 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-PRESSO: Ultra Low Bitrate Sound Effect Compression With Diffusion Autoencoders And Offline Quantization
Feb 16, 2026Neural audio compression models have recently achieved extreme compression rates, enabling efficient latent generative modeling. Conversely, latent generative models have been applied to compression, pushing the limits of continuous and discrete approaches. However, existing methods remain constrained to low-resolution audio and degrade substantially at very low bitrates, where audible artifacts are prominent. In this paper, we present S-PRESSO, a 48kHz sound effect compression model that produces both continuous and discrete embeddings at ultra-low bitrates, down to 0.096 kbps, via offline quantization. Our model relies on a pretrained latent diffusion model to decode compressed audio embeddings learned by a latent encoder. Leveraging the generative priors of the diffusion decoder, we achieve extremely low frame rates, down to 1Hz (750x compression rate), producing convincing and realistic reconstructions at the cost of exact fidelity. Despite operating at high compression rates, we demonstrate that S-PRESSO outperforms both continuous and discrete baselines in audio quality, acoustic similarity and reconstruction metrics.
Twenty-Five Years of MIR Research: Achievements, Practices, Evaluations, and Future Challenges
Nov 10, 2025In this paper, we trace the evolution of Music Information Retrieval (MIR) over the past 25 years. While MIR gathers all kinds of research related to music informatics, a large part of it focuses on signal processing techniques for music data, fostering a close relationship with the IEEE Audio and Acoustic Signal Processing Technical Commitee. In this paper, we reflect the main research achievements of MIR along the three EDICS related to music analysis, processing and generation. We then review a set of successful practices that fuel the rapid development of MIR research. One practice is the annual research benchmark, the Music Information Retrieval Evaluation eXchange, where participants compete on a set of research tasks. Another practice is the pursuit of reproducible and open research. The active engagement with industry research and products is another key factor for achieving large societal impacts and motivating younger generations of students to join the field. Last but not the least, the commitment to diversity, equity and inclusion ensures MIR to be a vibrant and open community where various ideas, methodologies, and career pathways collide. We finish by providing future challenges MIR will have to face.
The Inverse Drum Machine: Source Separation Through Joint Transcription and Analysis-by-Synthesis
May 06, 2025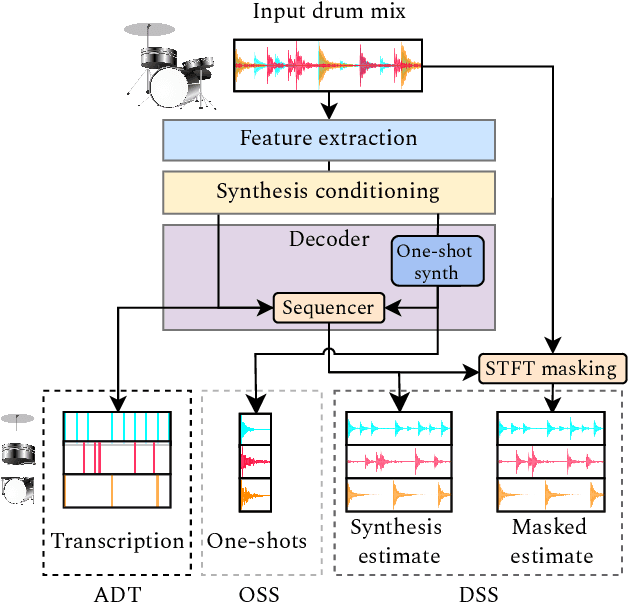



We introduce the Inverse Drum Machine (IDM), a novel approach to drum source separation that combines analysis-by-synthesis with deep learning. Unlike recent supervised methods that rely on isolated stems, IDM requires only transcription annotations. It jointly optimizes automatic drum transcription and one-shot drum sample synthesis in an end-to-end framework. By convolving synthesized one-shot samples with estimated onsets-mimicking a drum machine-IDM reconstructs individual drum stems and trains a neural network to match the original mixture. Evaluations on the StemGMD dataset show that IDM achieves separation performance on par with state-of-the-art supervised methods, while substantially outperforming matrix decomposition baselines.
