 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSurvey-Bench: Evaluating Academic Value of Automatically Generated Scientific Survey
Jan 13, 2026The rapid development of automated scientific survey generation technology has made it increasingly important to establish a comprehensive benchmark to evaluate the quality of generated surveys.Nearly all existing evaluation benchmarks rely on flawed selection criteria such as citation counts and structural coherence to select human-written surveys as the ground truth survey datasets, and then use surface-level metrics such as structural quality and reference relevance to evaluate generated surveys.However, these benchmarks have two key issues: (1) the ground truth survey datasets are unreliable because of a lack academic dimension annotations; (2) the evaluation metrics only focus on the surface quality of the survey such as logical coherence. Both issues lead to existing benchmarks cannot assess to evaluate their deep "academic value", such as the core research objectives and the critical analysis of different studies. To address the above problems, we propose DeepSurvey-Bench, a novel benchmark designed to comprehensively evaluate the academic value of generated surveys. Specifically, our benchmark propose a comprehensive academic value evaluation criteria covering three dimensions: informational value, scholarly communication value, and research guidance value. Based on this criteria, we construct a reliable dataset with academic value annotations, and evaluate the deep academic value of the generated surveys. Extensive experimental results demonstrate that our benchmark is highly consistent with human performance in assessing the academic value of generated surveys.
Exposing the Functionalities of Neurons for Gated Recurrent Unit Based Sequence-to-Sequence Model
Mar 27, 2023The goal of this paper is to report certain scientific discoveries about a Seq2Seq model. It is known that analyzing the behavior of RNN-based models at the neuron level is considered a more challenging task than analyzing a DNN or CNN models due to their recursive mechanism in nature. This paper aims to provide neuron-level analysis to explain why a vanilla GRU-based Seq2Seq model without attention can achieve token-positioning. We found four different types of neurons: storing, counting, triggering, and outputting and further uncover the mechanism for these neurons to work together in order to produce the right token in the right position.
