 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Timbre Transfer Via Mutual Information Guided Inpainting
Jan 03, 2026We study timbre transfer as an inference-time editing problem for music audio. Starting from a strong pre-trained latent diffusion model, we introduce a lightweight procedure that requires no additional training: (i) a dimension-wise noise injection that targets latent channels most informative of instrument identity, and (ii) an early-step clamping mechanism that re-imposes the input's melodic and rhythmic structure during reverse diffusion. The method operates directly on audio latents and is compatible with text/audio conditioning (e.g., CLAP). We discuss design choices,analyze trade-offs between timbral change and structural preservation, and show that simple inference-time controls can meaningfully steer pre-trained models for style-transfer use cases.
Perceptually Aligning Representations of Music via Noise-Augmented Autoencoders
Nov 10, 2025We argue that training autoencoders to reconstruct inputs from noised versions of their encodings, when combined with perceptual losses, yields encodings that are structured according to a perceptual hierarchy. We demonstrate the emergence of this hierarchical structure by showing that, after training an audio autoencoder in this manner, perceptually salient information is captured in coarser representation structures than with conventional training. Furthermore, we show that such perceptual hierarchies improve latent diffusion decoding in the context of estimating surprisal in music pitches and predicting EEG-brain responses to music listening. Pretrained weights are available on github.com/CPJKU/pa-audioic.
Estimating Musical Surprisal from Audio in Autoregressive Diffusion Model Noise Spaces
Aug 07, 2025Recently, the information content (IC) of predictions from a Generative Infinite-Vocabulary Transformer (GIVT) has been used to model musical expectancy and surprisal in audio. We investigate the effectiveness of such modelling using IC calculated with autoregressive diffusion models (ADMs). We empirically show that IC estimates of models based on two different diffusion ordinary differential equations (ODEs) describe diverse data better, in terms of negative log-likelihood, than a GIVT. We evaluate diffusion model IC's effectiveness in capturing surprisal aspects by examining two tasks: (1) capturing monophonic pitch surprisal, and (2) detecting segment boundaries in multi-track audio. In both tasks, the diffusion models match or exceed the performance of a GIVT. We hypothesize that the surprisal estimated at different diffusion process noise levels corresponds to the surprisal of music and audio features present at different audio granularities. Testing our hypothesis, we find that, for appropriate noise levels, the studied musical surprisal tasks' results improve. Code is provided on github.com/SonyCSLParis/audioic.
Assessing the Alignment of Audio Representations with Timbre Similarity Ratings
Jul 10, 2025Psychoacoustical so-called "timbre spaces" map perceptual similarity ratings of instrument sounds onto low-dimensional embeddings via multidimensional scaling, but suffer from scalability issues and are incapable of generalization. Recent results from audio (music and speech) quality assessment as well as image similarity have shown that deep learning is able to produce embeddings that align well with human perception while being largely free from these constraints. Although the existing human-rated timbre similarity data is not large enough to train deep neural networks (2,614 pairwise ratings on 334 audio samples), it can serve as test-only data for audio models. In this paper, we introduce metrics to assess the alignment of diverse audio representations with human judgments of timbre similarity by comparing both the absolute values and the rankings of embedding distances to human similarity ratings. Our evaluation involves three signal-processing-based representations, twelve representations extracted from pre-trained models, and three representations extracted from a novel sound matching model. Among them, the style embeddings inspired by image style transfer, extracted from the CLAP model and the sound matching model, remarkably outperform the others, showing their potential in modeling timbre similarity.
