 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelody-Lyrics Matching with Contrastive Alignment Loss
Jul 31, 2025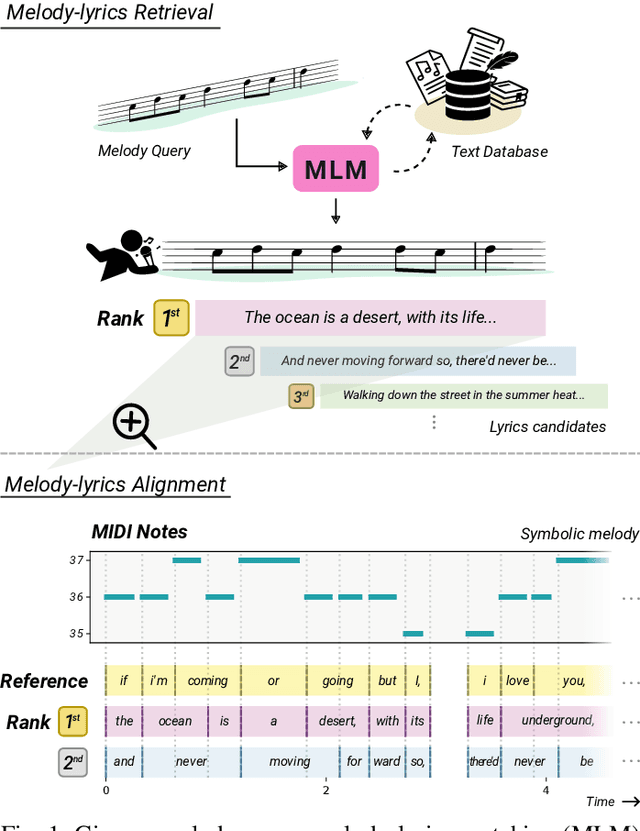
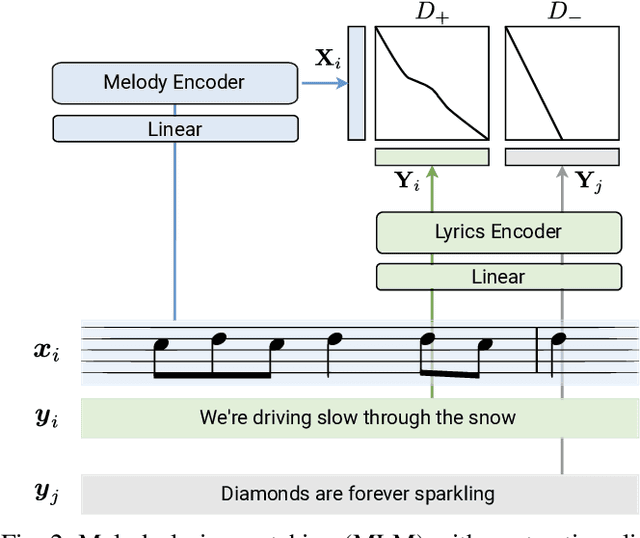
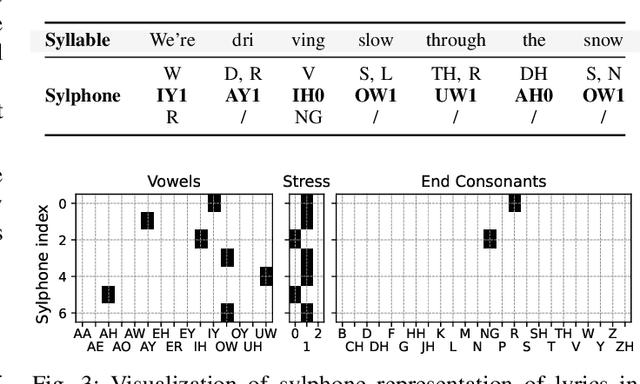
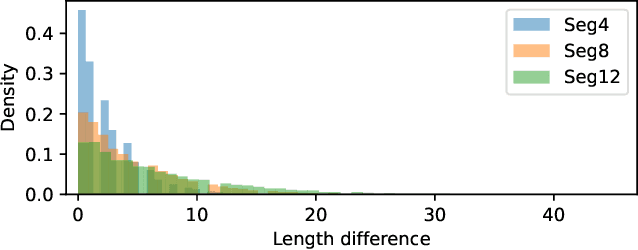
The connection between music and lyrics is far beyond semantic bonds. Conceptual pairs in the two modalities such as rhythm and rhyme, note duration and syllabic stress, and structure correspondence, raise a compelling yet seldom-explored direction in the field of music information retrieval. In this paper, we present melody-lyrics matching (MLM), a new task which retrieves potential lyrics for a given symbolic melody from text sources. Rather than generating lyrics from scratch, MLM essentially exploits the relationships between melody and lyrics. We propose a self-supervised representation learning framework with contrastive alignment loss for melody and lyrics. This has the potential to leverage the abundance of existing songs with paired melody and lyrics. No alignment annotations are required. Additionally, we introduce sylphone, a novel representation for lyrics at syllable-level activated by phoneme identity and vowel stress. We demonstrate that our method can match melody with coherent and singable lyrics with empirical results and intuitive examples. We open source code and provide matching examples on the companion webpage: https://github.com/changhongw/mlm.
TACO: Training-free Sound Prompted Segmentation via Deep Audio-visual CO-factorization
Dec 02, 2024



