 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyNeuralFx: A Python Package for Neural Audio Effect Modeling
Aug 12, 2024We present PyNeuralFx, an open-source Python toolkit designed for research on neural audio effect modeling. The toolkit provides an intuitive framework and offers a comprehensive suite of features, including standardized implementation of well-established model architectures, loss functions, and easy-to-use visualization tools. As such, it helps promote reproducibility for research on neural audio effect modeling, and enable in-depth performance comparison of different models, offering insight into the behavior and operational characteristics of models through DSP methodology. The toolkit can be found at https://github.com/ytsrt66589/pyneuralfx.
Hyper Recurrent Neural Network: Condition Mechanisms for Black-box Audio Effect Modeling
Aug 09, 2024Recurrent neural networks (RNNs) have demonstrated impressive results for virtual analog modeling of audio effects. These networks process time-domain audio signals using a series of matrix multiplication and nonlinear activation functions to emulate the behavior of the target device accurately. To additionally model the effect of the knobs for an RNN-based model, existing approaches integrate control parameters by concatenating them channel-wisely with some intermediate representation of the input signal. While this method is parameter-efficient, there is room to further improve the quality of generated audio because the concatenation-based conditioning method has limited capacity in modulating signals. In this paper, we propose three novel conditioning mechanisms for RNNs, tailored for black-box virtual analog modeling. These advanced conditioning mechanisms modulate the model based on control parameters, yielding superior results to existing RNN- and CNN-based architectures across various evaluation metrics.
MusiConGen: Rhythm and Chord Control for Transformer-Based Text-to-Music Generation
Jul 21, 2024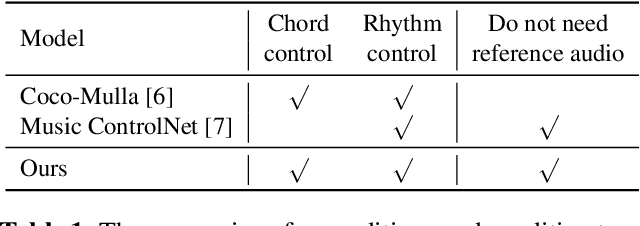
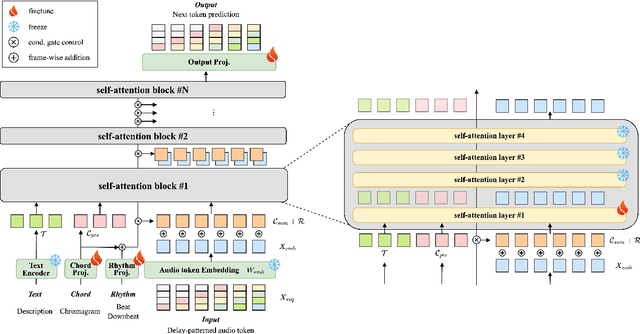
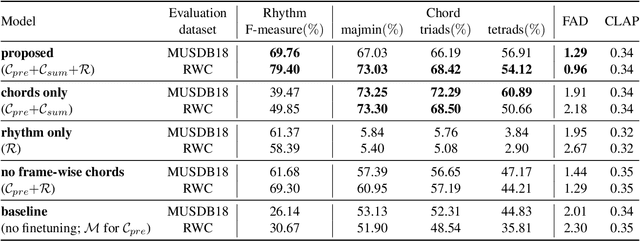
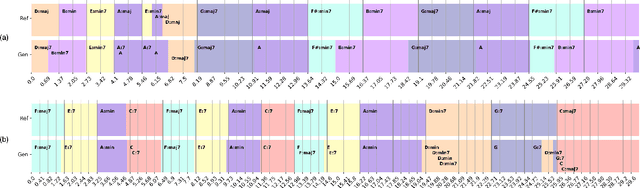
Existing text-to-music models can produce high-quality audio with great diversity. However, textual prompts alone cannot precisely control temporal musical features such as chords and rhythm of the generated music. To address this challenge, we introduce MusiConGen, a temporally-conditioned Transformer-based text-to-music model that builds upon the pretrained MusicGen framework. Our innovation lies in an efficient finetuning mechanism, tailored for consumer-grade GPUs, that integrates automatically-extracted rhythm and chords as the condition signal. During inference, the condition can either be musical features extracted from a reference audio signal, or be user-defined symbolic chord sequence, BPM, and textual prompts. Our performance evaluation on two datasets -- one derived from extracted features and the other from user-created inputs -- demonstrates that MusiConGen can generate realistic backing track music that aligns well with the specified conditions. We open-source the code and model checkpoints, and provide audio examples online, https://musicongen.github.io/musicongen_demo/.
