 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHessian Matching for Machine-Learned Coarse-Grained Molecular Dynamics
May 12, 2026Coarse-grained (CG) molecular dynamics enables simulations of atomic systems such as biomolecules at timescales inaccessible to all-atom (AA) methods, but existing CG neural potentials trained via force matching capture only the gradient of the free-energy surface, leaving its curvature unconstrained. We introduce a framework that augments force matching with stochastic Hessian-vector product (HVP) matching, instilling second-order curvature information into CG potentials without constructing the full Hessian. We derive a decomposition of the target CG Hessian into a model-independent projected AA Hessian, precomputed once before training, and a model-dependent covariance correction computed online at negligible cost. We construct an unbiased stochastic estimator of the Hessian-matching objective by using random probe vectors. We evaluate our method by comparing against force matching on a benchmark of nine fast-folding proteins unseen during training. HVP matching outperforms plain force matching on 8 of 9 proteins on slow-mode metrics, with reductions of up to 85% in the Kullback--Leibler divergence between the CG and reference distributions along the slowest collective mode of the largest protein. Our results demonstrate that higher-order physical supervision is a practical path to more accurate and transferable CG potentials for biomolecular simulation.
Spinverse: Differentiable Physics for Permeability-Aware Microstructure Reconstruction from Diffusion MRI
Mar 04, 2026Diffusion MRI (dMRI) is sensitive to microstructural barriers, yet most existing methods either assume impermeable boundaries or estimate voxel-level parameters without recovering explicit interfaces. We present Spinverse, a permeability-aware reconstruction method that inverts dMRI measurements through a fully differentiable Bloch-Torrey simulator. Spinverse represents tissue on a fixed tetrahedral grid and treats each interior face permeability as a learnable parameter; low-permeability faces act as diffusion barriers, so microstructural boundaries whose topology is not fixed a priori (up to the resolution of the ambient mesh) emerge without changing mesh connectivity or vertex positions. Given a target signal, we optimize face permeabilities by backpropagating a signal-matching loss through the PDE forward model, and recover an interface by thresholding the learned permeability field. To mitigate the ill-posedness of permeability inversion, we use mesh-based geometric priors; to avoid local minima, we use a staged multi-sequence optimization curriculum. Across a collection of synthetic voxel meshes, Spinverse reconstructs diverse geometries and demonstrates that sequence scheduling and regularization are critical to avoid outline-only solutions while improving both boundary accuracy and structural validity.
Holographic generative flows with AdS/CFT
Jan 29, 2026We present a framework for generative machine learning that leverages the holographic principle of quantum gravity, or to be more precise its manifestation as the anti-de Sitter/conformal field theory (AdS/CFT) correspondence, with techniques for deep learning and transport theory. Our proposal is to represent the flow of data from a base distribution to some learned distribution using the bulk-to-boundary mapping of scalar fields in AdS. In the language of machine learning, we are representing and augmenting the flow-matching algorithm with AdS physics. Using a checkerboard toy dataset and MNIST, we find that our model achieves faster and higher quality convergence than comparable physics-free flow-matching models. Our method provides a physically interpretable version of flow matching. More broadly, it establishes the utility of AdS physics and geometry in the development of novel paradigms in generative modeling.
Automatic Replication of LLM Mistakes in Medical Conversations
Dec 24, 2025Large language models (LLMs) are increasingly evaluated in clinical settings using multi-dimensional rubrics which quantify reasoning quality, safety, and patient-centeredness. Yet, replicating specific mistakes in other LLM models is not straightforward and often requires manual effort. We introduce MedMistake, an automatic pipeline that extracts mistakes LLMs make in patient-doctor conversations and converts them into a benchmark of single-shot QA pairs. Our pipeline (1) creates complex, conversational data between an LLM patient and LLM doctor, (2) runs an evaluation with a committee of 2 LLM judges across a variety of dimensions and (3) creates simplified single-shot QA scenarios from those mistakes. We release MedMistake-All, a dataset of 3,390 single-shot QA pairs where GPT-5 and Gemini 2.5 Pro are currently failing to answer correctly, as judged by two LLM judges. We used medical experts to validate a subset of 211/3390 questions (MedMistake-Bench), which we used to run a final evaluation of 12 frontier LLMs: Claude Opus 4.5, Claude Sonnet 4.5, DeepSeek-Chat, Gemini 2.5 Pro, Gemini 3 Pro, GPT-4o, GPT-5, GPT-5.1, GPT-5.2, Grok 4, Grok 4.1, Mistral Large. We found that GPT models, Claude and Grok obtained the best performance on MedMistake-Bench. We release both the doctor-validated benchmark (MedMistake-Bench), as well as the full dataset (MedMistake-All) at https://huggingface.co/datasets/TheLumos/MedicalMistakeBenchmark.