Masked Latent Prediction and Classification for Self-Supervised Audio Representation Learning
Feb 17, 2025



Recently, self-supervised learning methods based on masked latent prediction have proven to encode input data into powerful representations. However, during training, the learned latent space can be further transformed to extract higher-level information that could be more suited for downstream classification tasks. Therefore, we propose a new method: MAsked latenT Prediction And Classification (MATPAC), which is trained with two pretext tasks solved jointly. As in previous work, the first pretext task is a masked latent prediction task, ensuring a robust input representation in the latent space. The second one is unsupervised classification, which utilises the latent representations of the first pretext task to match probability distributions between a teacher and a student. We validate the MATPAC method by comparing it to other state-of-the-art proposals and conducting ablations studies. MATPAC reaches state-of-the-art self-supervised learning results on reference audio classification datasets such as OpenMIC, GTZAN, ESC-50 and US8K and outperforms comparable supervised methods results for musical auto-tagging on Magna-tag-a-tune.
Zero-shot Musical Stem Retrieval with Joint-Embedding Predictive Architectures
Nov 29, 2024In this paper, we tackle the task of musical stem retrieval. Given a musical mix, it consists in retrieving a stem that would fit with it, i.e., that would sound pleasant if played together. To do so, we introduce a new method based on Joint-Embedding Predictive Architectures, where an encoder and a predictor are jointly trained to produce latent representations of a context and predict latent representations of a target. In particular, we design our predictor to be conditioned on arbitrary instruments, enabling our model to perform zero-shot stem retrieval. In addition, we discover that pretraining the encoder using contrastive learning drastically improves the model's performance. We validate the retrieval performances of our model using the MUSDB18 and MoisesDB datasets. We show that it significantly outperforms previous baselines on both datasets, showcasing its ability to support more or less precise (and possibly unseen) conditioning. We also evaluate the learned embeddings on a beat tracking task, demonstrating that they retain temporal structure and local information.
A Contrastive Self-Supervised Learning scheme for beat tracking amenable to few-shot learning
Nov 06, 2024



In this paper, we propose a novel Self-Supervised-Learning scheme to train rhythm analysis systems and instantiate it for few-shot beat tracking. Taking inspiration from the Contrastive Predictive Coding paradigm, we propose to train a Log-Mel-Spectrogram Transformer encoder to contrast observations at times separated by hypothesized beat intervals from those that are not. We do this without the knowledge of ground-truth tempo or beat positions, as we rely on the local maxima of a Predominant Local Pulse function, considered as a proxy for Tatum positions, to define candidate anchors, candidate positives (located at a distance of a power of two from the anchor) and negatives (remaining time positions). We show that a model pre-trained using this approach on the unlabeled FMA, MTT and MTG-Jamendo datasets can successfully be fine-tuned in the few-shot regime, i.e. with just a few annotated examples to get a competitive beat-tracking performance.
Episodic fine-tuning prototypical networks for optimization-based few-shot learning: Application to audio classification
Oct 04, 2024The Prototypical Network (ProtoNet) has emerged as a popular choice in Few-shot Learning (FSL) scenarios due to its remarkable performance and straightforward implementation. Building upon such success, we first propose a simple (yet novel) method to fine-tune a ProtoNet on the (labeled) support set of the test episode of a C-way-K-shot test episode (without using the query set which is only used for evaluation). We then propose an algorithmic framework that combines ProtoNet with optimization-based FSL algorithms (MAML and Meta-Curvature) to work with such a fine-tuning method. Since optimization-based algorithms endow the target learner model with the ability to fast adaption to only a few samples, we utilize ProtoNet as the target model to enhance its fine-tuning performance with the help of a specifically designed episodic fine-tuning strategy. The experimental results confirm that our proposed models, MAML-Proto and MC-Proto, combined with our unique fine-tuning method, outperform regular ProtoNet by a large margin in few-shot audio classification tasks on the ESC-50 and Speech Commands v2 datasets. We note that although we have only applied our model to the audio domain, it is a general method and can be easily extended to other domains.
