that can provide a measure of their uncertainty, but these tend to fail for inputs that are far outside the training data distribution. Recently, generative modelling approaches have been proposed as an alternative; these can quantify the likelihood of a data sample explicitly, filtering out any out-of-distribution (OOD) samples before further processing is performed. In this work, we focus on image segmentation and evaluate several approaches to network uncertainty in the far-OOD and near-OOD cases for the task of segmenting haemorrhages in head CTs. We find all of these approaches are unsuitable for safe segmentation as they provide confidently wrong predictions when operating OOD. We propose performing full 3D OOD detection using a VQ-GAN to provide a compressed latent representation of the image and a transformer to estimate the data likelihood. Our approach successfully identifies images in both the far- and near-OOD cases. We find a strong relationship between image likelihood and the quality of a model's segmentation, making this approach viable for filtering images unsuitable for segmentation. To our knowledge, this is the first time transformers have been applied to perform OOD detection on 3D image data.
Augmentation based unsupervised domain adaptation
Feb 23, 2022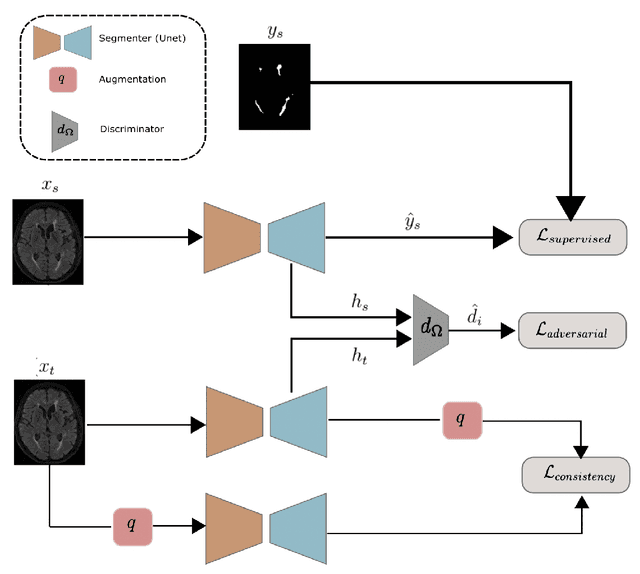

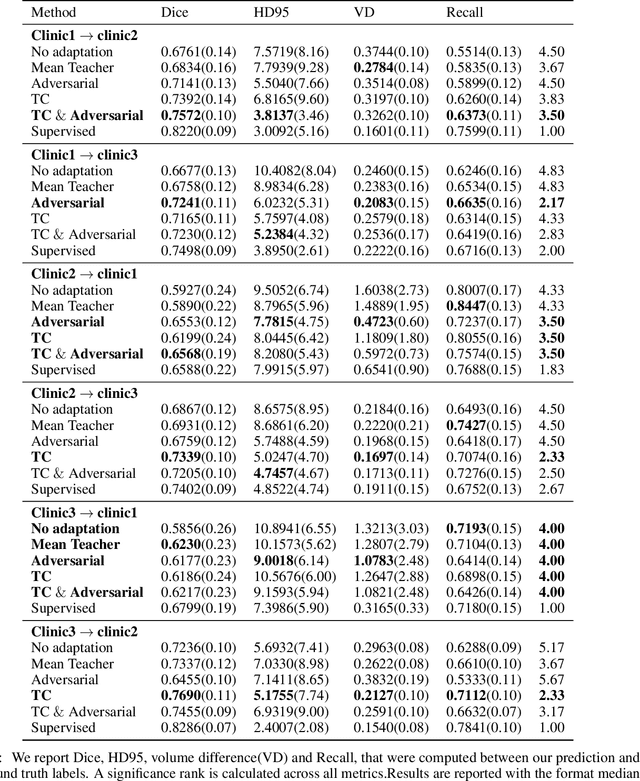
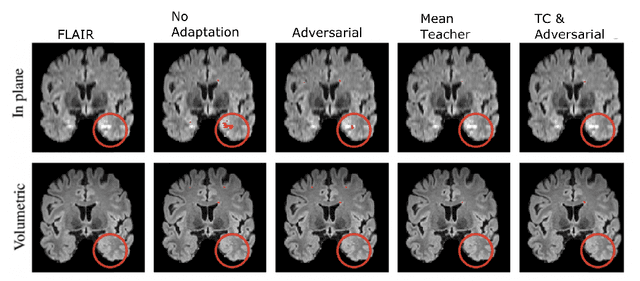
The insertion of deep learning in medical image analysis had lead to the development of state-of-the art strategies in several applications such a disease classification, as well as abnormality detection and segmentation. However, even the most advanced methods require a huge and diverse amount of data to generalize. Because in realistic clinical scenarios, data acquisition and annotation is expensive, deep learning models trained on small and unrepresentative data tend to outperform when deployed in data that differs from the one used for training (e.g data from different scanners). In this work, we proposed a domain adaptation methodology to alleviate this problem in segmentation models. Our approach takes advantage of the properties of adversarial domain adaptation and consistency training to achieve more robust adaptation. Using two datasets with white matter hyperintensities (WMH) annotations, we demonstrated that the proposed method improves model generalization even in corner cases where individual strategies tend to fail.
