 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorSteer: Self-Discovered Concept Injection for Structure-Preserving Music Editing
May 29, 2026Controllable music editing is to modify high-level attributes while strictly preserving rhythmic and melodic structures. However, this task is challenged by a semantic-structural entanglement: steering methods often degrade structure to achieve editing performance, while structural adaptors suppress semantic responsiveness. We propose AnchorSteer, a framework that disentangles this tension by coupling structural anchoring with self-discovered semantic steering. The proposed approach probes internal representations to extract interpretable, label-free concept vectors via a self-supervised reconstruction objective, isolating attributes without curated data. During editing, these portable, plug-and-play concept vectors are injected into diffusion hidden manifolds while a structural adaptor enforces consistency. Variants for unconditioned and conditioned injections are provided to balance robustness and semantic strength. Experiments on ZoME-Bench and subjective tests show that the proposed framework outperforms both steering-only and anchoring-only baselines, enabling significant semantic transformations with high-fidelity structural preservation.
MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline
Feb 24, 2026Song generation aims to produce full songs with vocals and accompaniment from lyrics and text descriptions, yet end-to-end models remain data- and compute-intensive and provide limited editability. We advocate a compositional alternative that decomposes the task into melody composition, singing voice synthesis, and singing accompaniment generation. Central to our approach is MIDI-informed singing accompaniment generation (MIDI-SAG), which conditions accompaniment on the symbolic vocal-melody MIDI to improve rhythmic and harmonic alignment between singing and instrumentation. Moreover, beyond conventional SAG settings that assume continuously sung vocals, compositional song generation features intermittent vocals; we address this by combining explicit rhythmic/harmonic controls with audio continuation to keep the backing track consistent across vocal and non-vocal regions. With lightweight newly trained components requiring only 2.5k hours of audio on a single RTX 3090, our pipeline approaches the perceptual quality of recent open-source end-to-end baselines in several metrics. We provide audio demos and will open-source our model at https://composerflow.github.io/web/.
Training-Efficient Text-to-Music Generation with State-Space Modeling
Jan 21, 2026Recent advances in text-to-music generation (TTM) have yielded high-quality results, but often at the cost of extensive compute and the use of large proprietary internal data. To improve the affordability and openness of TTM training, an open-source generative model backbone that is more training- and data-efficient is needed. In this paper, we constrain the number of trainable parameters in the generative model to match that of the MusicGen-small benchmark (with about 300M parameters), and replace its Transformer backbone with the emerging class of state-space models (SSMs). Specifically, we explore different SSM variants for sequence modeling, and compare a single-stage SSM-based design with a decomposable two-stage SSM/diffusion hybrid design. All proposed models are trained from scratch on a purely public dataset comprising 457 hours of CC-licensed music, ensuring full openness. Our experimental findings are three-fold. First, we show that SSMs exhibit superior training efficiency compared to the Transformer counterpart. Second, despite using only 9% of the FLOPs and 2% of the training data size compared to the MusicGen-small benchmark, our model achieves competitive performance in both objective metrics and subjective listening tests based on MusicCaps captions. Finally, our scaling-down experiment demonstrates that SSMs can maintain competitive performance relative to the Transformer baseline even at the same training budget (measured in iterations), when the model size is reduced to four times smaller. To facilitate the democratization of TTM research, the processed captions, model checkpoints, and source code are available on GitHub via the project page: https://lonian6.github.io/ssmttm/.
How Does Instrumental Music Help SingFake Detection?
Sep 18, 2025Although many models exist to detect singing voice deepfakes (SingFake), how these models operate, particularly with instrumental accompaniment, is unclear. We investigate how instrumental music affects SingFake detection from two perspectives. To investigate the behavioral effect, we test different backbones, unpaired instrumental tracks, and frequency subbands. To analyze the representational effect, we probe how fine-tuning alters encoders' speech and music capabilities. Our results show that instrumental accompaniment acts mainly as data augmentation rather than providing intrinsic cues (e.g., rhythm or harmony). Furthermore, fine-tuning increases reliance on shallow speaker features while reducing sensitivity to content, paralinguistic, and semantic information. These insights clarify how models exploit vocal versus instrumental cues and can inform the design of more interpretable and robust SingFake detection systems.