DDSP-based Singing Vocoders: A New Subtractive-based Synthesizer and A Comprehensive Evaluation
Aug 19, 2022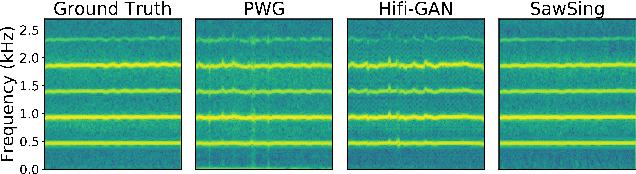
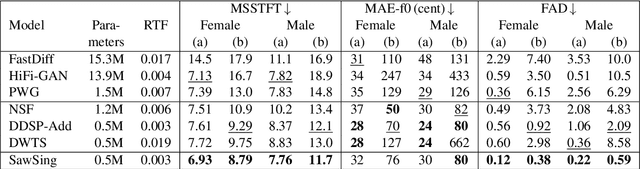
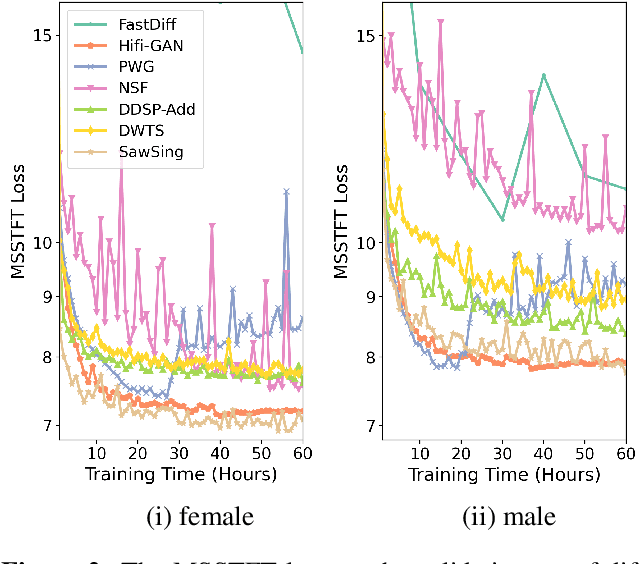
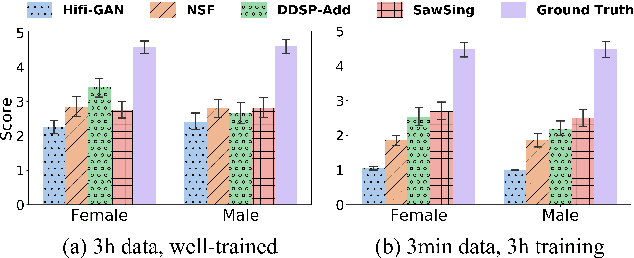
A vocoder is a conditional audio generation model that converts acoustic features such as mel-spectrograms into waveforms. Taking inspiration from Differentiable Digital Signal Processing (DDSP), we propose a new vocoder named SawSing for singing voices. SawSing synthesizes the harmonic part of singing voices by filtering a sawtooth source signal with a linear time-variant finite impulse response filter whose coefficients are estimated from the input mel-spectrogram by a neural network. As this approach enforces phase continuity, SawSing can generate singing voices without the phase-discontinuity glitch of many existing vocoders. Moreover, the source-filter assumption provides an inductive bias that allows SawSing to be trained on a small amount of data. Our experiments show that SawSing converges much faster and outperforms state-of-the-art generative adversarial network and diffusion-based vocoders in a resource-limited scenario with only 3 training recordings and a 3-hour training time.
* Accepted at ISMIR 2022
VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net architecture
Jun 07, 2020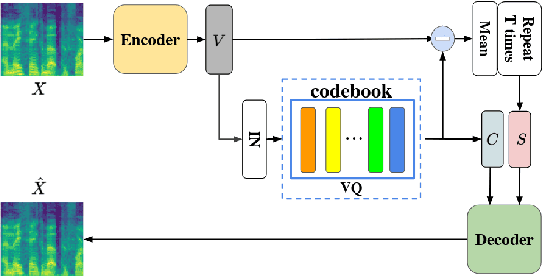
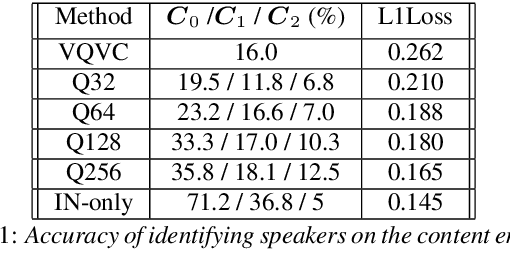
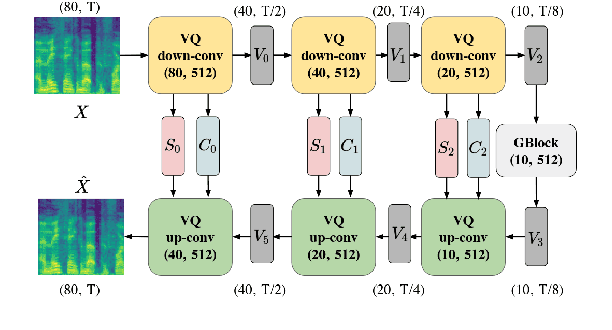
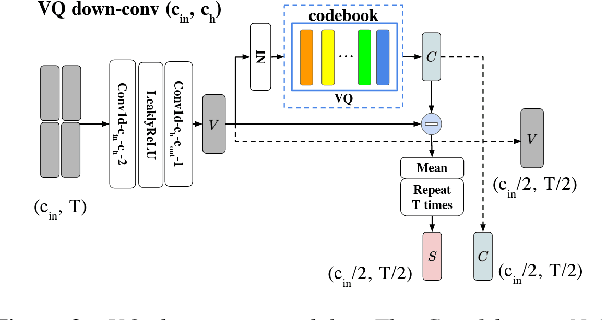
Voice conversion (VC) is a task that transforms the source speaker's timbre, accent, and tones in audio into another one's while preserving the linguistic content. It is still a challenging work, especially in a one-shot setting. Auto-encoder-based VC methods disentangle the speaker and the content in input speech without given the speaker's identity, so these methods can further generalize to unseen speakers. The disentangle capability is achieved by vector quantization (VQ), adversarial training, or instance normalization (IN). However, the imperfect disentanglement may harm the quality of output speech. In this work, to further improve audio quality, we use the U-Net architecture within an auto-encoder-based VC system. We find that to leverage the U-Net architecture, a strong information bottleneck is necessary. The VQ-based method, which quantizes the latent vectors, can serve the purpose. The objective and the subjective evaluations show that the proposed method performs well in both audio naturalness and speaker similarity.