Acquisition-invariant brain MRI segmentation with informative uncertainties
Nov 07, 2021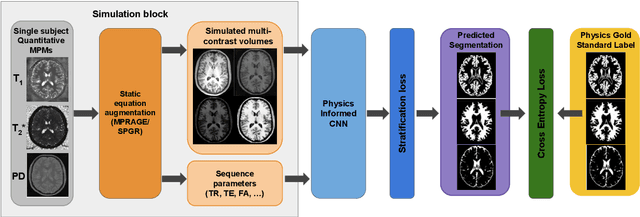
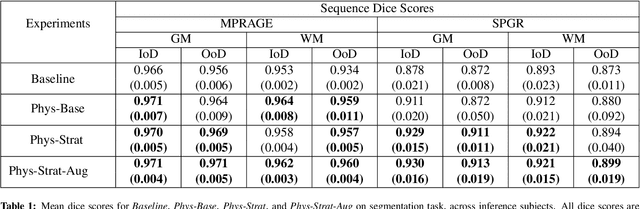
Combining multi-site data can strengthen and uncover trends, but is a task that is marred by the influence of site-specific covariates that can bias the data and therefore any downstream analyses. Post-hoc multi-site correction methods exist but have strong assumptions that often do not hold in real-world scenarios. Algorithms should be designed in a way that can account for site-specific effects, such as those that arise from sequence parameter choices, and in instances where generalisation fails, should be able to identify such a failure by means of explicit uncertainty modelling. This body of work showcases such an algorithm, that can become robust to the physics of acquisition in the context of segmentation tasks, while simultaneously modelling uncertainty. We demonstrate that our method not only generalises to complete holdout datasets, preserving segmentation quality, but does so while also accounting for site-specific sequence choices, which also allows it to perform as a harmonisation tool.
The role of MRI physics in brain segmentation CNNs: achieving acquisition invariance and instructive uncertainties
Nov 04, 2021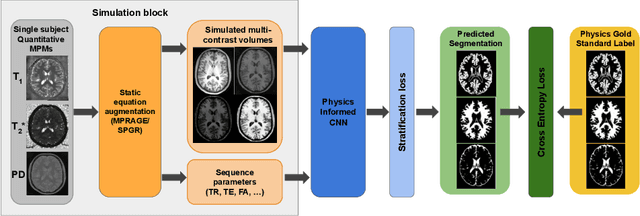
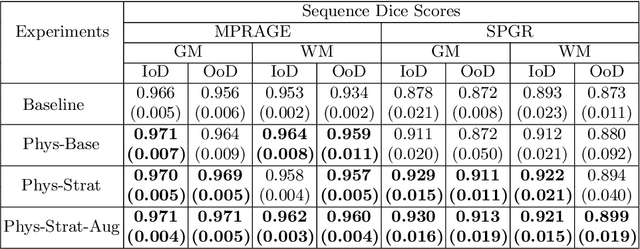
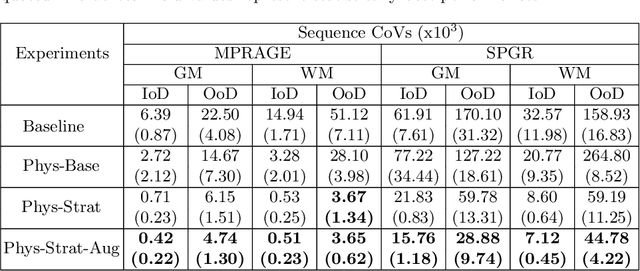
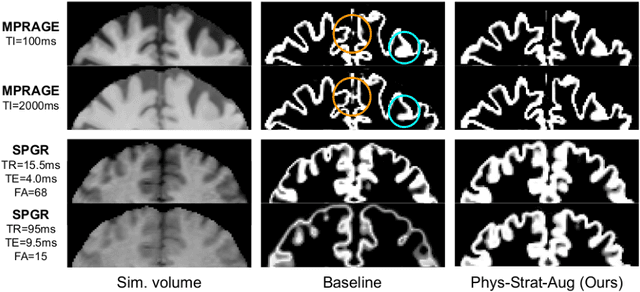
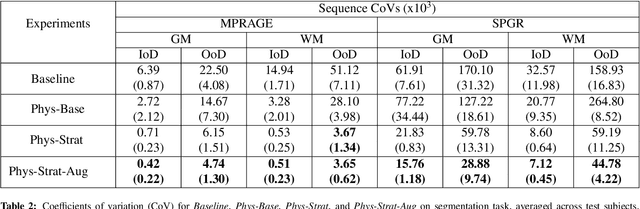
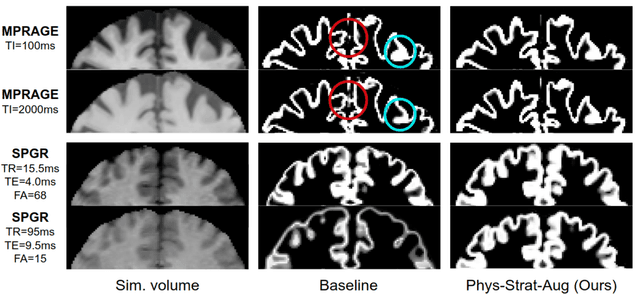
Being able to adequately process and combine data arising from different sites is crucial in neuroimaging, but is difficult, owing to site, sequence and acquisition-parameter dependent biases. It is important therefore to design algorithms that are not only robust to images of differing contrasts, but also be able to generalise well to unseen ones, with a quantifiable measure of uncertainty. In this paper we demonstrate the efficacy of a physics-informed, uncertainty-aware, segmentation network that employs augmentation-time MR simulations and homogeneous batch feature stratification to achieve acquisition invariance. We show that the proposed approach also accurately extrapolates to out-of-distribution sequence samples, providing well calibrated volumetric bounds on these. We demonstrate a significant improvement in terms of coefficients of variation, backed by uncertainty based volumetric validation.