Exploring State-Space-Model based Language Model in Music Generation
Jul 09, 2025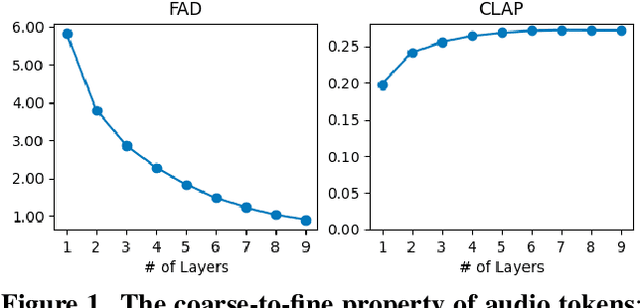
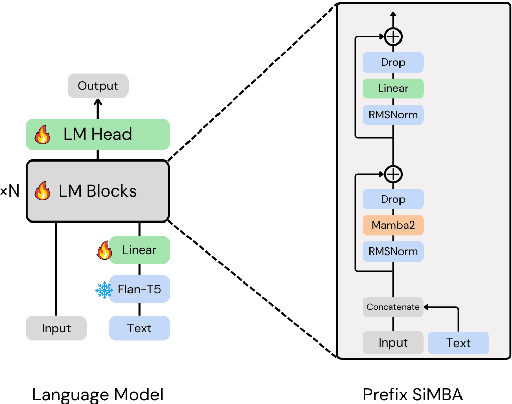
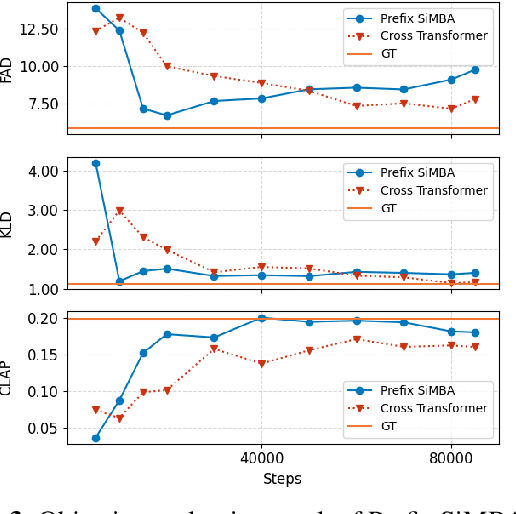
The recent surge in State Space Models (SSMs), particularly the emergence of Mamba, has established them as strong alternatives or complementary modules to Transformers across diverse domains. In this work, we aim to explore the potential of Mamba-based architectures for text-to-music generation. We adopt discrete tokens of Residual Vector Quantization (RVQ) as the modeling representation and empirically find that a single-layer codebook can capture semantic information in music. Motivated by this observation, we focus on modeling a single-codebook representation and adapt SiMBA, originally designed as a Mamba-based encoder, to function as a decoder for sequence modeling. We compare its performance against a standard Transformer-based decoder. Our results suggest that, under limited-resource settings, SiMBA achieves much faster convergence and generates outputs closer to the ground truth. This demonstrates the promise of SSMs for efficient and expressive text-to-music generation. We put audio examples on Github.
Fx-Encoder++: Extracting Instrument-Wise Audio Effects Representations from Mixtures
Jul 03, 2025General-purpose audio representations have proven effective across diverse music information retrieval applications, yet their utility in intelligent music production remains limited by insufficient understanding of audio effects (Fx). Although previous approaches have emphasized audio effects analysis at the mixture level, this focus falls short for tasks demanding instrument-wise audio effects understanding, such as automatic mixing. In this work, we present Fx-Encoder++, a novel model designed to extract instrument-wise audio effects representations from music mixtures. Our approach leverages a contrastive learning framework and introduces an "extractor" mechanism that, when provided with instrument queries (audio or text), transforms mixture-level audio effects embeddings into instrument-wise audio effects embeddings. We evaluated our model across retrieval and audio effects parameter matching tasks, testing its performance across a diverse range of instruments. The results demonstrate that Fx-Encoder++ outperforms previous approaches at mixture level and show a novel ability to extract effects representation instrument-wise, addressing a critical capability gap in intelligent music production systems.