A Women's Health Benchmark for Large Language Models
Dec 18, 2025As large language models (LLMs) become primary sources of health information for millions, their accuracy in women's health remains critically unexamined. We introduce the Women's Health Benchmark (WHB), the first benchmark evaluating LLM performance specifically in women's health. Our benchmark comprises 96 rigorously validated model stumps covering five medical specialties (obstetrics and gynecology, emergency medicine, primary care, oncology, and neurology), three query types (patient query, clinician query, and evidence/policy query), and eight error types (dosage/medication errors, missing critical information, outdated guidelines/treatment recommendations, incorrect treatment advice, incorrect factual information, missing/incorrect differential diagnosis, missed urgency, and inappropriate recommendations). We evaluated 13 state-of-the-art LLMs and revealed alarming gaps: current models show approximately 60\% failure rates on the women's health benchmark, with performance varying dramatically across specialties and error types. Notably, models universally struggle with "missed urgency" indicators, while newer models like GPT-5 show significant improvements in avoiding inappropriate recommendations. Our findings underscore that AI chatbots are not yet fully able of providing reliable advice in women's health.
TICA-Based Free Energy Matching for Machine-Learned Molecular Dynamics
Sep 18, 2025Molecular dynamics (MD) simulations provide atomistic insight into biomolecular systems but are often limited by high computational costs required to access long timescales. Coarse-grained machine learning models offer a promising avenue for accelerating sampling, yet conventional force matching approaches often fail to capture the full thermodynamic landscape as fitting a model on the gradient may not fit the absolute differences between low-energy conformational states. In this work, we incorporate a complementary energy matching term into the loss function. We evaluate our framework on the Chignolin protein using the CGSchNet model, systematically varying the weight of the energy loss term. While energy matching did not yield statistically significant improvements in accuracy, it revealed distinct tendencies in how models generalize the free energy surface. Our results suggest future opportunities to enhance coarse-grained modeling through improved energy estimation techniques and multi-modal loss formulations.
ReMiDi: Reconstruction of Microstructure Using a Differentiable Diffusion MRI Simulator
Feb 04, 2025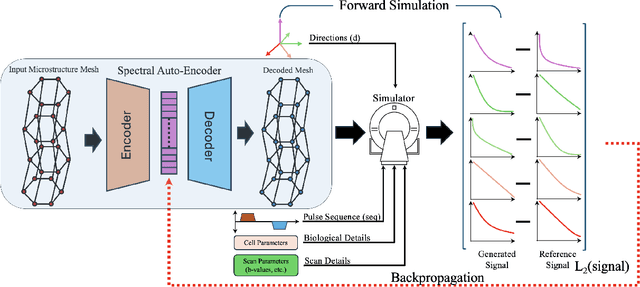

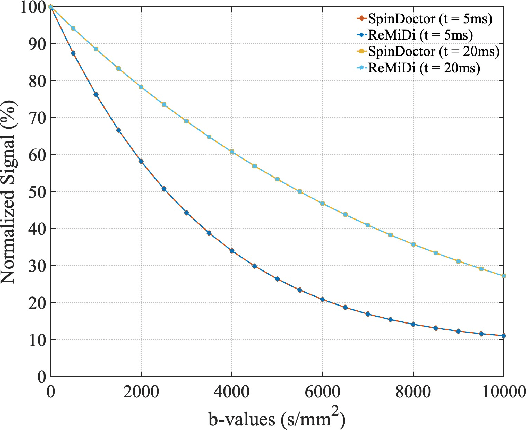
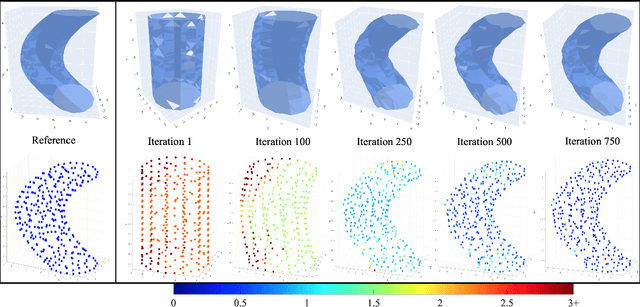
We propose ReMiDi, a novel method for inferring neuronal microstructure as arbitrary 3D meshes using a differentiable diffusion Magnetic Resonance Imaging (dMRI) simulator. We first implemented in PyTorch a differentiable dMRI simulator that simulates the forward diffusion process using a finite-element method on an input 3D microstructure mesh. To achieve significantly faster simulations, we solve the differential equation semi-analytically using a matrix formalism approach. Given a reference dMRI signal $S_{ref}$, we use the differentiable simulator to iteratively update the input mesh such that it matches $S_{ref}$ using gradient-based learning. Since directly optimizing the 3D coordinates of the vertices is challenging, particularly due to ill-posedness of the inverse problem, we instead optimize a lower-dimensional latent space representation of the mesh. The mesh is first encoded into spectral coefficients, which are further encoded into a latent $\textbf{z}$ using an auto-encoder, and are then decoded back into the true mesh. We present an end-to-end differentiable pipeline that simulates signals that can be tuned to match a reference signal by iteratively updating the latent representation $\textbf{z}$. We demonstrate the ability to reconstruct microstructures of arbitrary shapes represented by finite-element meshes, with a focus on axonal geometries found in the brain white matter, including bending, fanning and beading fibers. Our source code will be made available online.
