 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFEN: Respiratory Disease Classification using Ensemble Learning
Paper and Code
May 08, 2024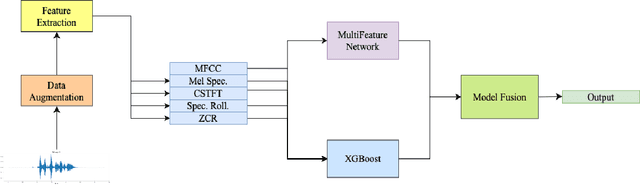

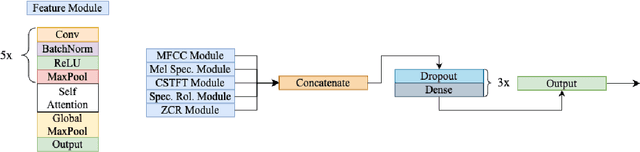
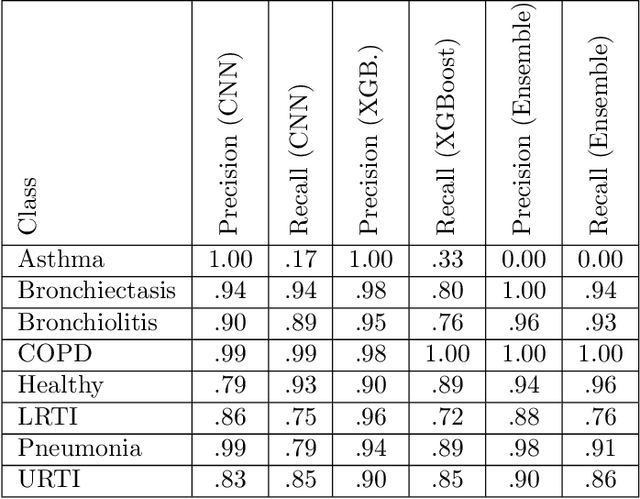
We present AFEN (Audio Feature Ensemble Learning), a model that leverages Convolutional Neural Networks (CNN) and XGBoost in an ensemble learning fashion to perform state-of-the-art audio classification for a range of respiratory diseases. We use a meticulously selected mix of audio features which provide the salient attributes of the data and allow for accurate classification. The extracted features are then used as an input to two separate model classifiers 1) a multi-feature CNN classifier and 2) an XGBoost Classifier. The outputs of the two models are then fused with the use of soft voting. Thus, by exploiting ensemble learning, we achieve increased robustness and accuracy. We evaluate the performance of the model on a database of 920 respiratory sounds, which undergoes data augmentation techniques to increase the diversity of the data and generalizability of the model. We empirically verify that AFEN sets a new state-of-the-art using Precision and Recall as metrics, while decreasing training time by 60%.