 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Knowledge Distillation for Embedding Refinement in Personalized Speech Enhancement
Jan 21, 2026Personalized speech enhancement (PSE) has shown convincing results when it comes to extracting a known target voice among interfering ones. The corresponding systems usually incorporate a representation of the target voice within the enhancement system, which is extracted from an enrollment clip of the target voice with upstream models. Those models are generally heavy as the speaker embedding's quality directly affects PSE performances. Yet, embeddings generated beforehand cannot account for the variations of the target voice during inference time. In this paper, we propose to perform on-thefly refinement of the speaker embedding using a tiny speaker encoder. We first introduce a novel contrastive knowledge distillation methodology in order to train a 150k-parameter encoder from complex embeddings. We then use this encoder within the enhancement system during inference and show that the proposed method greatly improves PSE performances while maintaining a low computational load.
O-EENC-SD: Efficient Online End-to-End Neural Clustering for Speaker Diarization
Dec 17, 2025We introduce O-EENC-SD: an end-to-end online speaker diarization system based on EEND-EDA, featuring a novel RNN-based stitching mechanism for online prediction. In particular, we develop a novel centroid refinement decoder whose usefulness is assessed through a rigorous ablation study. Our system provides key advantages over existing methods: a hyperparameter-free solution compared to unsupervised clustering approaches, and a more efficient alternative to current online end-to-end methods, which are computationally costly. We demonstrate that O-EENC-SD is competitive with the state of the art in the two-speaker conversational telephone speech domain, as tested on the CallHome dataset. Our results show that O-EENC-SD provides a great trade-off between DER and complexity, even when working on independent chunks with no overlap, making the system extremely efficient.
Perceptual Noise-Masking with Music through Deep Spectral Envelope Shaping
Feb 24, 2025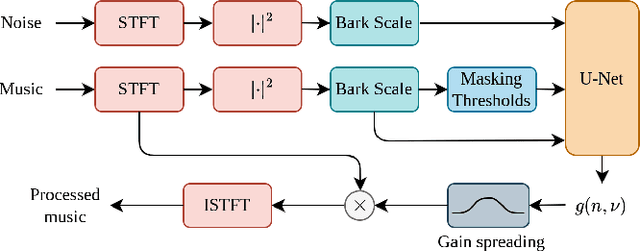
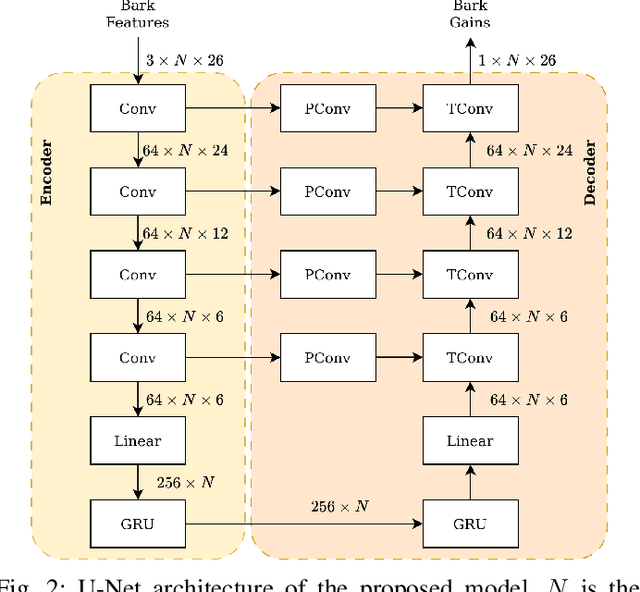
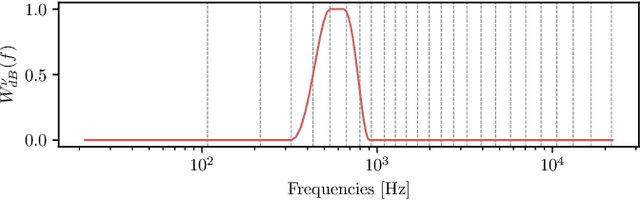
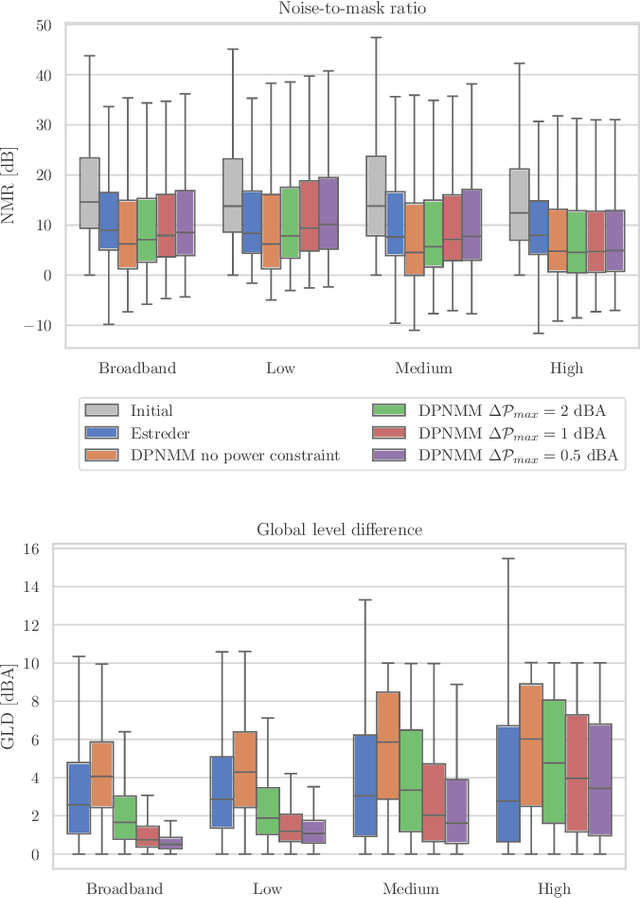
People often listen to music in noisy environments, seeking to isolate themselves from ambient sounds. Indeed, a music signal can mask some of the noise's frequency components due to the effect of simultaneous masking. In this article, we propose a neural network based on a psychoacoustic masking model, designed to enhance the music's ability to mask ambient noise by reshaping its spectral envelope with predicted filter frequency responses. The model is trained with a perceptual loss function that balances two constraints: effectively masking the noise while preserving the original music mix and the user's chosen listening level. We evaluate our approach on simulated data replicating a user's experience of listening to music with headphones in a noisy environment. The results, based on defined objective metrics, demonstrate that our system improves the state of the art.
Masked Latent Prediction and Classification for Self-Supervised Audio Representation Learning
Feb 17, 2025