Language Models for Music Medicine Generation
Nov 13, 2024
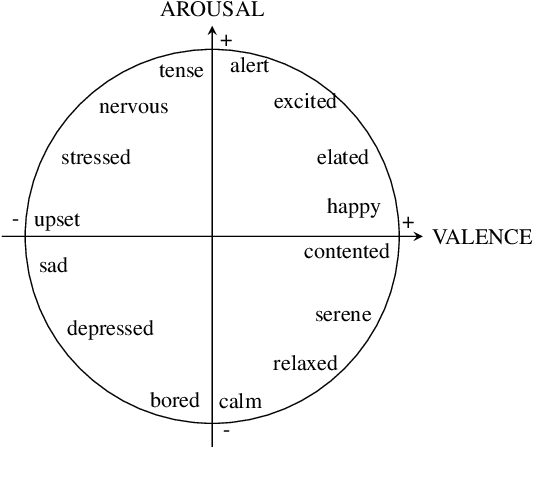
Music therapy has been shown in recent years to provide multiple health benefits related to emotional wellness. In turn, maintaining a healthy emotional state has proven to be effective for patients undergoing treatment, such as Parkinson's patients or patients suffering from stress and anxiety. We propose fine-tuning MusicGen, a music-generating transformer model, to create short musical clips that assist patients in transitioning from negative to desired emotional states. Using low-rank decomposition fine-tuning on the MTG-Jamendo Dataset with emotion tags, we generate 30-second clips that adhere to the iso principle, guiding patients through intermediate states in the valence-arousal circumplex. The generated music is evaluated using a music emotion recognition model to ensure alignment with intended emotions. By concatenating these clips, we produce a 15-minute "music medicine" resembling a music therapy session. Our approach is the first model to leverage Language Models to generate music medicine. Ultimately, the output is intended to be used as a temporary relief between music therapy sessions with a board-certified therapist.
AFEN: Respiratory Disease Classification using Ensemble Learning
May 08, 2024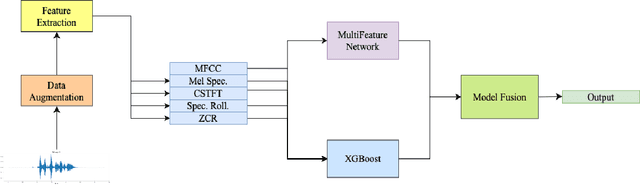

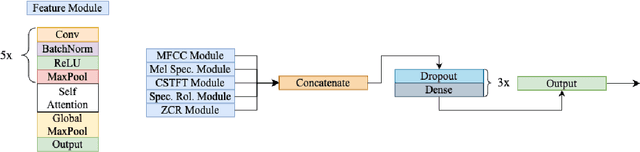
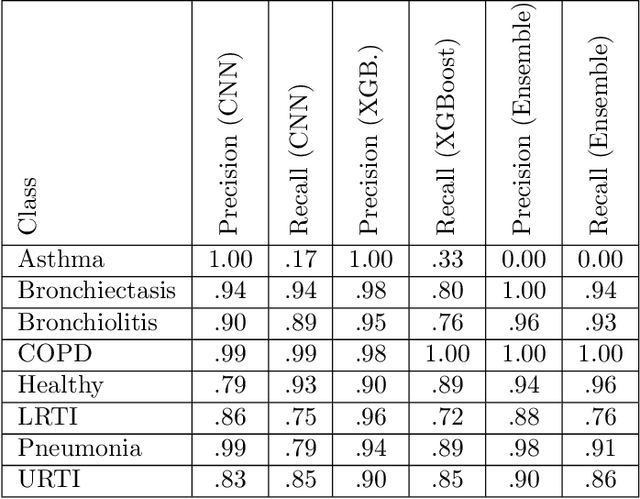
We present AFEN (Audio Feature Ensemble Learning), a model that leverages Convolutional Neural Networks (CNN) and XGBoost in an ensemble learning fashion to perform state-of-the-art audio classification for a range of respiratory diseases. We use a meticulously selected mix of audio features which provide the salient attributes of the data and allow for accurate classification. The extracted features are then used as an input to two separate model classifiers 1) a multi-feature CNN classifier and 2) an XGBoost Classifier. The outputs of the two models are then fused with the use of soft voting. Thus, by exploiting ensemble learning, we achieve increased robustness and accuracy. We evaluate the performance of the model on a database of 920 respiratory sounds, which undergoes data augmentation techniques to increase the diversity of the data and generalizability of the model. We empirically verify that AFEN sets a new state-of-the-art using Precision and Recall as metrics, while decreasing training time by 60%.
