 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-Driven Large Language Models for Mandarin Lyric Generation
Oct 02, 2024Generative Large Language Models have shown impressive in-context learning abilities, performing well across various tasks with just a prompt. Previous melody-to-lyric research has been limited by scarce high-quality aligned data and unclear standard for creativeness. Most efforts focused on general themes or emotions, which are less valuable given current language model capabilities. In tonal contour languages like Mandarin, pitch contours are influenced by both melody and tone, leading to variations in lyric-melody fit. Our study, validated by the Mpop600 dataset, confirms that lyricists and melody writers consider this fit during their composition process. In this research, we developed a multi-agent system that decomposes the melody-to-lyric task into sub-tasks, with each agent controlling rhyme, syllable count, lyric-melody alignment, and consistency. Listening tests were conducted via a diffusion-based singing voice synthesizer to evaluate the quality of lyrics generated by different agent groups.
Effects of Convolutional Autoencoder Bottleneck Width on StarGAN-based Singing Technique Conversion
Aug 19, 2023Singing technique conversion (STC) refers to the task of converting from one voice technique to another while leaving the original singer identity, melody, and linguistic components intact. Previous STC studies, as well as singing voice conversion research in general, have utilized convolutional autoencoders (CAEs) for conversion, but how the bottleneck width of the CAE affects the synthesis quality has not been thoroughly evaluated. To this end, we constructed a GAN-based multi-domain STC system which took advantage of the WORLD vocoder representation and the CAE architecture. We varied the bottleneck width of the CAE, and evaluated the conversion results subjectively. The model was trained on a Mandarin dataset which features four singers and four singing techniques: the chest voice, the falsetto, the raspy voice, and the whistle voice. The results show that a wider bottleneck corresponds to better articulation clarity but does not necessarily lead to higher likeness to the target technique. Among the four techniques, we also found that the whistle voice is the easiest target for conversion, while the other three techniques as a source produce more convincing conversion results than the whistle.
Mandarin Singing Voice Synthesis with Denoising Diffusion Probabilistic Wasserstein GAN
Sep 21, 2022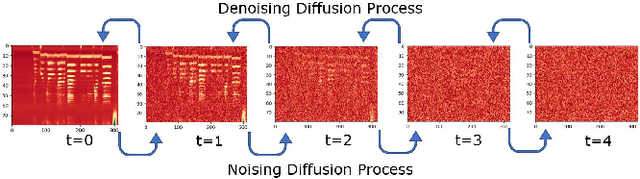

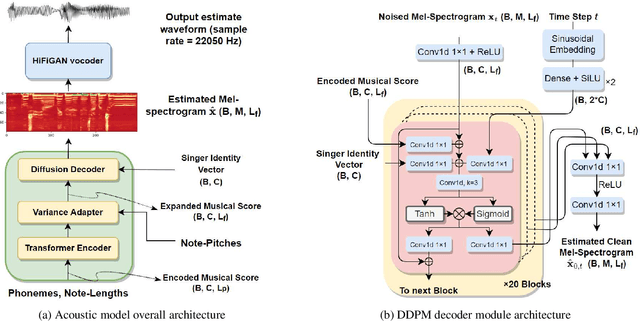
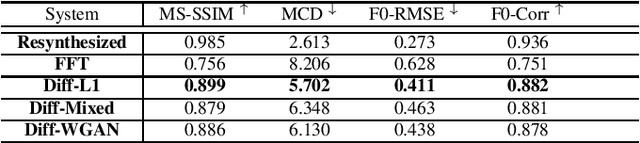
Singing voice synthesis (SVS) is the computer production of a human-like singing voice from given musical scores. To accomplish end-to-end SVS effectively and efficiently, this work adopts the acoustic model-neural vocoder architecture established for high-quality speech and singing voice synthesis. Specifically, this work aims to pursue a higher level of expressiveness in synthesized voices by combining the diffusion denoising probabilistic model (DDPM) and \emph{Wasserstein} generative adversarial network (WGAN) to construct the backbone of the acoustic model. On top of the proposed acoustic model, a HiFi-GAN neural vocoder is adopted with integrated fine-tuning to ensure optimal synthesis quality for the resulting end-to-end SVS system. This end-to-end system was evaluated with the multi-singer Mpop600 Mandarin singing voice dataset. In the experiments, the proposed system exhibits improvements over previous landmark counterparts in terms of musical expressiveness and high-frequency acoustic details. Moreover, the adversarial acoustic model converged stably without the need to enforce reconstruction objectives, indicating the convergence stability of the proposed DDPM and WGAN combined architecture over alternative GAN-based SVS systems.