Recently, self-supervised learning methods based on masked latent prediction have proven to encode input data into powerful representations. However, during training, the learned latent space can be further transformed to extract higher-level information that could be more suited for downstream classification tasks. Therefore, we propose a new method: MAsked latenT Prediction And Classification (MATPAC), which is trained with two pretext tasks solved jointly. As in previous work, the first pretext task is a masked latent prediction task, ensuring a robust input representation in the latent space. The second one is unsupervised classification, which utilises the latent representations of the first pretext task to match probability distributions between a teacher and a student. We validate the MATPAC method by comparing it to other state-of-the-art proposals and conducting ablations studies. MATPAC reaches state-of-the-art self-supervised learning results on reference audio classification datasets such as OpenMIC, GTZAN, ESC-50 and US8K and outperforms comparable supervised methods results for musical auto-tagging on Magna-tag-a-tune.
TACO: Training-free Sound Prompted Segmentation via Deep Audio-visual CO-factorization
Dec 02, 2024



Large-scale pre-trained audio and image models demonstrate an unprecedented degree of generalization, making them suitable for a wide range of applications. Here, we tackle the specific task of sound-prompted segmentation, aiming to segment image regions corresponding to objects heard in an audio signal. Most existing approaches tackle this problem by fine-tuning pre-trained models or by training additional modules specifically for the task. We adopt a different strategy: we introduce a training-free approach that leverages Non-negative Matrix Factorization (NMF) to co-factorize audio and visual features from pre-trained models to reveal shared interpretable concepts. These concepts are passed to an open-vocabulary segmentation model for precise segmentation maps. By using frozen pre-trained models, our method achieves high generalization and establishes state-of-the-art performance in unsupervised sound-prompted segmentation, significantly surpassing previous unsupervised methods.
Multiple Choice Learning for Efficient Speech Separation with Many Speakers
Nov 27, 2024Training speech separation models in the supervised setting raises a permutation problem: finding the best assignation between the model predictions and the ground truth separated signals. This inherently ambiguous task is customarily solved using Permutation Invariant Training (PIT). In this article, we instead consider using the Multiple Choice Learning (MCL) framework, which was originally introduced to tackle ambiguous tasks. We demonstrate experimentally on the popular WSJ0-mix and LibriMix benchmarks that MCL matches the performances of PIT, while being computationally advantageous. This opens the door to a promising research direction, as MCL can be naturally extended to handle a variable number of speakers, or to tackle speech separation in the unsupervised setting.
A Contrastive Self-Supervised Learning scheme for beat tracking amenable to few-shot learning
Nov 06, 2024