Music2Latent2: Audio Compression with Summary Embeddings and Autoregressive Decoding
Jan 29, 2025Efficiently compressing high-dimensional audio signals into a compact and informative latent space is crucial for various tasks, including generative modeling and music information retrieval (MIR). Existing audio autoencoders, however, often struggle to achieve high compression ratios while preserving audio fidelity and facilitating efficient downstream applications. We introduce Music2Latent2, a novel audio autoencoder that addresses these limitations by leveraging consistency models and a novel approach to representation learning based on unordered latent embeddings, which we call summary embeddings. Unlike conventional methods that encode local audio features into ordered sequences, Music2Latent2 compresses audio signals into sets of summary embeddings, where each embedding can capture distinct global features of the input sample. This enables to achieve higher reconstruction quality at the same compression ratio. To handle arbitrary audio lengths, Music2Latent2 employs an autoregressive consistency model trained on two consecutive audio chunks with causal masking, ensuring coherent reconstruction across segment boundaries. Additionally, we propose a novel two-step decoding procedure that leverages the denoising capabilities of consistency models to further refine the generated audio at no additional cost. Our experiments demonstrate that Music2Latent2 outperforms existing continuous audio autoencoders regarding audio quality and performance on downstream tasks. Music2Latent2 paves the way for new possibilities in audio compression.
Estimating Musical Surprisal in Audio
Jan 13, 2025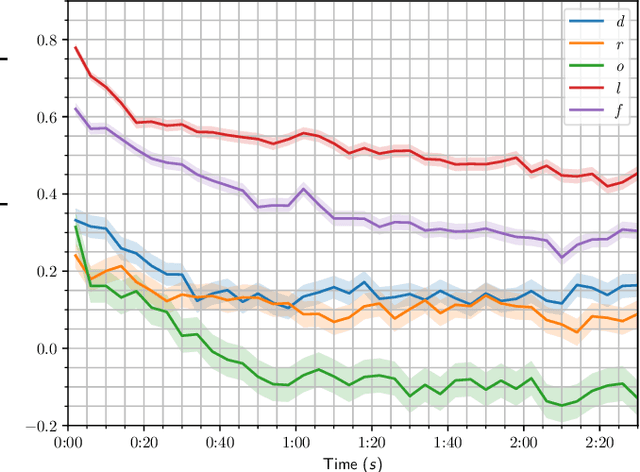
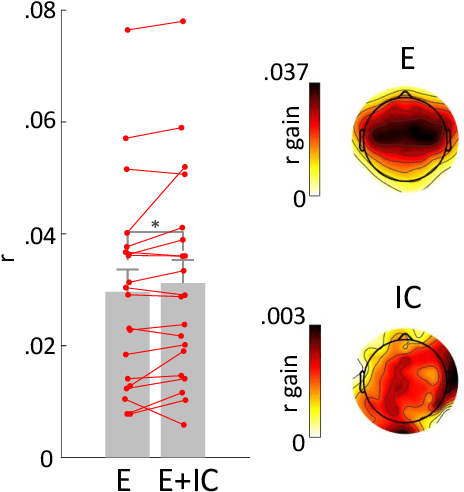
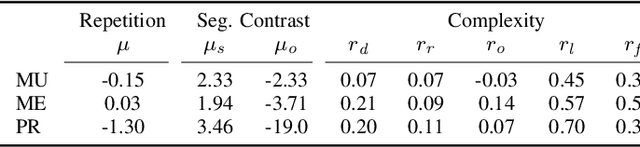
In modeling musical surprisal expectancy with computational methods, it has been proposed to use the information content (IC) of one-step predictions from an autoregressive model as a proxy for surprisal in symbolic music. With an appropriately chosen model, the IC of musical events has been shown to correlate with human perception of surprise and complexity aspects, including tonal and rhythmic complexity. This work investigates whether an analogous methodology can be applied to music audio. We train an autoregressive Transformer model to predict compressed latent audio representations of a pretrained autoencoder network. We verify learning effects by estimating the decrease in IC with repetitions. We investigate the mean IC of musical segment types (e.g., A or B) and find that segment types appearing later in a piece have a higher IC than earlier ones on average. We investigate the IC's relation to audio and musical features and find it correlated with timbral variations and loudness and, to a lesser extent, dissonance, rhythmic complexity, and onset density related to audio and musical features. Finally, we investigate if the IC can predict EEG responses to songs and thus model humans' surprisal in music. We provide code for our method on github.com/sonycslparis/audioic.