Speech-to-Singing Conversion based on Boundary Equilibrium GAN
May 30, 2020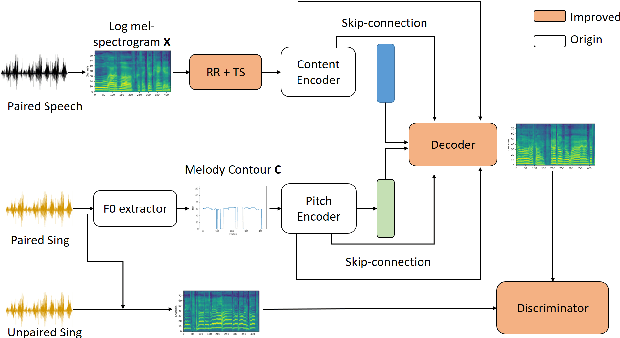
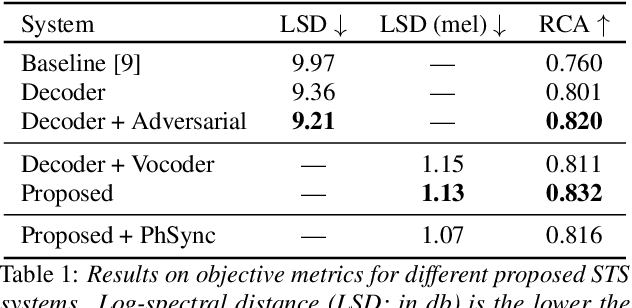
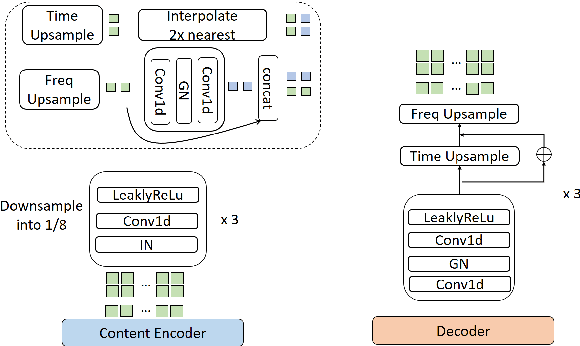
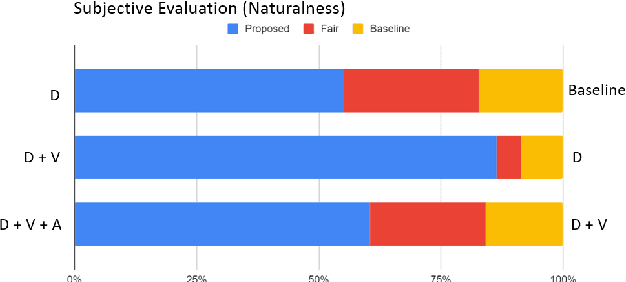
This paper investigates the use of generative adversarial network (GAN)-based models for converting the spectrogram of a speech signal into that of a singing one, without reference to the phoneme sequence underlying the speech. This is achieved by viewing speech-to-singing conversion as a style transfer problem. Specifically, given a speech input, and optionally the F0 contour of the target singing, the proposed model generates as the output a singing signal with a progressive-growing encoder/decoder architecture and boundary equilibrium GAN loss functions. Our quantitative and qualitative analysis show that the proposed model generates singing voices with much higher naturalness than an existing non adversarially-trained baseline. For reproducibility, the code will be publicly available at a GitHub repository upon paper publication.