 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Music Source Restoration with BandSplit-RoFormer Separation and HiFi++ GAN
Mar 04, 2026Music Source Restoration (MSR) targets recovery of original, unprocessed instrument stems from fully mixed and mastered audio, where production effects and distribution artifacts violate common linear-mixture assumptions. This technical report presents the CP-JKU team's system for the MSR ICASSP Challenge 2025. Our approach decomposes MSR into separation and restoration. First, a single BandSplit-RoFormer separator predicts eight stems plus an auxiliary other stem, and is trained with a three-stage curriculum that progresses from 4-stem warm-start fine-tuning (with LoRA) to 8-stem extension via head expansion. Second, we apply a HiFi++ GAN waveform restorer trained as a generalist and then specialized into eight instrument-specific experts.
How Far Can Pretrained LLMs Go in Symbolic Music? Controlled Comparisons of Supervised and Preference-based Adaptation
Jan 30, 2026Music often shares notable parallels with language, motivating the use of pretrained large language models (LLMs) for symbolic music understanding and generation. Despite growing interest, the practical effectiveness of adapting instruction-tuned LLMs to symbolic music remains insufficiently characterized. We present a controlled comparative study of finetuning strategies for ABC-based generation and understanding, comparing an off-the-shelf instruction-tuned backbone to domain-adapted variants and a music-specialized LLM baseline. Across multiple symbolic music corpora and evaluation signals, we provide some insights into adaptation choices for symbolic music applications. We highlight the domain adaptation vs.~preserving prior information tradeoff as well as the distinct behaviour of metrics used to measure the domain adaptation for symbolic music.
Sound Event Detection with Boundary-Aware Optimization and Inference
Jan 07, 2026Temporal detection problems appear in many fields including time-series estimation, activity recognition and sound event detection (SED). In this work, we propose a new approach to temporal event modeling by explicitly modeling event onsets and offsets, and by introducing boundary-aware optimization and inference strategies that substantially enhance temporal event detection. The presented methodology incorporates new temporal modeling layers - Recurrent Event Detection (RED) and Event Proposal Network (EPN) - which, together with tailored loss functions, enable more effective and precise temporal event detection. We evaluate the proposed method in the SED domain using a subset of the temporally-strongly annotated portion of AudioSet. Experimental results show that our approach not only outperforms traditional frame-wise SED models with state-of-the-art post-processing, but also removes the need for post-processing hyperparameter tuning, and scales to achieve new state-of-the-art performance across all AudioSet Strong classes.
Sound and Music Biases in Deep Music Transcription Models: A Systematic Analysis
Dec 16, 2025Automatic Music Transcription (AMT) -- the task of converting music audio into note representations -- has seen rapid progress, driven largely by deep learning systems. Due to the limited availability of richly annotated music datasets, much of the progress in AMT has been concentrated on classical piano music, and even a few very specific datasets. Whether these systems can generalize effectively to other musical contexts remains an open question. Complementing recent studies on distribution shifts in sound (e.g., recording conditions), in this work we investigate the musical dimension -- specifically, variations in genre, dynamics, and polyphony levels. To this end, we introduce the MDS corpus, comprising three distinct subsets -- (1) Genre, (2) Random, and (3) MAEtest -- to emulate different axes of distribution shift. We evaluate the performance of several state-of-the-art AMT systems on the MDS corpus using both traditional information-retrieval and musically-informed performance metrics. Our extensive evaluation isolates and exposes varying degrees of performance degradation under specific distribution shifts. In particular, we measure a note-level F1 performance drop of 20 percentage points due to sound, and 14 due to genre. Generally, we find that dynamics estimation proves more vulnerable to musical variation than onset prediction. Musically informed evaluation metrics, particularly those capturing harmonic structure, help identify potential contributing factors. Furthermore, experiments with randomly generated, non-musical sequences reveal clear limitations in system performance under extreme musical distribution shifts. Altogether, these findings offer new evidence of the persistent impact of the Corpus Bias problem in deep AMT systems.
