 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3D generative model of pathological multi-modal MR images and segmentations
Nov 08, 2023Generative modelling and synthetic data can be a surrogate for real medical imaging datasets, whose scarcity and difficulty to share can be a nuisance when delivering accurate deep learning models for healthcare applications. In recent years, there has been an increased interest in using these models for data augmentation and synthetic data sharing, using architectures such as generative adversarial networks (GANs) or diffusion models (DMs). Nonetheless, the application of synthetic data to tasks such as 3D magnetic resonance imaging (MRI) segmentation remains limited due to the lack of labels associated with the generated images. Moreover, many of the proposed generative MRI models lack the ability to generate arbitrary modalities due to the absence of explicit contrast conditioning. These limitations prevent the user from adjusting the contrast and content of the images and obtaining more generalisable data for training task-specific models. In this work, we propose brainSPADE3D, a 3D generative model for brain MRI and associated segmentations, where the user can condition on specific pathological phenotypes and contrasts. The proposed joint imaging-segmentation generative model is shown to generate high-fidelity synthetic images and associated segmentations, with the ability to combine pathologies. We demonstrate how the model can alleviate issues with segmentation model performance when unexpected pathologies are present in the data.
InverseSR: 3D Brain MRI Super-Resolution Using a Latent Diffusion Model
Aug 23, 2023



High-resolution (HR) MRI scans obtained from research-grade medical centers provide precise information about imaged tissues. However, routine clinical MRI scans are typically in low-resolution (LR) and vary greatly in contrast and spatial resolution due to the adjustments of the scanning parameters to the local needs of the medical center. End-to-end deep learning methods for MRI super-resolution (SR) have been proposed, but they require re-training each time there is a shift in the input distribution. To address this issue, we propose a novel approach that leverages a state-of-the-art 3D brain generative model, the latent diffusion model (LDM) trained on UK BioBank, to increase the resolution of clinical MRI scans. The LDM acts as a generative prior, which has the ability to capture the prior distribution of 3D T1-weighted brain MRI. Based on the architecture of the brain LDM, we find that different methods are suitable for different settings of MRI SR, and thus propose two novel strategies: 1) for SR with more sparsity, we invert through both the decoder of the LDM and also through a deterministic Denoising Diffusion Implicit Models (DDIM), an approach we will call InverseSR(LDM); 2) for SR with less sparsity, we invert only through the LDM decoder, an approach we will call InverseSR(Decoder). These two approaches search different latent spaces in the LDM model to find the optimal latent code to map the given LR MRI into HR. The training process of the generative model is independent of the MRI under-sampling process, ensuring the generalization of our method to many MRI SR problems with different input measurements. We validate our method on over 100 brain T1w MRIs from the IXI dataset. Our method can demonstrate that powerful priors given by LDM can be used for MRI reconstruction.
Unsupervised 3D out-of-distribution detection with latent diffusion models
Jul 07, 2023


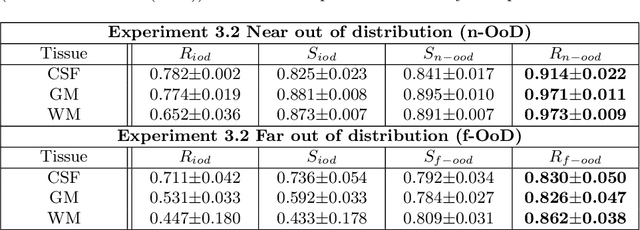
Methods for out-of-distribution (OOD) detection that scale to 3D data are crucial components of any real-world clinical deep learning system. Classic denoising diffusion probabilistic models (DDPMs) have been recently proposed as a robust way to perform reconstruction-based OOD detection on 2D datasets, but do not trivially scale to 3D data. In this work, we propose to use Latent Diffusion Models (LDMs), which enable the scaling of DDPMs to high-resolution 3D medical data. We validate the proposed approach on near- and far-OOD datasets and compare it to a recently proposed, 3D-enabled approach using Latent Transformer Models (LTMs). Not only does the proposed LDM-based approach achieve statistically significant better performance, it also shows less sensitivity to the underlying latent representation, more favourable memory scaling, and produces better spatial anomaly maps. Code is available at https://github.com/marksgraham/ddpm-ood
Privacy Distillation: Reducing Re-identification Risk of Multimodal Diffusion Models
Jun 02, 2023



Knowledge distillation in neural networks refers to compressing a large model or dataset into a smaller version of itself. We introduce Privacy Distillation, a framework that allows a text-to-image generative model to teach another model without exposing it to identifiable data. Here, we are interested in the privacy issue faced by a data provider who wishes to share their data via a multimodal generative model. A question that immediately arises is ``How can a data provider ensure that the generative model is not leaking identifiable information about a patient?''. Our solution consists of (1) training a first diffusion model on real data (2) generating a synthetic dataset using this model and filtering it to exclude images with a re-identifiability risk (3) training a second diffusion model on the filtered synthetic data only. We showcase that datasets sampled from models trained with privacy distillation can effectively reduce re-identification risk whilst maintaining downstream performance.
