 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Inverse Drum Machine: Source Separation Through Joint Transcription and Analysis-by-Synthesis
May 06, 2025We introduce the Inverse Drum Machine (IDM), a novel approach to drum source separation that combines analysis-by-synthesis with deep learning. Unlike recent supervised methods that rely on isolated stems, IDM requires only transcription annotations. It jointly optimizes automatic drum transcription and one-shot drum sample synthesis in an end-to-end framework. By convolving synthesized one-shot samples with estimated onsets-mimicking a drum machine-IDM reconstructs individual drum stems and trains a neural network to match the original mixture. Evaluations on the StemGMD dataset show that IDM achieves separation performance on par with state-of-the-art supervised methods, while substantially outperforming matrix decomposition baselines.
Of All StrIPEs: Investigating Structure-informed Positional Encoding for Efficient Music Generation
Apr 07, 2025While music remains a challenging domain for generative models like Transformers, a two-pronged approach has recently proved successful: inserting musically-relevant structural information into the positional encoding (PE) module and using kernel approximation techniques based on Random Fourier Features (RFF) to lower the computational cost from quadratic to linear. Yet, it is not clear how such RFF-based efficient PEs compare with those based on rotation matrices, such as Rotary Positional Encoding (RoPE). In this paper, we present a unified framework based on kernel methods to analyze both families of efficient PEs. We use this framework to develop a novel PE method called RoPEPool, capable of extracting causal relationships from temporal sequences. Using RFF-based PEs and rotation-based PEs, we demonstrate how seemingly disparate PEs can be jointly studied by considering the content-context interactions they induce. For empirical validation, we use a symbolic music generation task, namely, melody harmonization. We show that RoPEPool, combined with highly-informative structural priors, outperforms all methods.
Investigating the Sensitivity of Pre-trained Audio Embeddings to Common Effects
Jan 27, 2025



In recent years, foundation models have significantly advanced data-driven systems across various domains. Yet, their underlying properties, especially when functioning as feature extractors, remain under-explored. In this paper, we investigate the sensitivity to audio effects of audio embeddings extracted from widely-used foundation models, including OpenL3, PANNs, and CLAP. We focus on audio effects as the source of sensitivity due to their prevalent presence in large audio datasets. By applying parameterized audio effects (gain, low-pass filtering, reverberation, and bitcrushing), we analyze the correlation between the deformation trajectories and the effect strength in the embedding space. We propose to quantify the dimensionality and linearizability of the deformation trajectories induced by audio effects using canonical correlation analysis. We find that there exists a direction along which the embeddings move monotonically as the audio effect strength increases, but that the subspace containing the displacements is generally high-dimensional. This shows that pre-trained audio embeddings do not globally linearize the effects. Our empirical results on instrument classification downstream tasks confirm that projecting out the estimated deformation directions cannot generally improve the robustness of pre-trained embeddings to audio effects.
Model-Based Deep Learning for Music Information Research
Jun 17, 2024In this article, we investigate the notion of model-based deep learning in the realm of music information research (MIR). Loosely speaking, we refer to the term model-based deep learning for approaches that combine traditional knowledge-based methods with data-driven techniques, especially those based on deep learning, within a diff erentiable computing framework. In music, prior knowledge for instance related to sound production, music perception or music composition theory can be incorporated into the design of neural networks and associated loss functions. We outline three specifi c scenarios to illustrate the application of model-based deep learning in MIR, demonstrating the implementation of such concepts and their potential.