Perceptually Aligning Representations of Music via Noise-Augmented Autoencoders
Nov 10, 2025We argue that training autoencoders to reconstruct inputs from noised versions of their encodings, when combined with perceptual losses, yields encodings that are structured according to a perceptual hierarchy. We demonstrate the emergence of this hierarchical structure by showing that, after training an audio autoencoder in this manner, perceptually salient information is captured in coarser representation structures than with conventional training. Furthermore, we show that such perceptual hierarchies improve latent diffusion decoding in the context of estimating surprisal in music pitches and predicting EEG-brain responses to music listening. Pretrained weights are available on github.com/CPJKU/pa-audioic.
A Study on the Data Distribution Gap in Music Emotion Recognition
Oct 06, 2025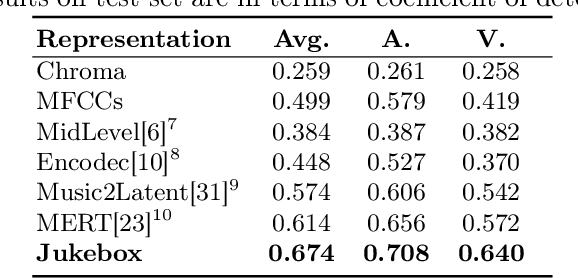
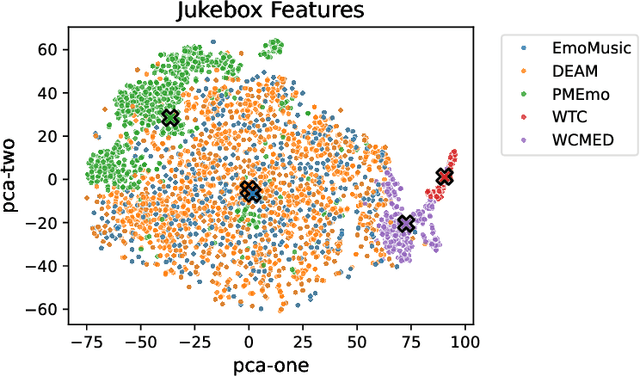
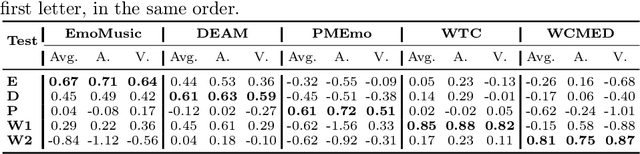
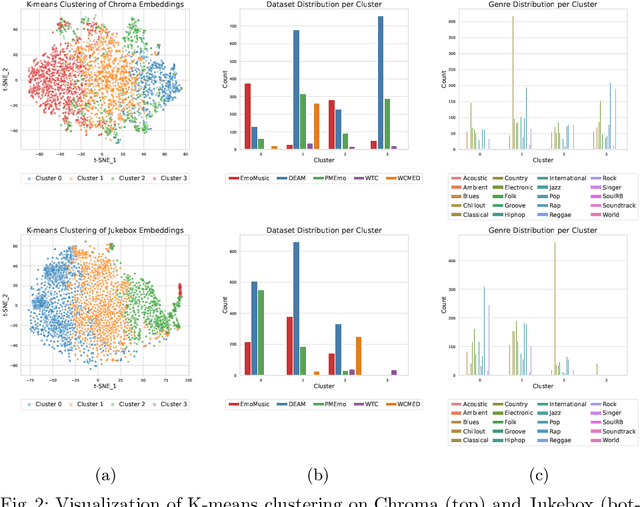
Music Emotion Recognition (MER) is a task deeply connected to human perception, relying heavily on subjective annotations collected from contributors. Prior studies tend to focus on specific musical styles rather than incorporating a diverse range of genres, such as rock and classical, within a single framework. In this paper, we address the task of recognizing emotion from audio content by investigating five datasets with dimensional emotion annotations -- EmoMusic, DEAM, PMEmo, WTC, and WCMED -- which span various musical styles. We demonstrate the problem of out-of-distribution generalization in a systematic experiment. By closely looking at multiple data and feature sets, we provide insight into genre-emotion relationships in existing data and examine potential genre dominance and dataset biases in certain feature representations. Based on these experiments, we arrive at a simple yet effective framework that combines embeddings extracted from the Jukebox model with chroma features and demonstrate how, alongside a combination of several diverse training sets, this permits us to train models with substantially improved cross-dataset generalization capabilities.