DDSP-based Singing Vocoders: A New Subtractive-based Synthesizer and A Comprehensive Evaluation
Aug 19, 2022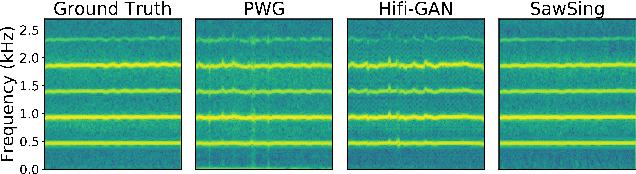
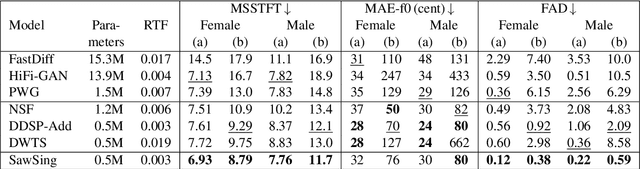
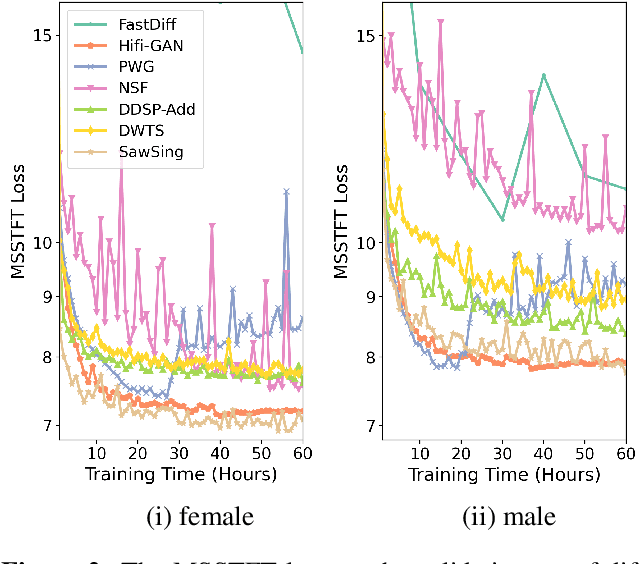
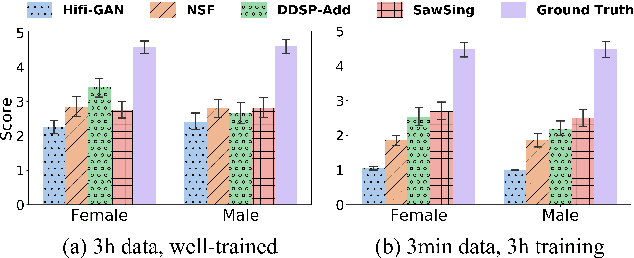
A vocoder is a conditional audio generation model that converts acoustic features such as mel-spectrograms into waveforms. Taking inspiration from Differentiable Digital Signal Processing (DDSP), we propose a new vocoder named SawSing for singing voices. SawSing synthesizes the harmonic part of singing voices by filtering a sawtooth source signal with a linear time-variant finite impulse response filter whose coefficients are estimated from the input mel-spectrogram by a neural network. As this approach enforces phase continuity, SawSing can generate singing voices without the phase-discontinuity glitch of many existing vocoders. Moreover, the source-filter assumption provides an inductive bias that allows SawSing to be trained on a small amount of data. Our experiments show that SawSing converges much faster and outperforms state-of-the-art generative adversarial network and diffusion-based vocoders in a resource-limited scenario with only 3 training recordings and a 3-hour training time.