Winner-takes-all learners are geometry-aware conditional density estimators
Jun 07, 2024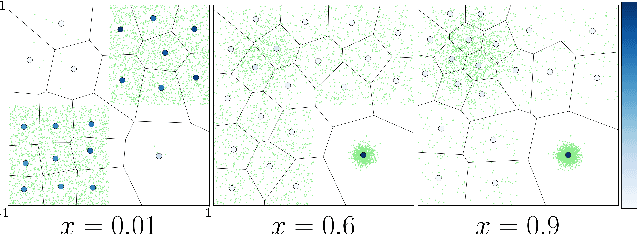
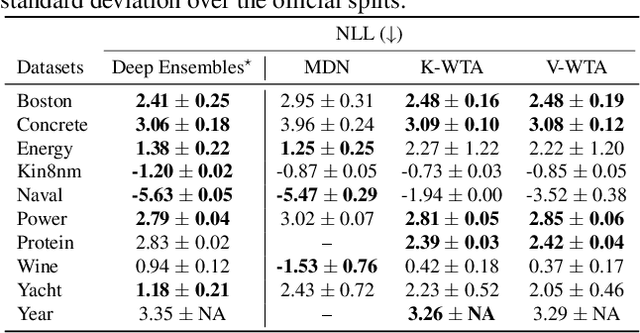
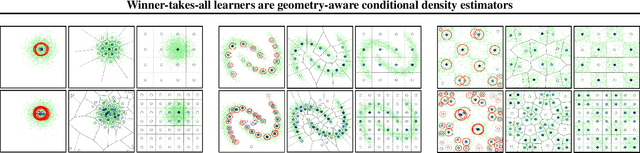
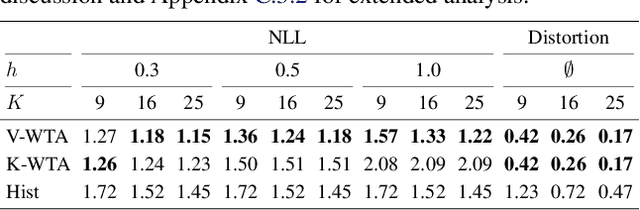
Winner-takes-all training is a simple learning paradigm, which handles ambiguous tasks by predicting a set of plausible hypotheses. Recently, a connection was established between Winner-takes-all training and centroidal Voronoi tessellations, showing that, once trained, hypotheses should quantize optimally the shape of the conditional distribution to predict. However, the best use of these hypotheses for uncertainty quantification is still an open question.In this work, we show how to leverage the appealing geometric properties of the Winner-takes-all learners for conditional density estimation, without modifying its original training scheme. We theoretically establish the advantages of our novel estimator both in terms of quantization and density estimation, and we demonstrate its competitiveness on synthetic and real-world datasets, including audio data.
GLA-Grad: A Griffin-Lim Extended Waveform Generation Diffusion Model
Feb 09, 2024Diffusion models are receiving a growing interest for a variety of signal generation tasks such as speech or music synthesis. WaveGrad, for example, is a successful diffusion model that conditionally uses the mel spectrogram to guide a diffusion process for the generation of high-fidelity audio. However, such models face important challenges concerning the noise diffusion process for training and inference, and they have difficulty generating high-quality speech for speakers that were not seen during training. With the aim of minimizing the conditioning error and increasing the efficiency of the noise diffusion process, we propose in this paper a new scheme called GLA-Grad, which consists in introducing a phase recovery algorithm such as the Griffin-Lim algorithm (GLA) at each step of the regular diffusion process. Furthermore, it can be directly applied to an already-trained waveform generation model, without additional training or fine-tuning. We show that our algorithm outperforms state-of-the-art diffusion models for speech generation, especially when generating speech for a previously unseen target speaker.
* Accepted at ICASSP 2024
SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis
Jan 30, 2024Generative adversarial network (GAN) models can synthesize highquality audio signals while ensuring fast sample generation. However, they are difficult to train and are prone to several issues including mode collapse and divergence. In this paper, we introduce SpecDiff-GAN, a neural vocoder based on HiFi-GAN, which was initially devised for speech synthesis from mel spectrogram. In our model, the training stability is enhanced by means of a forward diffusion process which consists in injecting noise from a Gaussian distribution to both real and fake samples before inputting them to the discriminator. We further improve the model by exploiting a spectrally-shaped noise distribution with the aim to make the discriminator's task more challenging. We then show the merits of our proposed model for speech and music synthesis on several datasets. Our experiments confirm that our model compares favorably in audio quality and efficiency compared to several baselines.
* Accepted at ICASSP 2024
A fully differentiable model for unsupervised singing voice separation
Jan 30, 2024A novel model was recently proposed by Schulze-Forster et al. in [1] for unsupervised music source separation. This model allows to tackle some of the major shortcomings of existing source separation frameworks. Specifically, it eliminates the need for isolated sources during training, performs efficiently with limited data, and can handle homogeneous sources (such as singing voice). But, this model relies on an external multipitch estimator and incorporates an Ad hoc voice assignment procedure. In this paper, we propose to extend this framework and to build a fully differentiable model by integrating a multipitch estimator and a novel differentiable assignment module within the core model. We show the merits of our approach through a set of experiments, and we highlight in particular its potential for processing diverse and unseen data.