Can segmentation models be trained with fully synthetically generated data?
Sep 17, 2022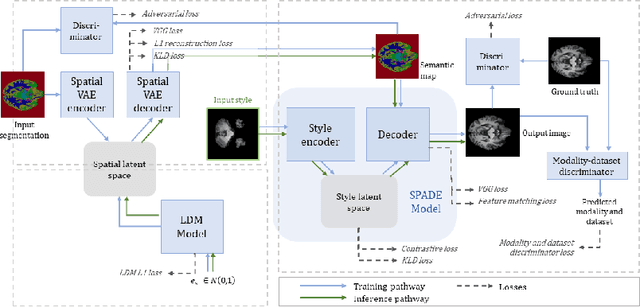

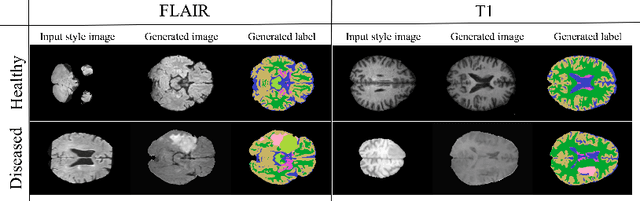
In order to achieve good performance and generalisability, medical image segmentation models should be trained on sizeable datasets with sufficient variability. Due to ethics and governance restrictions, and the costs associated with labelling data, scientific development is often stifled, with models trained and tested on limited data. Data augmentation is often used to artificially increase the variability in the data distribution and improve model generalisability. Recent works have explored deep generative models for image synthesis, as such an approach would enable the generation of an effectively infinite amount of varied data, addressing the generalisability and data access problems. However, many proposed solutions limit the user's control over what is generated. In this work, we propose brainSPADE, a model which combines a synthetic diffusion-based label generator with a semantic image generator. Our model can produce fully synthetic brain labels on-demand, with or without pathology of interest, and then generate a corresponding MRI image of an arbitrary guided style. Experiments show that brainSPADE synthetic data can be used to train segmentation models with performance comparable to that of models trained on real data.
Morphology-preserving Autoregressive 3D Generative Modelling of the Brain
Sep 07, 2022
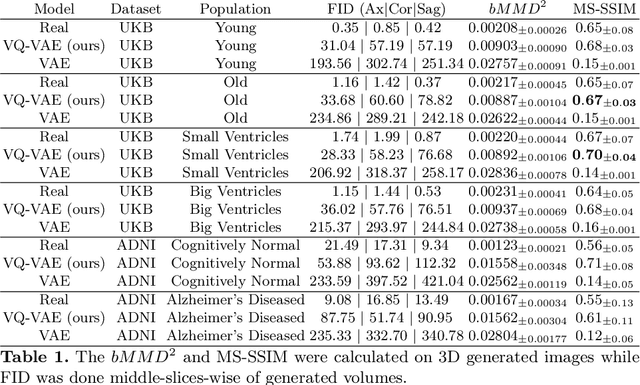
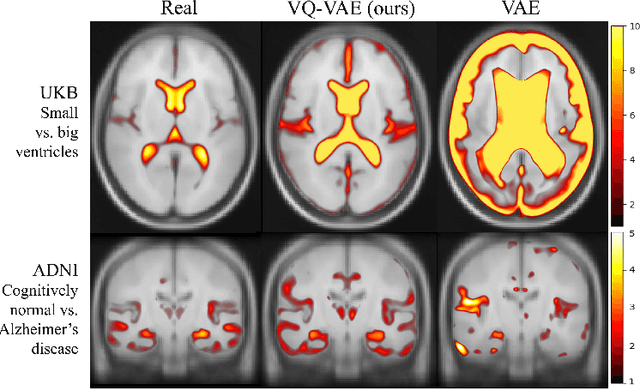
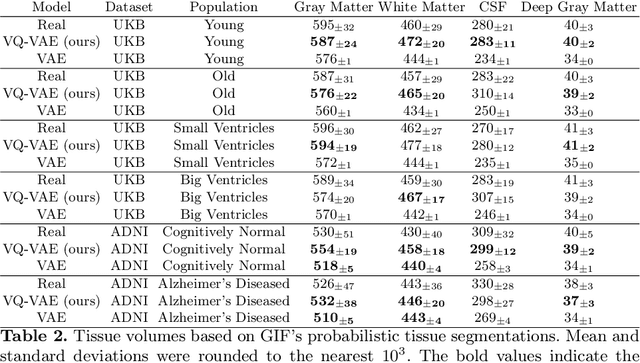
Human anatomy, morphology, and associated diseases can be studied using medical imaging data. However, access to medical imaging data is restricted by governance and privacy concerns, data ownership, and the cost of acquisition, thus limiting our ability to understand the human body. A possible solution to this issue is the creation of a model able to learn and then generate synthetic images of the human body conditioned on specific characteristics of relevance (e.g., age, sex, and disease status). Deep generative models, in the form of neural networks, have been recently used to create synthetic 2D images of natural scenes. Still, the ability to produce high-resolution 3D volumetric imaging data with correct anatomical morphology has been hampered by data scarcity and algorithmic and computational limitations. This work proposes a generative model that can be scaled to produce anatomically correct, high-resolution, and realistic images of the human brain, with the necessary quality to allow further downstream analyses. The ability to generate a potentially unlimited amount of data not only enables large-scale studies of human anatomy and pathology without jeopardizing patient privacy, but also significantly advances research in the field of anomaly detection, modality synthesis, learning under limited data, and fair and ethical AI. Code and trained models are available at: https://github.com/AmigoLab/SynthAnatomy.