Zero-shot Musical Stem Retrieval with Joint-Embedding Predictive Architectures
Nov 29, 2024In this paper, we tackle the task of musical stem retrieval. Given a musical mix, it consists in retrieving a stem that would fit with it, i.e., that would sound pleasant if played together. To do so, we introduce a new method based on Joint-Embedding Predictive Architectures, where an encoder and a predictor are jointly trained to produce latent representations of a context and predict latent representations of a target. In particular, we design our predictor to be conditioned on arbitrary instruments, enabling our model to perform zero-shot stem retrieval. In addition, we discover that pretraining the encoder using contrastive learning drastically improves the model's performance. We validate the retrieval performances of our model using the MUSDB18 and MoisesDB datasets. We show that it significantly outperforms previous baselines on both datasets, showcasing its ability to support more or less precise (and possibly unseen) conditioning. We also evaluate the learned embeddings on a beat tracking task, demonstrating that they retain temporal structure and local information.
Continuous Autoregressive Models with Noise Augmentation Avoid Error Accumulation
Nov 27, 2024Autoregressive models are typically applied to sequences of discrete tokens, but recent research indicates that generating sequences of continuous embeddings in an autoregressive manner is also feasible. However, such Continuous Autoregressive Models (CAMs) can suffer from a decline in generation quality over extended sequences due to error accumulation during inference. We introduce a novel method to address this issue by injecting random noise into the input embeddings during training. This procedure makes the model robust against varying error levels at inference. We further reduce error accumulation through an inference procedure that introduces low-level noise. Experiments on musical audio generation show that CAM substantially outperforms existing autoregressive and non-autoregressive approaches while preserving audio quality over extended sequences. This work paves the way for generating continuous embeddings in a purely autoregressive setting, opening new possibilities for real-time and interactive generative applications.
Improving Musical Accompaniment Co-creation via Diffusion Transformers
Oct 30, 2024Building upon Diff-A-Riff, a latent diffusion model for musical instrument accompaniment generation, we present a series of improvements targeting quality, diversity, inference speed, and text-driven control. First, we upgrade the underlying autoencoder to a stereo-capable model with superior fidelity and replace the latent U-Net with a Diffusion Transformer. Additionally, we refine text prompting by training a cross-modality predictive network to translate text-derived CLAP embeddings to audio-derived CLAP embeddings. Finally, we improve inference speed by training the latent model using a consistency framework, achieving competitive quality with fewer denoising steps. Our model is evaluated against the original Diff-A-Riff variant using objective metrics in ablation experiments, demonstrating promising advancements in all targeted areas. Sound examples are available at: https://sonycslparis.github.io/improved_dar/.
The evolution of inharmonicity and noisiness in contemporary popular music
Aug 15, 2024Much of Western classical music uses instruments based on acoustic resonance. Such instruments produce harmonic or quasi-harmonic sounds. On the other hand, since the early 1970s, popular music has largely been produced in the recording studio. As a result, popular music is not bound to be based on harmonic or quasi-harmonic sounds. In this study, we use modified MPEG-7 features to explore and characterise the way in which the use of noise and inharmonicity has evolved in popular music since 1961. We set this evolution in the context of other broad categories of music, including Western classical piano music, Western classical orchestral music, and musique concr\`ete. We propose new features that allow us to distinguish between inharmonicity resulting from noise and inharmonicity resulting from interactions between relatively discrete partials. When the history of contemporary popular music is viewed through the lens of these new features, we find that the period since 1961 can be divided into three phases. From 1961 to 1972, there was a steady increase in inharmonicity but no significant increase in noise. From 1972 to 1986, both inharmonicity and noise increased. Then, since 1986, there has been a steady decrease in both inharmonicity and noise to today's popular music which is significantly less noisy but more inharmonic than the music of the sixties. We relate these observed trends to the development of music production practice over the period and illustrate them with focused analyses of certain key artists and tracks.