In this paper, we propose a novel Self-Supervised-Learning scheme to train rhythm analysis systems and instantiate it for few-shot beat tracking. Taking inspiration from the Contrastive Predictive Coding paradigm, we propose to train a Log-Mel-Spectrogram Transformer encoder to contrast observations at times separated by hypothesized beat intervals from those that are not. We do this without the knowledge of ground-truth tempo or beat positions, as we rely on the local maxima of a Predominant Local Pulse function, considered as a proxy for Tatum positions, to define candidate anchors, candidate positives (located at a distance of a power of two from the anchor) and negatives (remaining time positions). We show that a model pre-trained using this approach on the unlabeled FMA, MTT and MTG-Jamendo datasets can successfully be fine-tuned in the few-shot regime, i.e. with just a few annotated examples to get a competitive beat-tracking performance.
An Eye for an Ear: Zero-shot Audio Description Leveraging an Image Captioner using Audiovisual Distribution Alignment
Oct 08, 2024



Multimodal large language models have fueled progress in image captioning. These models, fine-tuned on vast image datasets, exhibit a deep understanding of semantic concepts. In this work, we show that this ability can be re-purposed for audio captioning, where the joint image-language decoder can be leveraged to describe auditory content associated with image sequences within videos featuring audiovisual content. This can be achieved via multimodal alignment. Yet, this multimodal alignment task is non-trivial due to the inherent disparity between audible and visible elements in real-world videos. Moreover, multimodal representation learning often relies on contrastive learning, facing the challenge of the so-called modality gap which hinders smooth integration between modalities. In this work, we introduce a novel methodology for bridging the audiovisual modality gap by matching the distributions of tokens produced by an audio backbone and those of an image captioner. Our approach aligns the audio token distribution with that of the image tokens, enabling the model to perform zero-shot audio captioning in an unsupervised fashion while keeping the initial image captioning component unaltered. This alignment allows for the use of either audio or audiovisual input by combining or substituting the image encoder with the aligned audio encoder. Our method achieves significantly improved performances in zero-shot audio captioning, compared to existing approaches.
SALT: Standardized Audio event Label Taxonomy
Sep 18, 2024



Machine listening systems often rely on fixed taxonomies to organize and label audio data, key for training and evaluating deep neural networks (DNNs) and other supervised algorithms. However, such taxonomies face significant constraints: they are composed of application-dependent predefined categories, which hinders the integration of new or varied sounds, and exhibits limited cross-dataset compatibility due to inconsistent labeling standards. To overcome these limitations, we introduce SALT: Standardized Audio event Label Taxonomy. Building upon the hierarchical structure of AudioSet's ontology, our taxonomy extends and standardizes labels across 24 publicly available environmental sound datasets, allowing the mapping of class labels from diverse datasets to a unified system. Our proposal comes with a new Python package designed for navigating and utilizing this taxonomy, easing cross-dataset label searching and hierarchical exploration. Notably, our package allows effortless data aggregation from diverse sources, hence easy experimentation with combined datasets.
Annealed Multiple Choice Learning: Overcoming limitations of Winner-takes-all with annealing
Jul 22, 2024



We introduce Annealed Multiple Choice Learning (aMCL) which combines simulated annealing with MCL. MCL is a learning framework handling ambiguous tasks by predicting a small set of plausible hypotheses. These hypotheses are trained using the Winner-takes-all (WTA) scheme, which promotes the diversity of the predictions. However, this scheme may converge toward an arbitrarily suboptimal local minimum, due to the greedy nature of WTA. We overcome this limitation using annealing, which enhances the exploration of the hypothesis space during training. We leverage insights from statistical physics and information theory to provide a detailed description of the model training trajectory. Additionally, we validate our algorithm by extensive experiments on synthetic datasets, on the standard UCI benchmark, and on speech separation.