BMapOpt: Optimization of Brain Tissue Probability Maps using a Differentiable MRI Simulator
Apr 23, 2024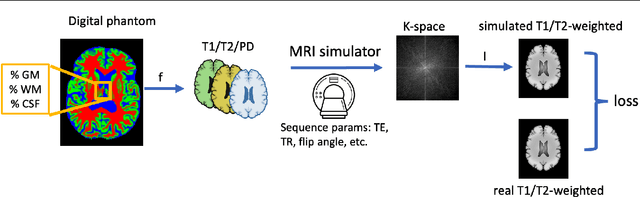
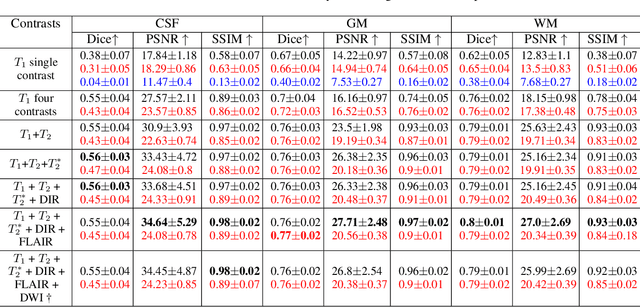
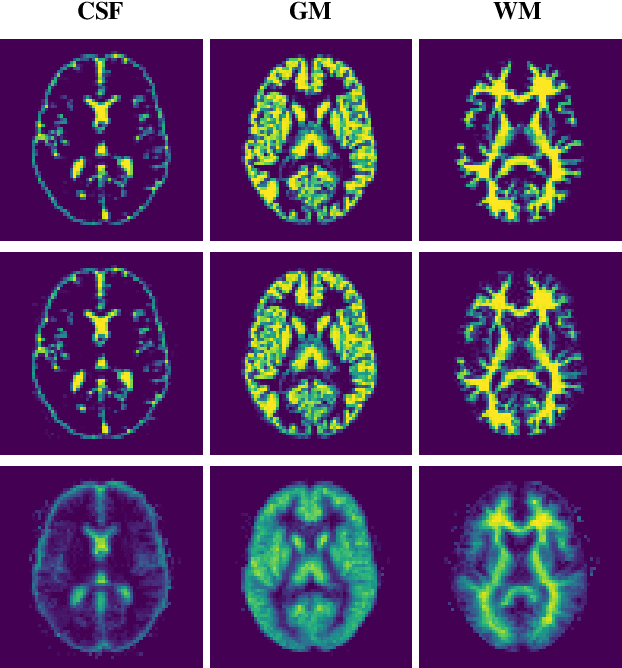
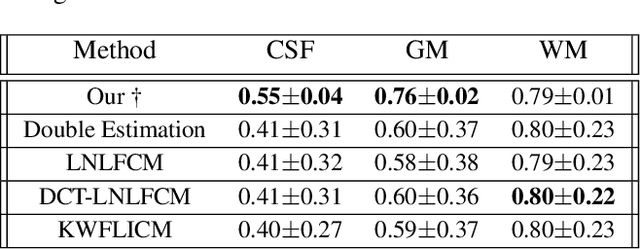
Reconstructing digital brain phantoms in the form of multi-channeled brain tissue probability maps for individual subjects is essential for capturing brain anatomical variability, understanding neurological diseases, as well as for testing image processing methods. We demonstrate the first framework that optimizes brain tissue probability maps (Gray Matter - GM, White Matter - WM, and Cerebrospinal fluid - CSF) with the help of a Physics-based differentiable MRI simulator that models the magnetization signal at each voxel in the image. Given an observed $T_1$/$T_2$-weighted MRI scan, the corresponding clinical MRI sequence, and the MRI differentiable simulator, we optimize the simulator's input probability maps by back-propagating the L2 loss between the simulator's output and the $T_1$/$T_2$-weighted scan. This approach has the significant advantage of not relying on any training data, and instead uses the strong inductive bias of the MRI simulator. We tested the model on 20 scans from the BrainWeb database and demonstrate a highly accurate reconstruction of GM, WM, and CSF.