* Accepted at MLSP 2024
Stem-JEPA: A Joint-Embedding Predictive Architecture for Musical Stem Compatibility Estimation
Aug 05, 2024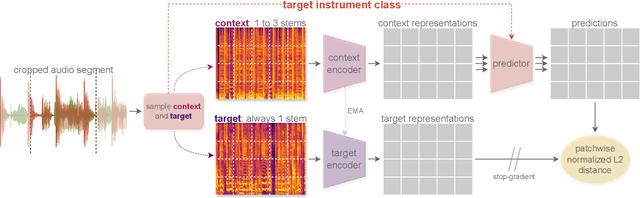
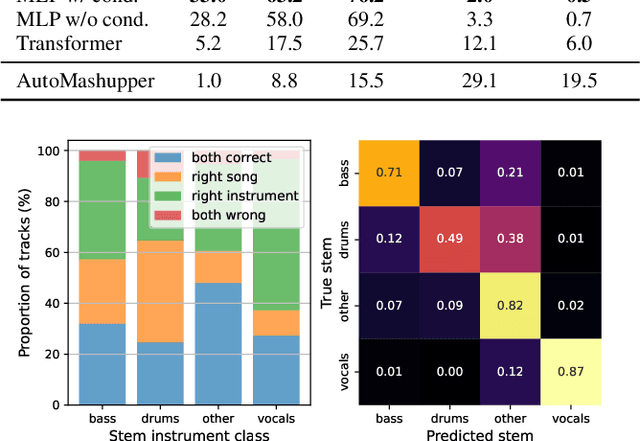
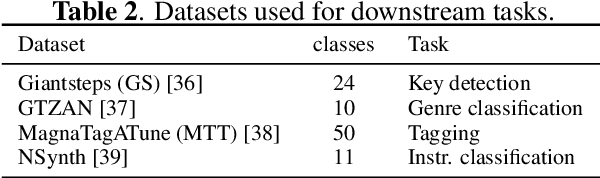
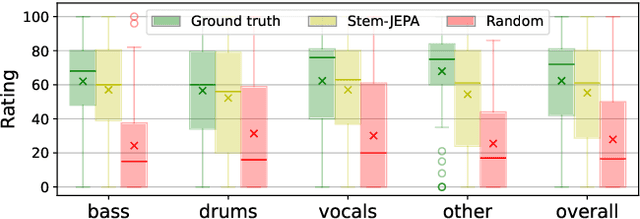
This paper explores the automated process of determining stem compatibility by identifying audio recordings of single instruments that blend well with a given musical context. To tackle this challenge, we present Stem-JEPA, a novel Joint-Embedding Predictive Architecture (JEPA) trained on a multi-track dataset using a self-supervised learning approach. Our model comprises two networks: an encoder and a predictor, which are jointly trained to predict the embeddings of compatible stems from the embeddings of a given context, typically a mix of several instruments. Training a model in this manner allows its use in estimating stem compatibility - retrieving, aligning, or generating a stem to match a given mix - or for downstream tasks such as genre or key estimation, as the training paradigm requires the model to learn information related to timbre, harmony, and rhythm. We evaluate our model's performance on a retrieval task on the MUSDB18 dataset, testing its ability to find the missing stem from a mix and through a subjective user study. We also show that the learned embeddings capture temporal alignment information and, finally, evaluate the representations learned by our model on several downstream tasks, highlighting that they effectively capture meaningful musical features.
Investigating Design Choices in Joint-Embedding Predictive Architectures for General Audio Representation Learning
May 14, 2024


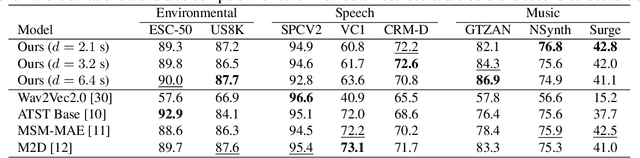
This paper addresses the problem of self-supervised general-purpose audio representation learning. We explore the use of Joint-Embedding Predictive Architectures (JEPA) for this task, which consists of splitting an input mel-spectrogram into two parts (context and target), computing neural representations for each, and training the neural network to predict the target representations from the context representations. We investigate several design choices within this framework and study their influence through extensive experiments by evaluating our models on various audio classification benchmarks, including environmental sounds, speech and music downstream tasks. We focus notably on which part of the input data is used as context or target and show experimentally that it significantly impacts the model's quality. In particular, we notice that some effective design choices in the image domain lead to poor performance on audio, thus highlighting major differences between these two modalities.
Degradation-Invariant Music Indexing
Mar 01, 2024For music indexing robust to sound degradations and scalable for big music catalogs, this scientific report presents an approach based on audio descriptors relevant to the music content and invariant to sound transformations (noise addition, distortion, lossy coding, pitch/time transformations, or filtering e.g.). To achieve this task, one of the key point of the proposed method is the definition of high-dimensional audio prints, which are intrinsically (by design) robust to some sound degradations. The high dimensionality of this first representation is then used to learn a linear projection to a sub-space significantly smaller, which reduces again the sensibility to sound degradations using a series of discriminant analyses. Finally, anchoring the analysis times on local maxima of a selected onset function, an approximative hashing is done to provide a better tolerance to bit corruptions, and in the same time to make easier the scaling of the method.