Large-scale pre-trained audio and image models demonstrate an unprecedented degree of generalization, making them suitable for a wide range of applications. Here, we tackle the specific task of sound-prompted segmentation, aiming to segment image regions corresponding to objects heard in an audio signal. Most existing approaches tackle this problem by fine-tuning pre-trained models or by training additional modules specifically for the task. We adopt a different strategy: we introduce a training-free approach that leverages Non-negative Matrix Factorization (NMF) to co-factorize audio and visual features from pre-trained models to reveal shared interpretable concepts. These concepts are passed to an open-vocabulary segmentation model for precise segmentation maps. By using frozen pre-trained models, our method achieves high generalization and establishes state-of-the-art performance in unsupervised sound-prompted segmentation, significantly surpassing previous unsupervised methods.
An Eye for an Ear: Zero-shot Audio Description Leveraging an Image Captioner using Audiovisual Distribution Alignment
Oct 08, 2024



Multimodal large language models have fueled progress in image captioning. These models, fine-tuned on vast image datasets, exhibit a deep understanding of semantic concepts. In this work, we show that this ability can be re-purposed for audio captioning, where the joint image-language decoder can be leveraged to describe auditory content associated with image sequences within videos featuring audiovisual content. This can be achieved via multimodal alignment. Yet, this multimodal alignment task is non-trivial due to the inherent disparity between audible and visible elements in real-world videos. Moreover, multimodal representation learning often relies on contrastive learning, facing the challenge of the so-called modality gap which hinders smooth integration between modalities. In this work, we introduce a novel methodology for bridging the audiovisual modality gap by matching the distributions of tokens produced by an audio backbone and those of an image captioner. Our approach aligns the audio token distribution with that of the image tokens, enabling the model to perform zero-shot audio captioning in an unsupervised fashion while keeping the initial image captioning component unaltered. This alignment allows for the use of either audio or audiovisual input by combining or substituting the image encoder with the aligned audio encoder. Our method achieves significantly improved performances in zero-shot audio captioning, compared to existing approaches.
SALT: Standardized Audio event Label Taxonomy
Sep 18, 2024



Machine listening systems often rely on fixed taxonomies to organize and label audio data, key for training and evaluating deep neural networks (DNNs) and other supervised algorithms. However, such taxonomies face significant constraints: they are composed of application-dependent predefined categories, which hinders the integration of new or varied sounds, and exhibits limited cross-dataset compatibility due to inconsistent labeling standards. To overcome these limitations, we introduce SALT: Standardized Audio event Label Taxonomy. Building upon the hierarchical structure of AudioSet's ontology, our taxonomy extends and standardizes labels across 24 publicly available environmental sound datasets, allowing the mapping of class labels from diverse datasets to a unified system. Our proposal comes with a new Python package designed for navigating and utilizing this taxonomy, easing cross-dataset label searching and hierarchical exploration. Notably, our package allows effortless data aggregation from diverse sources, hence easy experimentation with combined datasets.
On the choice of the optimal temporal support for audio classification with Pre-trained embeddings
Dec 21, 2023Current state-of-the-art audio analysis systems rely on pre-trained embedding models, often used off-the-shelf as (frozen) feature extractors. Choosing the best one for a set of tasks is the subject of many recent publications. However, one aspect often overlooked in these works is the influence of the duration of audio input considered to extract an embedding, which we refer to as Temporal Support (TS). In this work, we study the influence of the TS for well-established or emerging pre-trained embeddings, chosen to represent different types of architectures and learning paradigms. We conduct this evaluation using both musical instrument and environmental sound datasets, namely OpenMIC, TAU Urban Acoustic Scenes 2020 Mobile, and ESC-50. We especially highlight that Audio Spectrogram Transformer-based systems (PaSST and BEATs) remain effective with smaller TS, which therefore allows for a drastic reduction in memory and computational cost. Moreover, we show that by choosing the optimal TS we reach competitive results across all tasks. In particular, we improve the state-of-the-art results on OpenMIC, using BEATs and PaSST without any fine-tuning.
Foreground-Background Ambient Sound Scene Separation
May 11, 2020


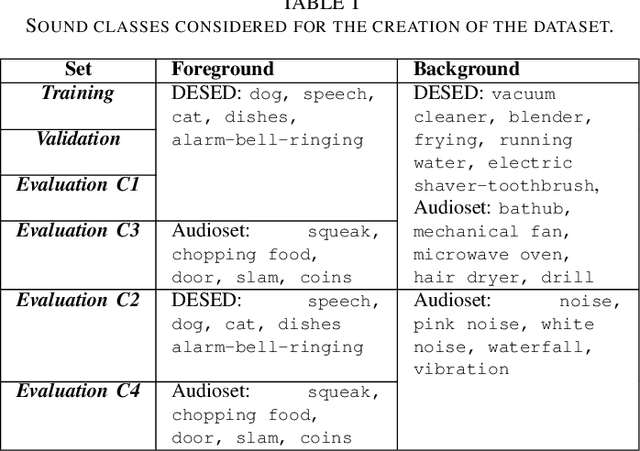
Ambient sound scenes typically comprise multiple short events occurring on top of a somewhat stationary background. We consider the task of separating these events from the background, which we call foreground-background ambient sound scene separation. We propose a deep learning-based separation framework with a suitable feature normaliza-tion scheme and an optional auxiliary network capturing the background statistics, and we investigate its ability to handle the great variety of sound classes encountered in ambient sound scenes, which have often not been seen in training. To do so, we create single-channel foreground-background mixtures using isolated sounds from the DESED and Audioset datasets, and we conduct extensive experiments with mixtures of seen or unseen sound classes at various signal-to-noise ratios. Our experimental findings demonstrate the generalization ability of the proposed approach.