* Accepted at ISMIR 2022
towards automatic transcription of polyphonic electric guitar music:a new dataset and a multi-loss transformer model
Feb 20, 2022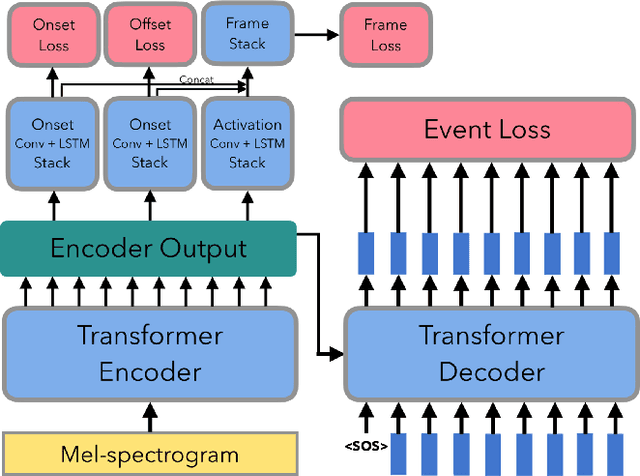
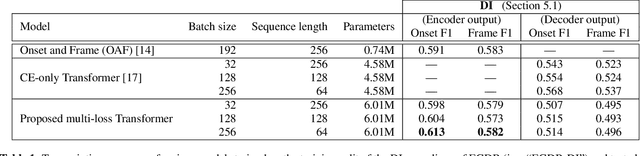

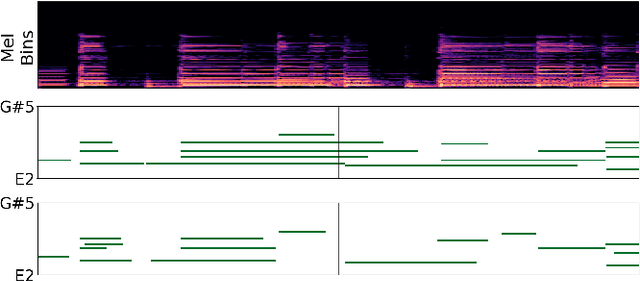
In this paper, we propose a new dataset named EGDB, that con-tains transcriptions of the electric guitar performance of 240 tab-latures rendered with different tones. Moreover, we benchmark theperformance of two well-known transcription models proposed orig-inally for the piano on this dataset, along with a multi-loss Trans-former model that we newly propose. Our evaluation on this datasetand a separate set of real-world recordings demonstrate the influenceof timbre on the accuracy of guitar sheet transcription, the potentialof using multiple losses for Transformers, as well as the room forfurther improvement for this task.
Source Separation-based Data Augmentation for Improved Joint Beat and Downbeat Tracking
Jun 16, 2021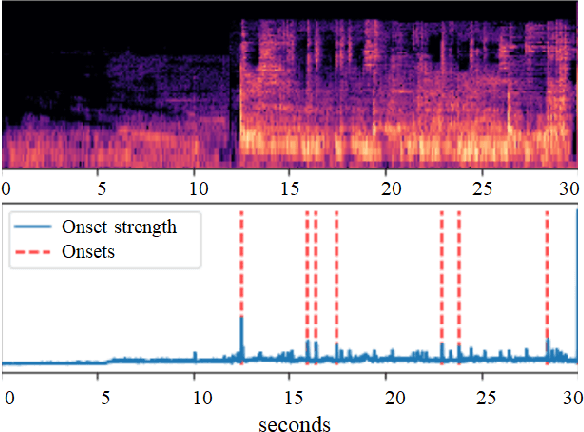
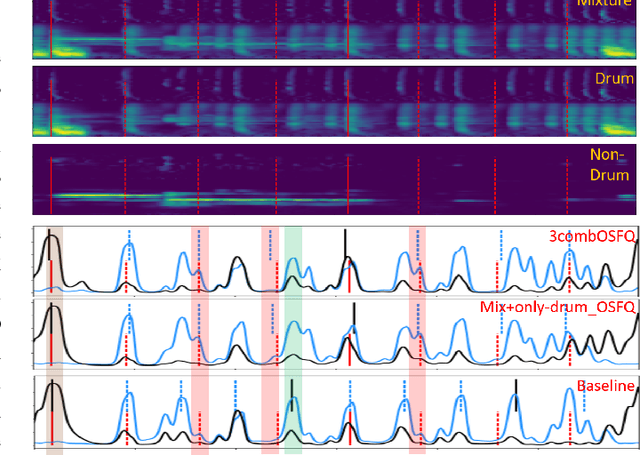
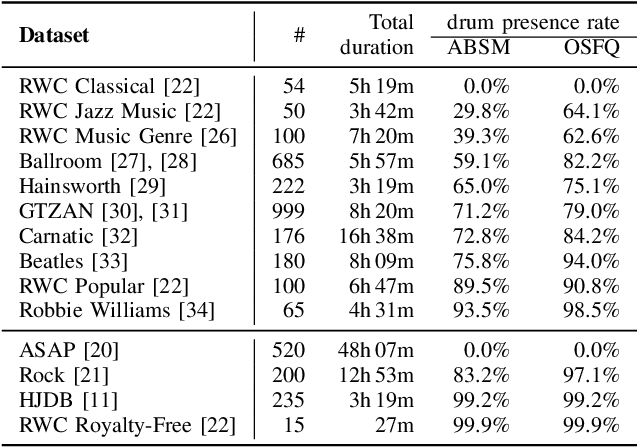
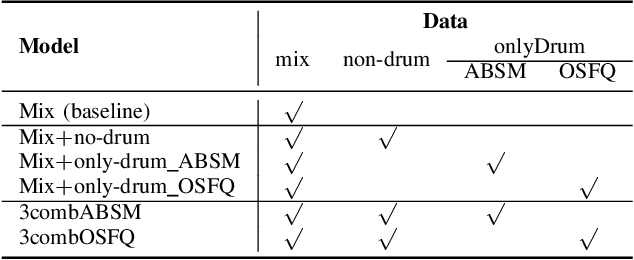
