 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFx-Encoder++: Extracting Instrument-Wise Audio Effects Representations from Mixtures
Jul 03, 2025General-purpose audio representations have proven effective across diverse music information retrieval applications, yet their utility in intelligent music production remains limited by insufficient understanding of audio effects (Fx). Although previous approaches have emphasized audio effects analysis at the mixture level, this focus falls short for tasks demanding instrument-wise audio effects understanding, such as automatic mixing. In this work, we present Fx-Encoder++, a novel model designed to extract instrument-wise audio effects representations from music mixtures. Our approach leverages a contrastive learning framework and introduces an "extractor" mechanism that, when provided with instrument queries (audio or text), transforms mixture-level audio effects embeddings into instrument-wise audio effects embeddings. We evaluated our model across retrieval and audio effects parameter matching tasks, testing its performance across a diverse range of instruments. The results demonstrate that Fx-Encoder++ outperforms previous approaches at mixture level and show a novel ability to extract effects representation instrument-wise, addressing a critical capability gap in intelligent music production systems.
Towards Generalizability to Tone and Content Variations in the Transcription of Amplifier Rendered Electric Guitar Audio
Apr 10, 2025Transcribing electric guitar recordings is challenging due to the scarcity of diverse datasets and the complex tone-related variations introduced by amplifiers, cabinets, and effect pedals. To address these issues, we introduce EGDB-PG, a novel dataset designed to capture a wide range of tone-related characteristics across various amplifier-cabinet configurations. In addition, we propose the Tone-informed Transformer (TIT), a Transformer-based transcription model enhanced with a tone embedding mechanism that leverages learned representations to improve the model's adaptability to tone-related nuances. Experiments demonstrate that TIT, trained on EGDB-PG, outperforms existing baselines across diverse amplifier types, with transcription accuracy improvements driven by the dataset's diversity and the tone embedding technique. Through detailed benchmarking and ablation studies, we evaluate the impact of tone augmentation, content augmentation, audio normalization, and tone embedding on transcription performance. This work advances electric guitar transcription by overcoming limitations in dataset diversity and tone modeling, providing a robust foundation for future research.
AI TrackMate: Finally, Someone Who Will Give Your Music More Than Just "Sounds Great!"
Dec 09, 2024


The rise of "bedroom producers" has democratized music creation, while challenging producers to objectively evaluate their work. To address this, we present AI TrackMate, an LLM-based music chatbot designed to provide constructive feedback on music productions. By combining LLMs' inherent musical knowledge with direct audio track analysis, AI TrackMate offers production-specific insights, distinguishing it from text-only approaches. Our framework integrates a Music Analysis Module, an LLM-Readable Music Report, and Music Production-Oriented Feedback Instruction, creating a plug-and-play, training-free system compatible with various LLMs and adaptable to future advancements. We demonstrate AI TrackMate's capabilities through an interactive web interface and present findings from a pilot study with a music producer. By bridging AI capabilities with the needs of independent producers, AI TrackMate offers on-demand analytical feedback, potentially supporting the creative process and skill development in music production. This system addresses the growing demand for objective self-assessment tools in the evolving landscape of independent music production.
Demo of Zero-Shot Guitar Amplifier Modelling: Enhancing Modeling with Hyper Neural Networks
Oct 07, 2024
Electric guitar tone modeling typically focuses on the non-linear transformation from clean to amplifier-rendered audio. Traditional methods rely on one-to-one mappings, incorporating device parameters into neural models to replicate specific amplifiers. However, these methods are limited by the need for specific training data. In this paper, we adapt a model based on the previous work, which leverages a tone embedding encoder and a feature wise linear modulation (FiLM) condition method. In this work, we altered conditioning method using a hypernetwork-based gated convolutional network (GCN) to generate audio that blends clean input with the tone characteristics of reference audio. By extending the training data to cover a wider variety of amplifier tones, our model is able to capture a broader range of tones. Additionally, we developed a real-time plugin to demonstrate the system's practical application, allowing users to experience its performance interactively. Our results indicate that the proposed system achieves superior tone modeling versatility compared to traditional methods.
DDSP Guitar Amp: Interpretable Guitar Amplifier Modeling
Aug 21, 2024