MUSE-Explainer: Counterfactual Explanations for Symbolic Music Graph Classification Models
Sep 30, 2025Interpretability is essential for deploying deep learning models in symbolic music analysis, yet most research emphasizes model performance over explanation. To address this, we introduce MUSE-Explainer, a new method that helps reveal how music Graph Neural Network models make decisions by providing clear, human-friendly explanations. Our approach generates counterfactual explanations by making small, meaningful changes to musical score graphs that alter a model's prediction while ensuring the results remain musically coherent. Unlike existing methods, MUSE-Explainer tailors its explanations to the structure of musical data and avoids unrealistic or confusing outputs. We evaluate our method on a music analysis task and show it offers intuitive insights that can be visualized with standard music tools such as Verovio.
Exploring System Adaptations For Minimum Latency Real-Time Piano Transcription
Sep 09, 2025Advances in neural network design and the availability of large-scale labeled datasets have driven major improvements in piano transcription. Existing approaches target either offline applications, with no restrictions on computational demands, or online transcription, with delays of 128-320 ms. However, most real-time musical applications require latencies below 30 ms. In this work, we investigate whether and how the current state-of-the-art online transcription model can be adapted for real-time piano transcription. Specifically, we eliminate all non-causal processing, and reduce computational load through shared computations across core model components and variations in model size. Additionally, we explore different pre- and postprocessing strategies, and related label encoding schemes, and discuss their suitability for real-time transcription. Evaluating the adaptions on the MAESTRO dataset, we find a drop in transcription accuracy due to strictly causal processing as well as a tradeoff between the preprocessing latency and prediction accuracy. We release our system as a baseline to support researchers in designing models towards minimum latency real-time transcription.
Estimating Musical Surprisal from Audio in Autoregressive Diffusion Model Noise Spaces
Aug 07, 2025Recently, the information content (IC) of predictions from a Generative Infinite-Vocabulary Transformer (GIVT) has been used to model musical expectancy and surprisal in audio. We investigate the effectiveness of such modelling using IC calculated with autoregressive diffusion models (ADMs). We empirically show that IC estimates of models based on two different diffusion ordinary differential equations (ODEs) describe diverse data better, in terms of negative log-likelihood, than a GIVT. We evaluate diffusion model IC's effectiveness in capturing surprisal aspects by examining two tasks: (1) capturing monophonic pitch surprisal, and (2) detecting segment boundaries in multi-track audio. In both tasks, the diffusion models match or exceed the performance of a GIVT. We hypothesize that the surprisal estimated at different diffusion process noise levels corresponds to the surprisal of music and audio features present at different audio granularities. Testing our hypothesis, we find that, for appropriate noise levels, the studied musical surprisal tasks' results improve. Code is provided on github.com/SonyCSLParis/audioic.
On Temporal Guidance and Iterative Refinement in Audio Source Separation
Jul 23, 2025Spatial semantic segmentation of sound scenes (S5) involves the accurate identification of active sound classes and the precise separation of their sources from complex acoustic mixtures. Conventional systems rely on a two-stage pipeline - audio tagging followed by label-conditioned source separation - but are often constrained by the absence of fine-grained temporal information critical for effective separation. In this work, we address this limitation by introducing a novel approach for S5 that enhances the synergy between the event detection and source separation stages. Our key contributions are threefold. First, we fine-tune a pre-trained Transformer to detect active sound classes. Second, we utilize a separate instance of this fine-tuned Transformer to perform sound event detection (SED), providing the separation module with detailed, time-varying guidance. Third, we implement an iterative refinement mechanism that progressively enhances separation quality by recursively reusing the separator's output from previous iterations. These advancements lead to significant improvements in both audio tagging and source separation performance, as demonstrated by our system's second-place finish in Task 4 of the DCASE Challenge 2025. Our implementation and model checkpoints are available in our GitHub repository: https://github.com/theMoro/dcase25task4 .