Due to advances in deep learning, the performance of automatic beat and downbeat tracking in musical audio signals has seen great improvement in recent years. In training such deep learning based models, data augmentation has been found an important technique. However, existing data augmentation methods for this task mainly target at balancing the distribution of the training data with respect to their tempo. In this paper, we investigate another approach for data augmentation, to account for the composition of the training data in terms of the percussive and non-percussive sound sources. Specifically, we propose to employ a blind drum separation model to segregate the drum and non-drum sounds from each training audio signal, filtering out training signals that are drumless, and then use the obtained drum and non-drum stems to augment the training data. We report experiments on four completely unseen test sets, validating the effectiveness of the proposed method, and accordingly the importance of drum sound composition in the training data for beat and downbeat tracking.
Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs
Jan 07, 2021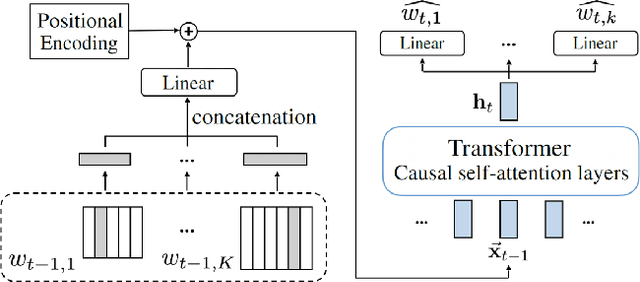
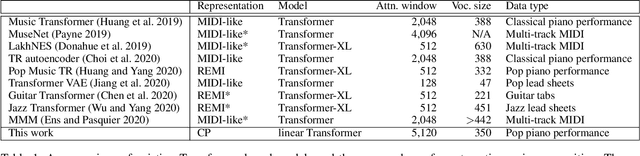
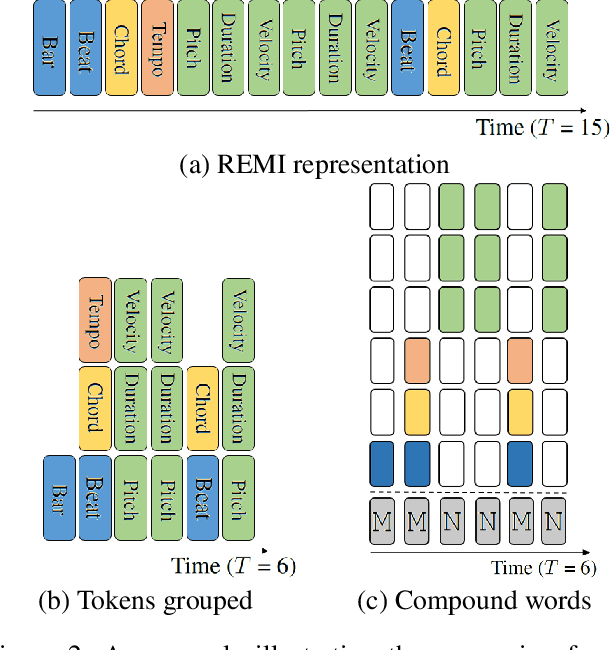

To apply neural sequence models such as the Transformers to music generation tasks, one has to represent a piece of music by a sequence of tokens drawn from a finite set of pre-defined vocabulary. Such a vocabulary usually involves tokens of various types. For example, to describe