 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Landscape of Spoken Language Models: A Comprehensive Survey
Apr 11, 2025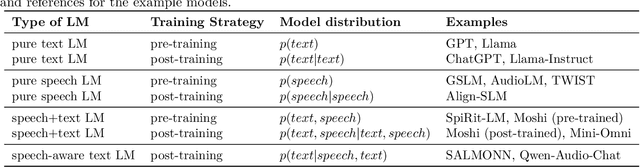
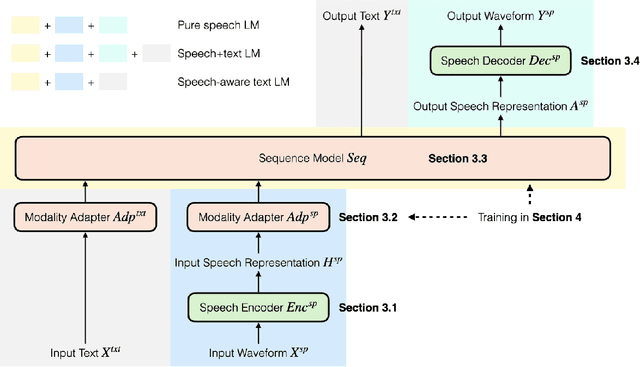
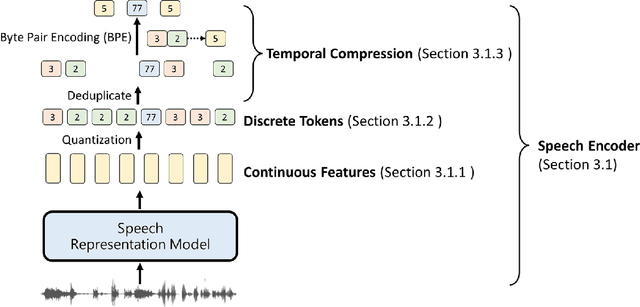
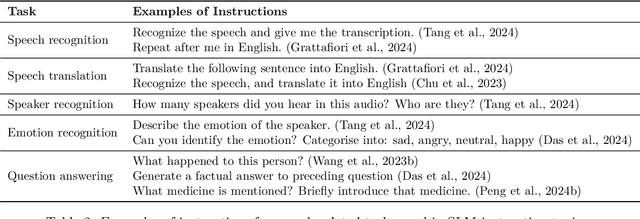
The field of spoken language processing is undergoing a shift from training custom-built, task-specific models toward using and optimizing spoken language models (SLMs) which act as universal speech processing systems. This trend is similar to the progression toward universal language models that has taken place in the field of (text) natural language processing. SLMs include both "pure" language models of speech -- models of the distribution of tokenized speech sequences -- and models that combine speech encoders with text language models, often including both spoken and written input or output. Work in this area is very diverse, with a range of terminology and evaluation settings. This paper aims to contribute an improved understanding of SLMs via a unifying literature survey of recent work in the context of the evolution of the field. Our survey categorizes the work in this area by model architecture, training, and evaluation choices, and describes some key challenges and directions for future work.
Investigating Video Reasoning Capability of Large Language Models with Tropes in Movies
Jun 16, 2024



Large Language Models (LLMs) have demonstrated effectiveness not only in language tasks but also in video reasoning. This paper introduces a novel dataset, Tropes in Movies (TiM), designed as a testbed for exploring two critical yet previously overlooked video reasoning skills: (1) Abstract Perception: understanding and tokenizing abstract concepts in videos, and (2) Long-range Compositional Reasoning: planning and integrating intermediate reasoning steps for understanding long-range videos with numerous frames. Utilizing tropes from movie storytelling, TiM evaluates the reasoning capabilities of state-of-the-art LLM-based approaches. Our experiments show that current methods, including Captioner-Reasoner, Large Multimodal Model Instruction Fine-tuning, and Visual Programming, only marginally outperform a random baseline when tackling the challenges of Abstract Perception and Long-range Compositional Reasoning. To address these deficiencies, we propose Face-Enhanced Viper of Role Interactions (FEVoRI) and Context Query Reduction (ConQueR), which enhance Visual Programming by fostering role interaction awareness and progressively refining movie contexts and trope queries during reasoning processes, significantly improving performance by 15 F1 points. However, this performance still lags behind human levels (40 vs. 65 F1). Additionally, we introduce a new protocol to evaluate the necessity of Abstract Perception and Long-range Compositional Reasoning for task resolution. This is done by analyzing the code generated through Visual Programming using an Abstract Syntax Tree (AST), thereby confirming the increased complexity of TiM. The dataset and code are available at: https://ander1119.github.io/TiM
EMO-SUPERB: An In-depth Look at Speech Emotion Recognition
Feb 22, 2024Speech emotion recognition (SER) is a pivotal technology for human-computer interaction systems. However, 80.77% of SER papers yield results that cannot be reproduced. We develop EMO-SUPERB, short for EMOtion Speech Universal PERformance Benchmark, which aims to enhance open-source initiatives for SER. EMO-SUPERB includes a user-friendly codebase to leverage 15 state-of-the-art speech self-supervised learning models (SSLMs) for exhaustive evaluation across six open-source SER datasets. EMO-SUPERB streamlines result sharing via an online leaderboard, fostering collaboration within a community-driven benchmark and thereby enhancing the development of SER. On average, 2.58% of annotations are annotated using natural language. SER relies on classification models and is unable to process natural languages, leading to the discarding of these valuable annotations. We prompt ChatGPT to mimic annotators, comprehend natural language annotations, and subsequently re-label the data. By utilizing labels generated by ChatGPT, we consistently achieve an average relative gain of 3.08% across all settings.
Examining Forgetting in Continual Pre-training of Aligned Large Language Models
Jan 06, 2024Recent advances in Large Language Models (LLMs) have exhibited remarkable proficiency across various tasks. Given the potent applications of LLMs in numerous fields, there has been a surge in LLM development. In developing LLMs, a common practice involves continual pre-training on previously fine-tuned models. However, this can lead to catastrophic forgetting. In our work, we investigate the phenomenon of forgetting that occurs during continual pre-training on an existing fine-tuned LLM. We evaluate the impact of continuous pre-training on the fine-tuned LLM across various dimensions, including output format, knowledge, and reliability. Experiment results highlight the non-trivial challenge of addressing catastrophic forgetting during continual pre-training, especially the repetition issue.
Hierarchical Programmatic Reinforcement Learning via Learning to Compose Programs
Jan 30, 2023