DDSP-based Singing Vocoders: A New Subtractive-based Synthesizer and A Comprehensive Evaluation
Aug 19, 2022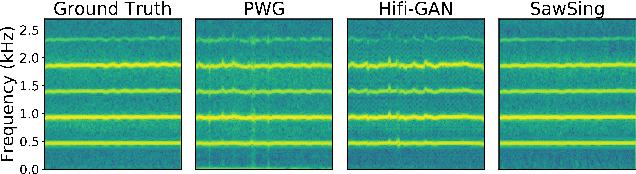
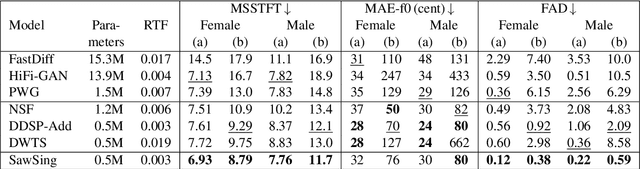
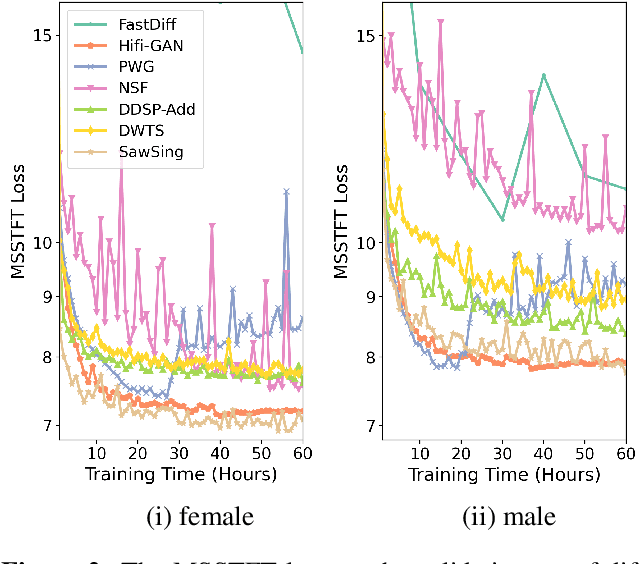
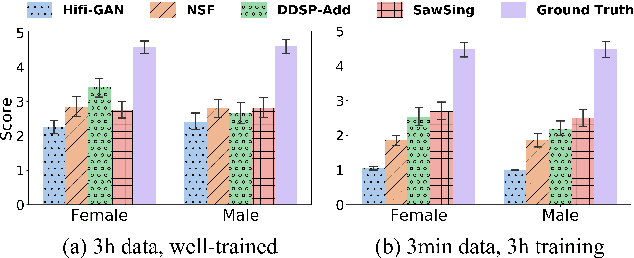
A vocoder is a conditional audio generation model that converts acoustic features such as mel-spectrograms into waveforms. Taking inspiration from Differentiable Digital Signal Processing (DDSP), we propose a new vocoder named SawSing for singing voices. SawSing synthesizes the harmonic part of singing voices by filtering a sawtooth source signal with a linear time-variant finite impulse response filter whose coefficients are estimated from the input mel-spectrogram by a neural network. As this approach enforces phase continuity, SawSing can generate singing voices without the phase-discontinuity glitch of many existing vocoders. Moreover, the source-filter assumption provides an inductive bias that allows SawSing to be trained on a small amount of data. Our experiments show that SawSing converges much faster and outperforms state-of-the-art generative adversarial network and diffusion-based vocoders in a resource-limited scenario with only 3 training recordings and a 3-hour training time.