a musical note, one needs separate tokens to indicate the note's pitch, duration, velocity (dynamics), and placement (onset time) along the time grid. While different types of tokens may possess different properties, existing models usually treat them equally, in the same way as modeling words in natural languages. In this paper, we present a conceptually different approach that explicitly takes into account the type of the tokens, such as note types and metric types. And, we propose a new Transformer decoder architecture that uses different feed-forward heads to model tokens of different types. With an expansion-compression trick, we convert a piece of music to a sequence of compound words by grouping neighboring tokens, greatly reducing the length of the token sequences. We show that the resulting model can be viewed as a learner over dynamic directed hypergraphs. And, we employ it to learn to compose expressive Pop piano music of full-song length (involving up to 10K individual tokens per song), both conditionally and unconditionally. Our experiment shows that, compared to state-of-the-art models, the proposed model converges 5--10 times faster at training (i.e., within a day on a single GPU with 11 GB memory), and with comparable quality in the generated music.
Mixing-Specific Data Augmentation Techniques for Improved Blind Violin/Piano Source Separation
Aug 06, 2020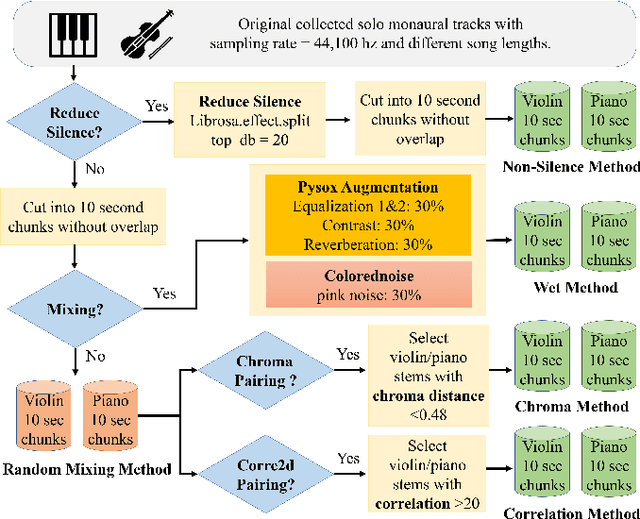
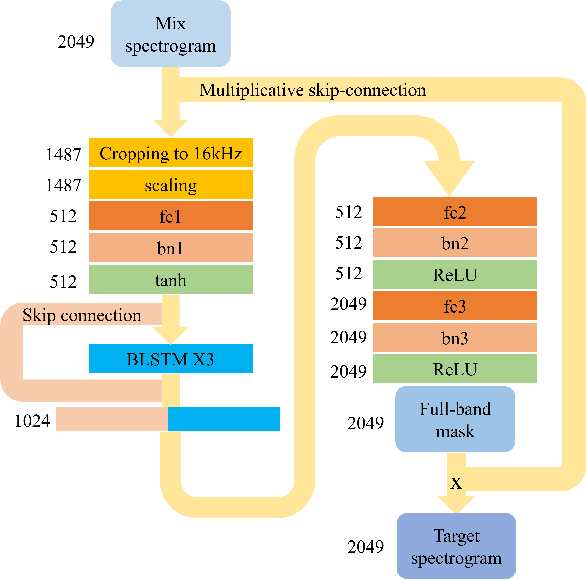
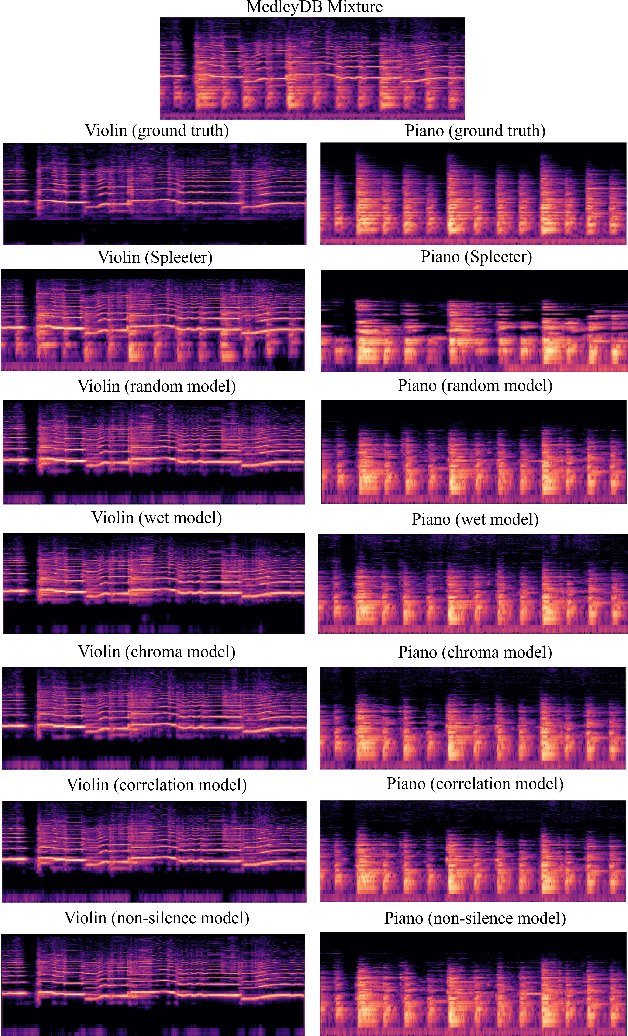
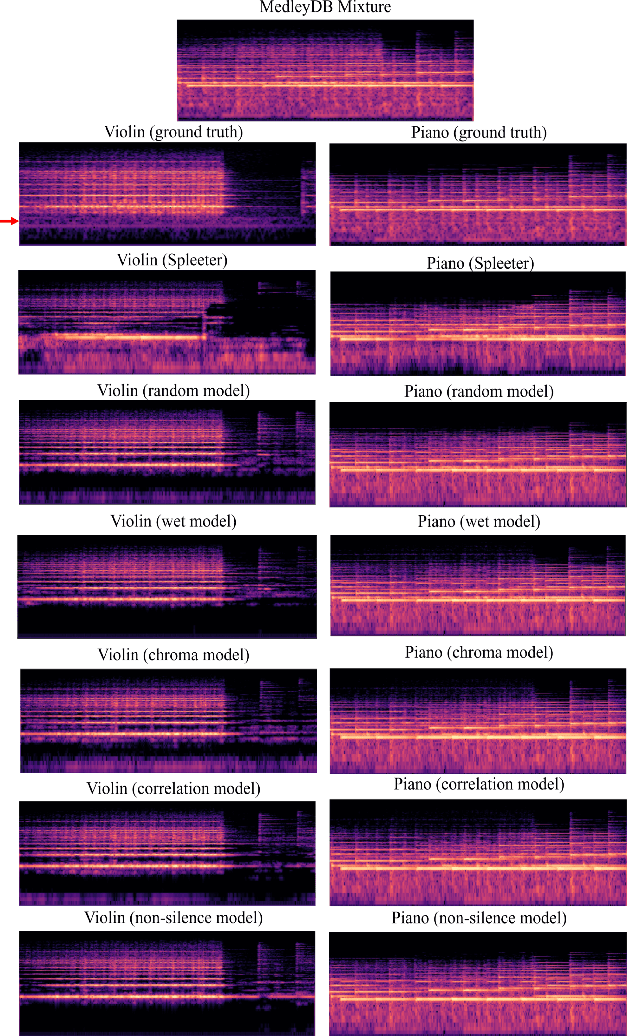
Blind music source separation has been a popular and active subject of research in both the music information retrieval and signal processing communities. To counter the lack of available multi-track data for supervised model training, a data augmentation method that creates artificial mixtures by combining tracks from different songs has been shown useful in recent works. Following this light, we examine further in this paper extended data augmentation methods that consider more sophisticated mixing settings employed in the modern music production routine, the relationship between the tracks to be combined, and factors of silence. As a case study, we consider the separation of violin and piano tracks in a violin piano ensemble, evaluating the performance in terms of common metrics, namely SDR, SIR, and SAR. In addition to examining the effectiveness of these new data augmentation methods, we also study the influence of the amount of training data. Our evaluation shows that the proposed mixing-specific data augmentation methods can help improve the performance of a deep learning-based model for source separation, especially in the case of small training data.