Neural network models for guitar amplifier emulation, while being effective, often demand high computational cost and lack interpretability. Drawing ideas from physical amplifier design, this paper aims to address these issues with a new differentiable digital signal processing (DDSP)-based model, called ``DDSP guitar amp,'' that models the four components of a guitar amp (i.e., preamp, tone stack, power amp, and output transformer) using specific DSP-inspired designs. With a set of time- and frequency-domain metrics, we demonstrate that DDSP guitar amp achieves performance comparable with that of black-box baselines while requiring less than 10\% of the computational operations per audio sample, thereby holding greater potential for usages in real-time applications.
PyNeuralFx: A Python Package for Neural Audio Effect Modeling
Aug 12, 2024We present PyNeuralFx, an open-source Python toolkit designed for research on neural audio effect modeling. The toolkit provides an intuitive framework and offers a comprehensive suite of features, including standardized implementation of well-established model architectures, loss functions, and easy-to-use visualization tools. As such, it helps promote reproducibility for research on neural audio effect modeling, and enable in-depth performance comparison of different models, offering insight into the behavior and operational characteristics of models through DSP methodology. The toolkit can be found at https://github.com/ytsrt66589/pyneuralfx.
Hyper Recurrent Neural Network: Condition Mechanisms for Black-box Audio Effect Modeling
Aug 09, 2024Recurrent neural networks (RNNs) have demonstrated impressive results for virtual analog modeling of audio effects. These networks process time-domain audio signals using a series of matrix multiplication and nonlinear activation functions to emulate the behavior of the target device accurately. To additionally model the effect of the knobs for an RNN-based model, existing approaches integrate control parameters by concatenating them channel-wisely with some intermediate representation of the input signal. While this method is parameter-efficient, there is room to further improve the quality of generated audio because the concatenation-based conditioning method has limited capacity in modulating signals. In this paper, we propose three novel conditioning mechanisms for RNNs, tailored for black-box virtual analog modeling. These advanced conditioning mechanisms modulate the model based on control parameters, yielding superior results to existing RNN- and CNN-based architectures across various evaluation metrics.
Towards zero-shot amplifier modeling: One-to-many amplifier modeling via tone embedding control
Jul 15, 2024



Replicating analog device circuits through neural audio effect modeling has garnered increasing interest in recent years. Existing work has predominantly focused on a one-to-one emulation strategy, modeling specific devices individually. In this paper, we tackle the less-explored scenario of one-to-many emulation, utilizing conditioning mechanisms to emulate multiple guitar amplifiers through a single neural model. For condition representation, we use contrastive learning to build a tone embedding encoder that extracts style-related features of various amplifiers, leveraging a dataset of comprehensive amplifier settings. Targeting zero-shot application scenarios, we also examine various strategies for tone embedding representation, evaluating referenced tone embedding against two retrieval-based embedding methods for amplifiers unseen in the training time. Our findings showcase the efficacy and potential of the proposed methods in achieving versatile one-to-many amplifier modeling, contributing a foundational step towards zero-shot audio modeling applications.
Exploiting Pre-trained Feature Networks for Generative Adversarial Networks in Audio-domain Loop Generation
Sep 05, 2022
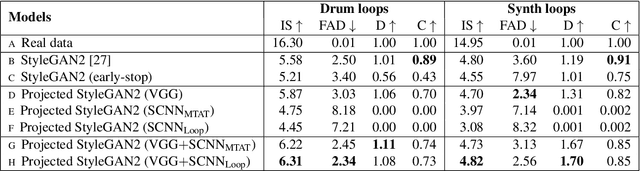

While generative adversarial networks (GANs) have been widely used in research on audio generation, the training of a GAN model is known to be unstable, time consuming, and data inefficient. Among the attempts to ameliorate the training process of GANs, the idea of Projected GAN emerges as an effective solution for GAN-based image generation, establishing the state-of-the-art in different image applications. The core idea is to use a pre-trained classifier to constrain the feature space of the discriminator to stabilize and improve GAN training. This paper investigates whether Projected GAN can similarly improve audio generation, by evaluating the performance of a StyleGAN2-based audio-domain loop generation model with and without using a pre-trained feature space in the discriminator. Moreover, we compare the performance of using a general versus domain-specific classifier as the pre-trained audio classifier. With experiments on both drum loop and synth loop generation, we show that a general audio classifier works better, and that with Projected GAN our loop generation models can converge around 5 times faster without performance degradation.
A Benchmarking Initiative for Audio-Domain Music Generation Using the Freesound Loop Dataset
Aug 03, 2021
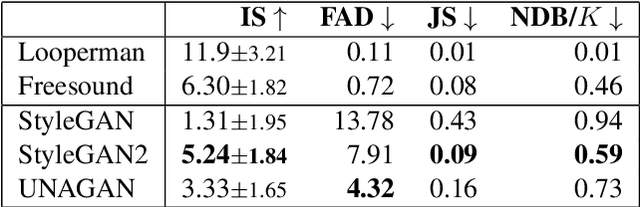
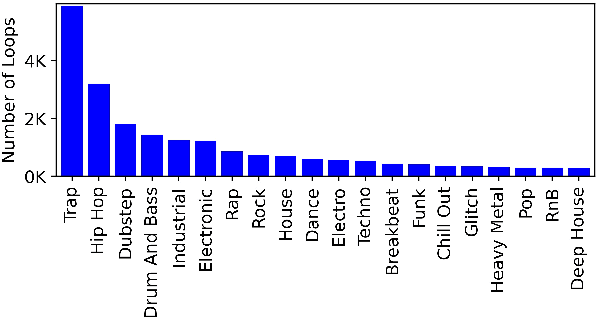

This paper proposes a new benchmark task for generat-ing musical passages in the audio domain by using thedrum loops from the FreeSound Loop Dataset, which arepublicly re-distributable. Moreover, we use a larger col-lection of drum loops from Looperman to establish fourmodel-based objective metrics for evaluation, releasingthese metrics as a library for quantifying and facilitatingthe progress of musical audio generation. Under this eval-uation framework, we benchmark the performance of threerecent deep generative adversarial network (GAN) mod-els we customize to generate loops, including StyleGAN,StyleGAN2, and UNAGAN. We also report a subjectiveevaluation of these models. Our evaluation shows that theone based on StyleGAN2 performs the best in both objec-tive and subjective metrics.