Towards Generalizability to Tone and Content Variations in the Transcription of Amplifier Rendered Electric Guitar Audio
Apr 10, 2025Transcribing electric guitar recordings is challenging due to the scarcity of diverse datasets and the complex tone-related variations introduced by amplifiers, cabinets, and effect pedals. To address these issues, we introduce EGDB-PG, a novel dataset designed to capture a wide range of tone-related characteristics across various amplifier-cabinet configurations. In addition, we propose the Tone-informed Transformer (TIT), a Transformer-based transcription model enhanced with a tone embedding mechanism that leverages learned representations to improve the model's adaptability to tone-related nuances. Experiments demonstrate that TIT, trained on EGDB-PG, outperforms existing baselines across diverse amplifier types, with transcription accuracy improvements driven by the dataset's diversity and the tone embedding technique. Through detailed benchmarking and ablation studies, we evaluate the impact of tone augmentation, content augmentation, audio normalization, and tone embedding on transcription performance. This work advances electric guitar transcription by overcoming limitations in dataset diversity and tone modeling, providing a robust foundation for future research.
Music2Fail: Transfer Music to Failed Recorder Style
Nov 27, 2024



The goal of music style transfer is to convert a music performance by one instrument into another while keeping the musical contents unchanged. In this paper, we investigate another style transfer scenario called ``failed-music style transfer''. Unlike the usual music style transfer where the content remains the same and only the instrumental characteristics are changed, this scenario seeks to transfer the music from the source instrument to the target instrument which is deliberately performed off-pitch. Our work attempts to transfer normally played music into off-pitch recorder music, which we call ``failed-style recorder'', and study the results of the conversion. To carry out this work, we have also proposed a dataset of failed-style recorders for this task, called ``FR109 Dataset''. Such an experiment explores the music style transfer task in a more expressive setting, as the generated audio should sound like an ``off-pitch recorder'' while maintaining a certain degree of naturalness.
Demo of Zero-Shot Guitar Amplifier Modelling: Enhancing Modeling with Hyper Neural Networks
Oct 07, 2024
Electric guitar tone modeling typically focuses on the non-linear transformation from clean to amplifier-rendered audio. Traditional methods rely on one-to-one mappings, incorporating device parameters into neural models to replicate specific amplifiers. However, these methods are limited by the need for specific training data. In this paper, we adapt a model based on the previous work, which leverages a tone embedding encoder and a feature wise linear modulation (FiLM) condition method. In this work, we altered conditioning method using a hypernetwork-based gated convolutional network (GCN) to generate audio that blends clean input with the tone characteristics of reference audio. By extending the training data to cover a wider variety of amplifier tones, our model is able to capture a broader range of tones. Additionally, we developed a real-time plugin to demonstrate the system's practical application, allowing users to experience its performance interactively. Our results indicate that the proposed system achieves superior tone modeling versatility compared to traditional methods.
METEOR: Melody-aware Texture-controllable Symbolic Orchestral Music Generation
Sep 18, 2024



Western music is often characterized by a homophonic texture, in which the musical content can be organized into a melody and an accompaniment. In orchestral music, in particular, the composer can select specific characteristics for each instrument's part within the accompaniment, while also needing to adapt the melody to suit the capabilities of the instruments performing it. In this work, we propose METEOR, a model for Melody-aware Texture-controllable Orchestral music generation. This model performs symbolic multi-track music style transfer with a focus on melodic fidelity. We allow bar- and track-level controllability of the accompaniment with various textural attributes while keeping a homophonic texture. We show that the model can achieve controllability performances similar to strong baselines while greatly improve melodic fidelity.