* Accepted at ISMIR 2022
Domestic sound event detection by shift consistency mean-teacher training and adversarial domain adaptation
Aug 17, 2022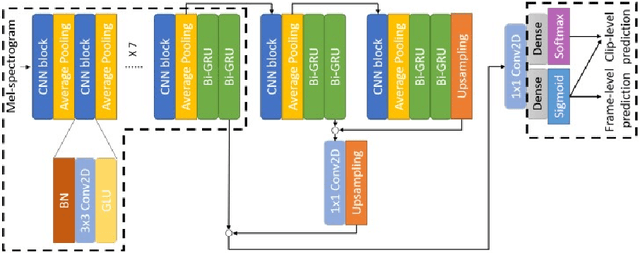

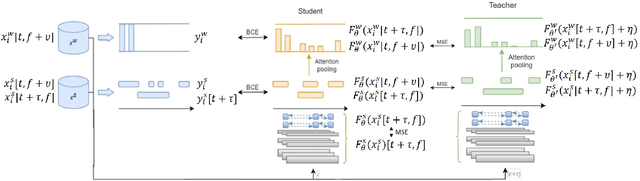
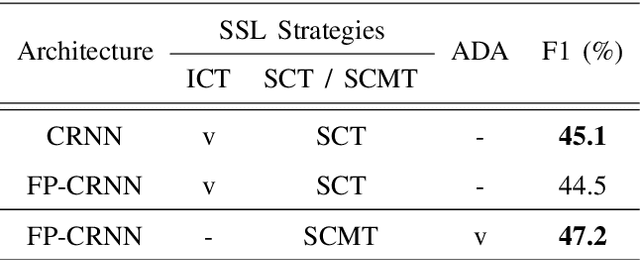
Semi-supervised learning and domain adaptation techniques have drawn increasing attention in the field of domestic sound event detection thanks to the availability of large amounts of unlabeled data and the relative ease to generate synthetic strongly-labeled data. In a previous work, several semi-supervised learning strategies were designed to boost the performance of a mean-teacher model. Namely, these strategies include shift consistency training (SCT), interpolation consistency training (ICT), and pseudo-labeling. However, adversarial domain adaptation (ADA) did not seem to improve the event detection accuracy further when we attempt to compensate for the domain gap between synthetic and real data. In this research, we empirically found that ICT tends to pull apart the distributions of synthetic and real data in t-SNE plots. Therefore, ICT is abandoned while SCT, in contrast, is applied to train both the student and the teacher models. With these modifications, the system successfully integrates with an ADA network, and we achieve 47.2% in the F1 score on the DCASE 2020 task 4 dataset, which is 2.1% higher than what was reported in the previous work.
A Survey on Recent Deep Learning-driven Singing Voice Synthesis Systems
Oct 06, 2021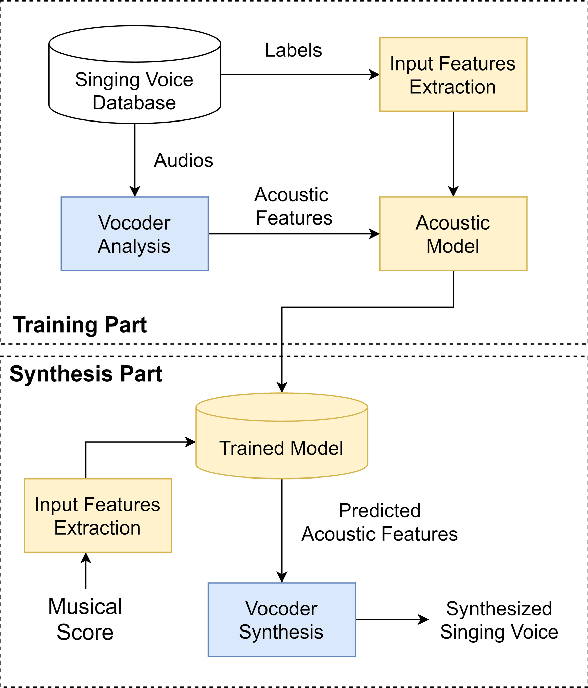
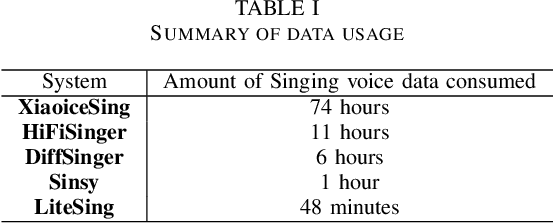
Singing voice synthesis (SVS) is a task that aims to generate audio signals according to musical scores and lyrics. With its multifaceted nature concerning music and language, producing singing voices indistinguishable from that of human singers has always remained an unfulfilled pursuit. Nonetheless, the advancements of deep learning techniques have brought about a substantial leap in the quality and naturalness of synthesized singing voice. This paper aims to review some of the state-of-the-art deep learning-driven SVS systems. We intend to summarize their deployed model architectures and identify the strengths and limitations for each of the introduced systems. Thereby, we picture the recent advancement trajectory of this field and conclude the challenges left to be resolved both in commercial applications and academic research.