Improved MR to CT synthesis for PET/MR attenuation correction using Imitation Learning
Aug 27, 2019The ability to synthesise Computed Tomography images - commonly known as pseudo CT, or pCT - from MRI input data is commonly assessed using an intensity-wise similarity, such as an L2-norm between the ground truth CT and the pCT. However, given that the ultimate purpose is often to use the pCT as an attenuation map ($\mu$-map) in Positron Emission Tomography Magnetic Resonance Imaging (PET/MRI), minimising the error between pCT and CT is not necessarily optimal. The main objective should be to predict a pCT that, when used as $\mu$-map, reconstructs a pseudo PET (pPET) which is as close as possible to the gold standard PET. To this end, we propose a novel multi-hypothesis deep learning framework that generates pCTs by minimising a combination of the pixel-wise error between pCT and CT and a proposed metric-loss that itself is represented by a convolutional neural network (CNN) and aims to minimise subsequent PET residuals. The model is trained on a database of 400 paired MR/CT/PET image slices. Quantitative results show that the network generates pCTs that seem less accurate when evaluating the Mean Absolute Error on the pCT (69.68HU) compared to a baseline CNN (66.25HU), but lead to significant improvement in the PET reconstruction - 115a.u. compared to baseline 140a.u.
Deep Boosted Regression for MR to CT Synthesis
Aug 22, 2018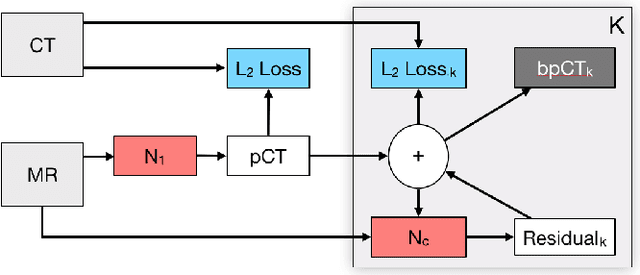

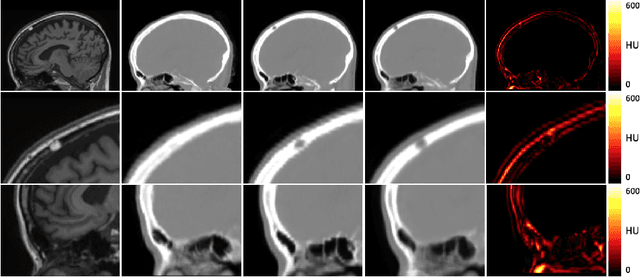
Attenuation correction is an essential requirement of positron emission tomography (PET) image reconstruction to allow for accurate quantification. However, attenuation correction is particularly challenging for PET-MRI as neither PET nor magnetic resonance imaging (MRI) can directly image tissue attenuation properties. MRI-based computed tomography (CT) synthesis has been proposed as an alternative to physics based and segmentation-based approaches that assign a population-based tissue density value in order to generate an attenuation map. We propose a novel deep fully convolutional neural network that generates synthetic CTs in a recursive manner by gradually reducing the residuals of the previous network, increasing the overall accuracy and generalisability, while keeping the number of trainable parameters within reasonable limits. The model is trained on a database of 20 pre-acquired MRI/CT pairs and a four-fold random bootstrapped validation with a 80:20 split is performed. Quantitative results show that the proposed framework outperforms a state-of-the-art atlas-based approach decreasing the Mean Absolute Error (MAE) from 131HU to 68HU for the synthetic CTs and reducing the PET reconstruction error from 14.3% to 7.2%.