 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDSP-based Singing Vocoders: A New Subtractive-based Synthesizer and A Comprehensive Evaluation
Aug 19, 2022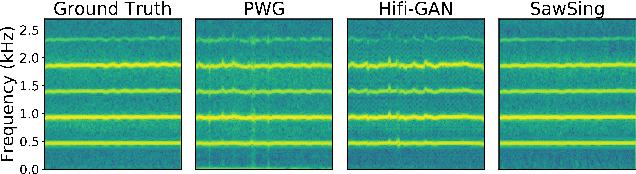
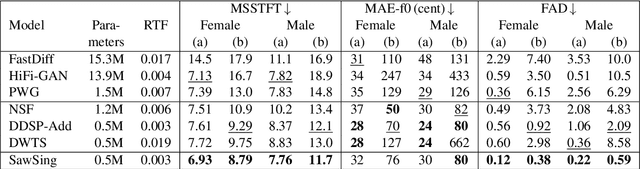
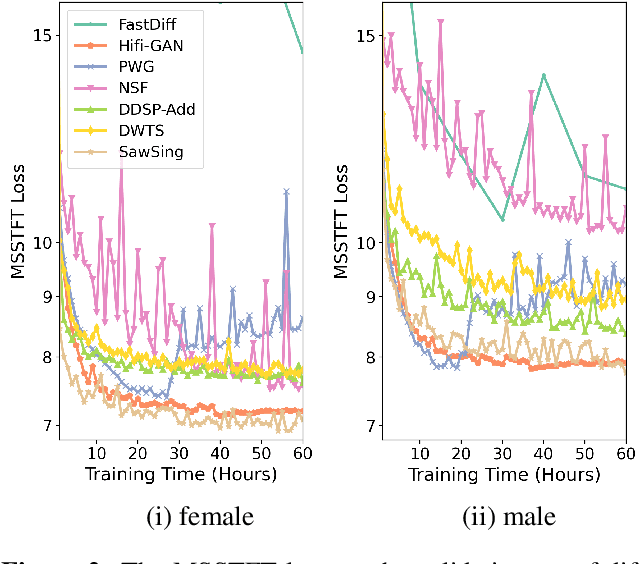
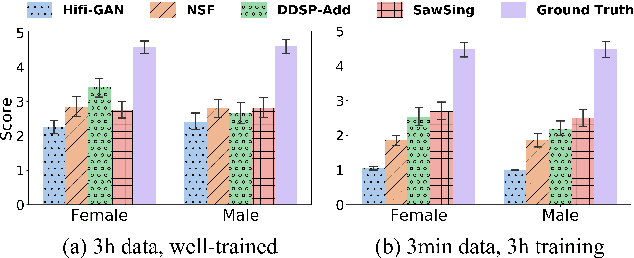
A vocoder is a conditional audio generation model that converts acoustic features such as mel-spectrograms into waveforms. Taking inspiration from Differentiable Digital Signal Processing (DDSP), we propose a new vocoder named SawSing for singing voices. SawSing synthesizes the harmonic part of singing voices by filtering a sawtooth source signal with a linear time-variant finite impulse response filter whose coefficients are estimated from the input mel-spectrogram by a neural network. As this approach enforces phase continuity, SawSing can generate singing voices without the phase-discontinuity glitch of many existing vocoders. Moreover, the source-filter assumption provides an inductive bias that allows SawSing to be trained on a small amount of data. Our experiments show that SawSing converges much faster and outperforms state-of-the-art generative adversarial network and diffusion-based vocoders in a resource-limited scenario with only 3 training recordings and a 3-hour training time.
* Accepted at ISMIR 2022
A Survey on Recent Deep Learning-driven Singing Voice Synthesis Systems
Oct 06, 2021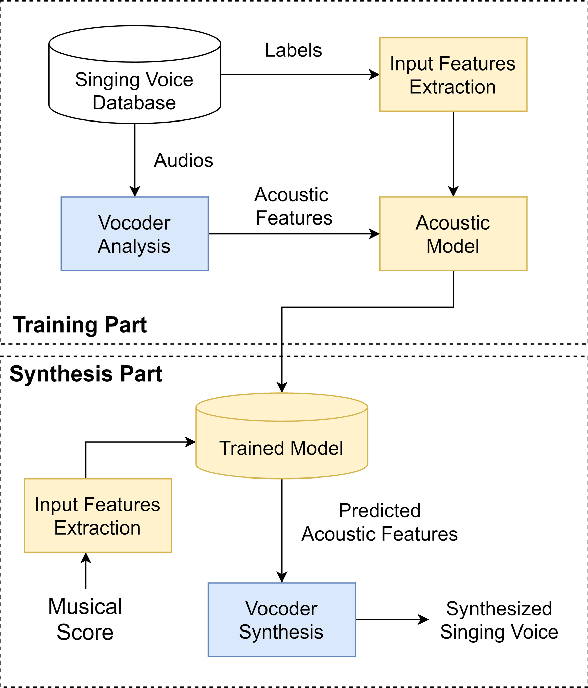
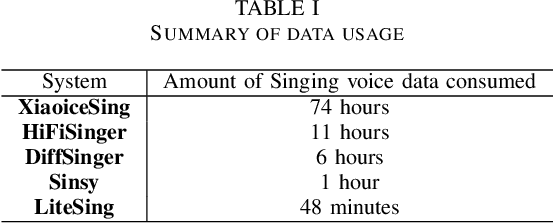
Singing voice synthesis (SVS) is a task that aims to generate audio signals according to musical scores and lyrics. With its multifaceted nature concerning music and language, producing singing voices indistinguishable from that of human singers has always remained an unfulfilled pursuit. Nonetheless, the advancements of deep learning techniques have brought about a substantial leap in the quality and naturalness of synthesized singing voice. This paper aims to review some of the state-of-the-art deep learning-driven SVS systems. We intend to summarize their deployed model architectures and identify the strengths and limitations for each of the introduced systems. Thereby, we picture the recent advancement trajectory of this field and conclude the challenges left to be resolved both in commercial applications and academic research.