Transformer-based out-of-distribution detection for clinically safe segmentation
May 21, 2022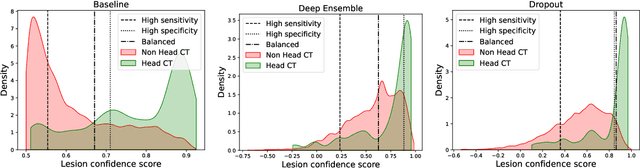
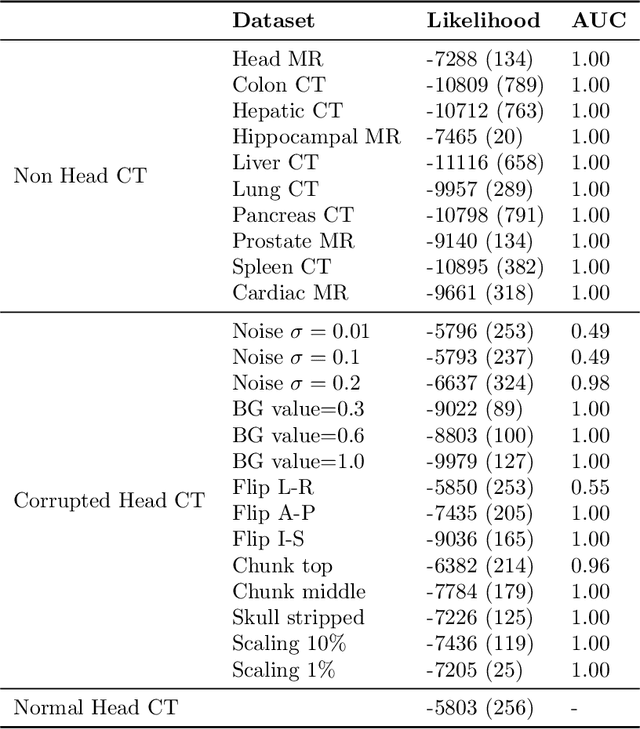
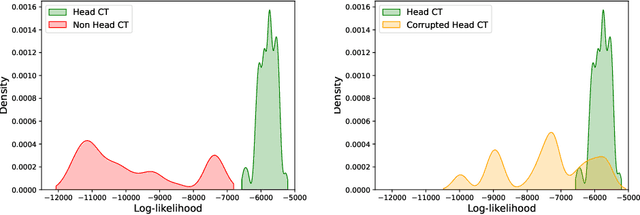
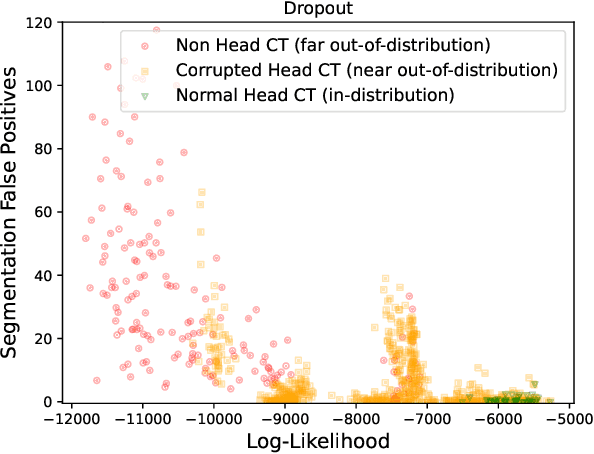
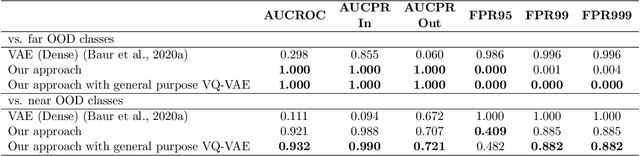
In a clinical setting it is essential that deployed image processing systems are robust to the full range of inputs they might encounter and, in particular, do not make confidently wrong predictions. The most popular approach to safe processing is to train networks that can provide a measure of their uncertainty, but these tend to fail for inputs that are far outside the training data distribution. Recently, generative modelling approaches have been proposed as an alternative; these can quantify the likelihood of a data sample explicitly, filtering out any out-of-distribution (OOD) samples before further processing is performed. In this work, we focus on image segmentation and evaluate several approaches to network uncertainty in the far-OOD and near-OOD cases for the task of segmenting haemorrhages in head CTs. We find all of these approaches are unsuitable for safe segmentation as they provide confidently wrong predictions when operating OOD. We propose performing full 3D OOD detection using a VQ-GAN to provide a compressed latent representation of the image and a transformer to estimate the data likelihood. Our approach successfully identifies images in both the far- and near-OOD cases. We find a strong relationship between image likelihood and the quality of a model's segmentation, making this approach viable for filtering images unsuitable for segmentation. To our knowledge, this is the first time transformers have been applied to perform OOD detection on 3D image data.