Meniere's Disease Prognosis by Learning from Transient-Evoked Otoacoustic Emission Signals
May 30, 2019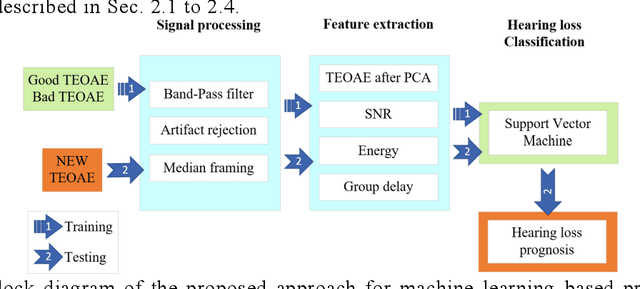
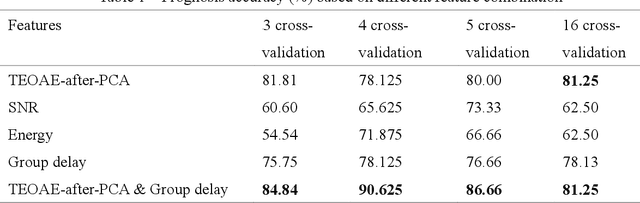
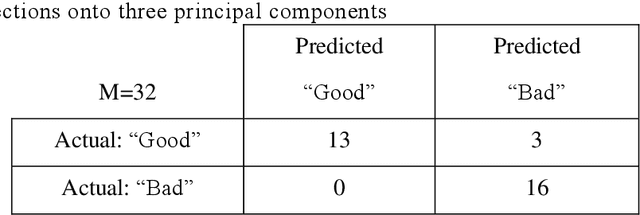
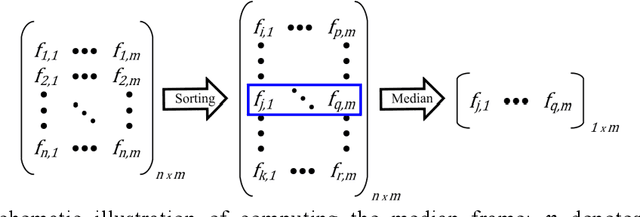
Accurate prognosis of Meniere disease (MD) is difficult. The aim of this study is to treat it as a machine-learning problem through the analysis of transient-evoked (TE) otoacoustic emission (OAE) data obtained from MD patients. Thirty-three patients who received treatment were recruited, and their distortion-product (DP) OAE, TEOAE, as well as pure-tone audiograms were taken longitudinally up to 6 months after being diagnosed with MD. By hindsight, the patients were separated into two groups: those whose outer hair cell (OHC) functions eventually recovered, and those that did not. TEOAE signals between 2.5-20 ms were dimension-reduced via principal component analysis, and binary classification was performed via the support vector machine. Through cross-validation, we demonstrate that the accuracy of prognosis can reach >80% based on data obtained at the first visit. Further analysis also shows that the TEOAE group delay at 1k and 2k Hz tend to be longer for the group of ears that eventually recovered their OHC functions. The group delay can further be compared between the MD-affected ear and the opposite ear. The present results suggest that TEOAE signals provide abundant information for the prognosis of MD and the information could be extracted by applying machine-learning techniques.