Automatic Melody Harmonization with Triad Chords: A Comparative Study
Jan 08, 2020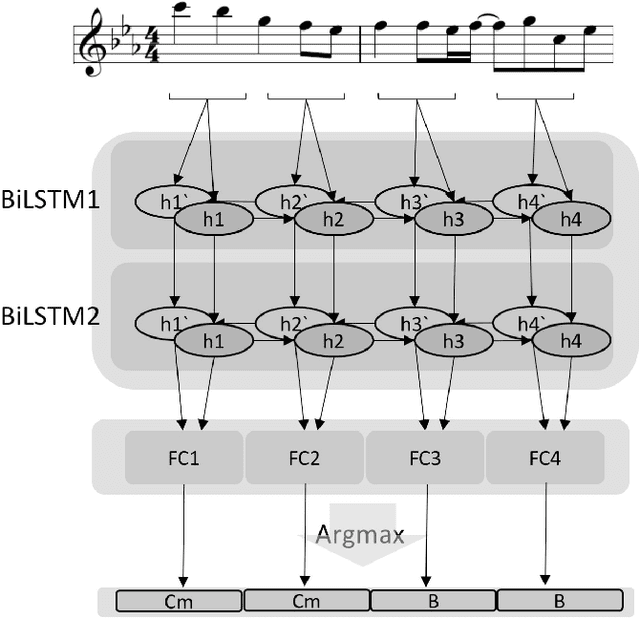
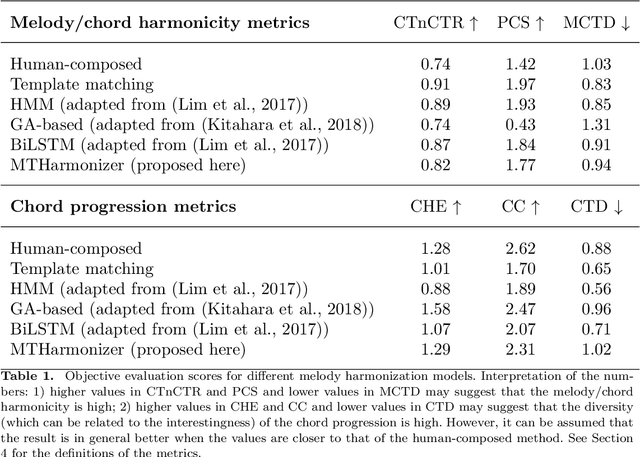
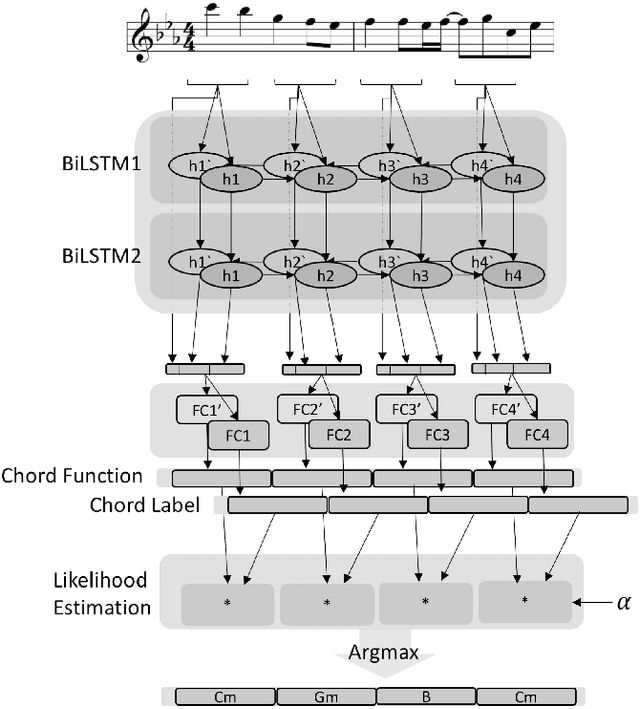

Several prior works have proposed various methods for the task of automatic melody harmonization, in which a model aims to generate a sequence of chords to serve as the harmonic accompaniment of a given multiple-bar melody sequence. In this paper, we present a comparative study evaluating and comparing the performance of a set of canonical approaches to this task, including a template matching based model, a hidden Markov based model, a genetic algorithm based model, and two deep learning based models. The evaluation is conducted on a dataset of 9,226 melody/chord pairs we newly collect for this study, considering up to 48 triad chords, using a standardized training/test split. We report the result of an objective evaluation using six different metrics and a subjective study with 202 participants.
MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment
Nov 24, 2017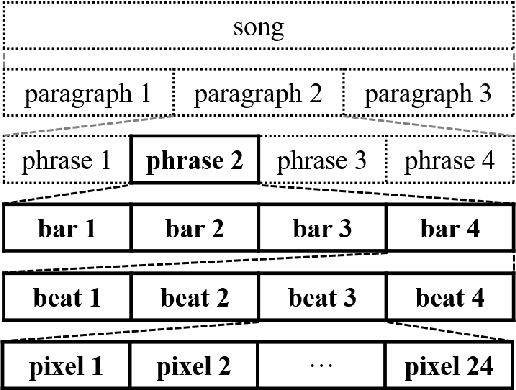
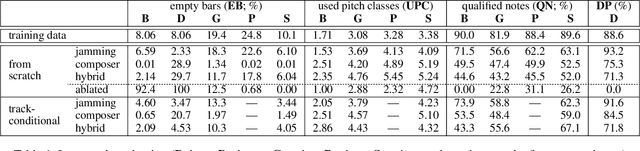
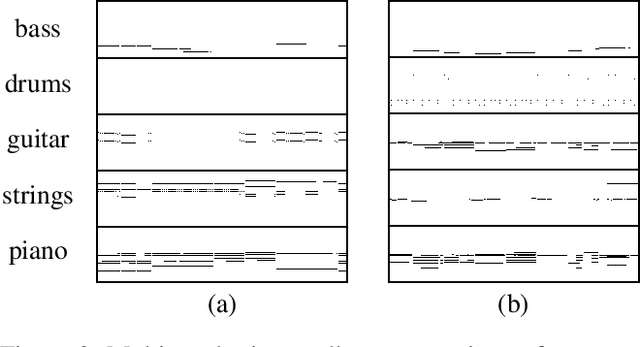
Generating music has a few notable differences from generating images and videos. First, music is an art of time, necessitating a temporal model. Second, music is usually composed of multiple instruments/tracks with their own temporal dynamics, but collectively they unfold over time interdependently. Lastly, musical notes are often grouped into chords, arpeggios or melodies in polyphonic music, and thereby introducing a chronological ordering of notes is not naturally suitable. In this paper, we propose three models for symbolic multi-track music generation under the framework of generative adversarial networks (GANs). The three models, which differ in the underlying assumptions and accordingly the network architectures, are referred to as the jamming model, the composer model and the hybrid model. We trained the proposed models on a dataset of over one hundred thousand bars of rock music and applied them to generate piano-rolls of five tracks: bass, drums, guitar, piano and strings. A few intra-track and inter-track objective metrics are also proposed to evaluate the generative results, in addition to a subjective user study. We show that our models can generate coherent music of four bars right from scratch (i.e. without human inputs). We also extend our models to human-AI cooperative music generation: given a specific track composed by human, we can generate four additional tracks to accompany it. All code, the dataset and the rendered audio samples are available at https://salu133445.github.io/musegan/ .