Unsupervised Brain Anomaly Detection and Segmentation with Transformers
Feb 23, 2021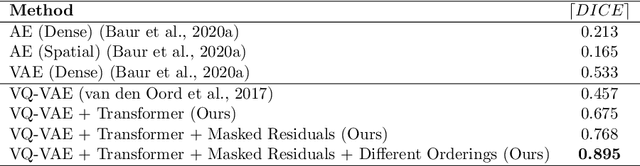
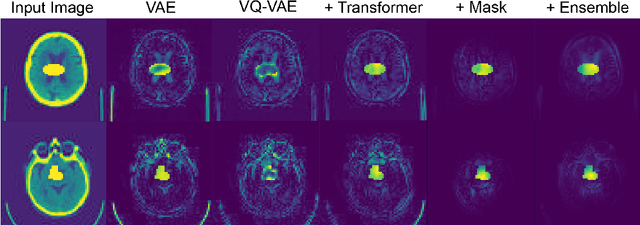
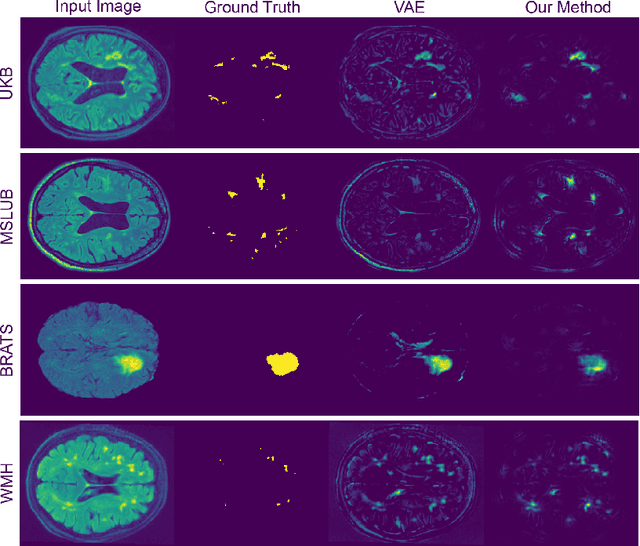
Pathological brain appearances may be so heterogeneous as to be intelligible only as anomalies, defined by their deviation from normality rather than any specific pathological characteristic. Amongst the hardest tasks in medical imaging, detecting such anomalies requires models of the normal brain that combine compactness with the expressivity of the complex, long-range interactions that characterise its structural organisation. These are requirements transformers have arguably greater potential to satisfy than other current candidate architectures, but their application has been inhibited by their demands on data and computational resource. Here we combine the latent representation of vector quantised variational autoencoders with an ensemble of autoregressive transformers to enable unsupervised anomaly detection and segmentation defined by deviation from healthy brain imaging data, achievable at low computational cost, within relative modest data regimes. We compare our method to current state-of-the-art approaches across a series of experiments involving synthetic and real pathological lesions. On real lesions, we train our models on 15,000 radiologically normal participants from UK Biobank, and evaluate performance on four different brain MR datasets with small vessel disease, demyelinating lesions, and tumours. We demonstrate superior anomaly detection performance both image-wise and pixel-wise, achievable without post-processing. These results draw attention to the potential of transformers in this most challenging of imaging tasks.