Aiming to produce reinforcement learning (RL) policies that are human-interpretable and can generalize better to novel scenarios, Trivedi et al. (2021) present a method (LEAPS) that first learns a program embedding space to continuously parameterize diverse programs from a pre-generated program dataset, and then searches for a task-solving program in the learned program embedding space when given a task. Despite encouraging results, the program policies that LEAPS can produce are limited by the distribution of the program dataset. Furthermore, during searching, LEAPS evaluates each candidate program solely based on its return, failing to precisely reward correct parts of programs and penalize incorrect parts. To address these issues, we propose to learn a meta-policy that composes a series of programs sampled from the learned program embedding space. By composing programs, our proposed method can produce program policies that describe out-of-distributionally complex behaviors and directly assign credits to programs that induce desired behaviors. We design and conduct extensive experiments in the Karel domain. The experimental results show that our proposed framework outperforms baselines. The ablation studies confirm the limitations of LEAPS and justify our design choices.
SLUE Phase-2: A Benchmark Suite of Diverse Spoken Language Understanding Tasks
Dec 20, 2022Spoken language understanding (SLU) tasks have been studied for many decades in the speech research community, but have not received as much attention as lower-level tasks like speech and speaker recognition. In particular, there are not nearly as many SLU task benchmarks, and many of the existing ones use data that is not freely available to all researchers. Recent work has begun to introduce such benchmark datasets for several tasks. In this work, we introduce several new annotated SLU benchmark tasks based on freely available speech data, which complement existing benchmarks and address gaps in the SLU evaluation landscape. We contribute four tasks: question answering and summarization involve inference over longer speech sequences; named entity localization addresses the speech-specific task of locating the targeted content in the signal; dialog act classification identifies the function of a given speech utterance. We follow the blueprint of the Spoken Language Understanding Evaluation (SLUE) benchmark suite. In order to facilitate the development of SLU models that leverage the success of pre-trained speech representations, we will be publishing for each task (i) annotations for a relatively small fine-tuning set, (ii) annotated development and test sets, and (iii) baseline models for easy reproducibility and comparisons. In this work, we present the details of data collection and annotation and the performance of the baseline models. We also perform sensitivity analysis of pipeline models' performance (speech recognizer + text model) to the speech recognition accuracy, using more than 20 state-of-the-art speech recognition models.
The Ability of Self-Supervised Speech Models for Audio Representations
Sep 28, 2022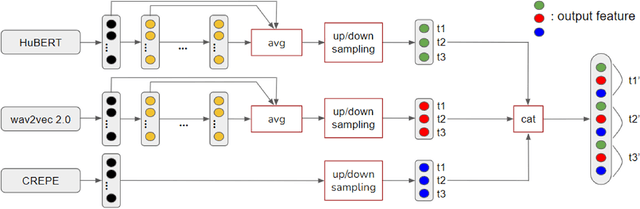
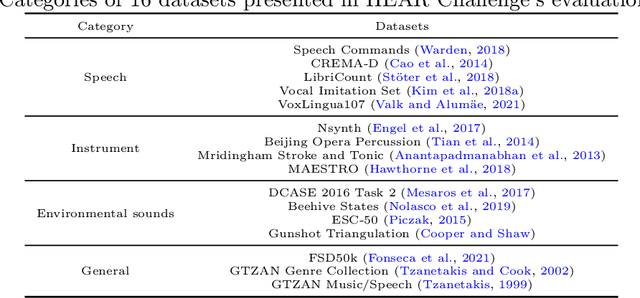
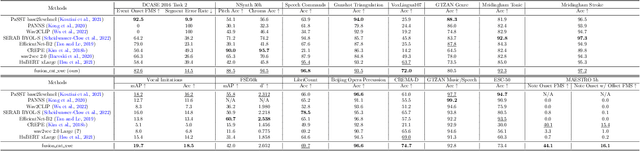

Self-supervised learning (SSL) speech models have achieved unprecedented success in speech representation learning, but some questions regarding their representation ability remain unanswered. This paper addresses two of them: (1) Can SSL speech models deal with non-speech audio?; (2) Would different SSL speech models have insights into diverse aspects of audio features? To answer the two questions, we conduct extensive experiments on abundant speech and non-speech audio datasets to evaluate the representation ability of currently state-of-the-art SSL speech models, which are wav2vec 2.0 and HuBERT in this paper. These experiments are carried out during NeurIPS 2021 HEAR Challenge as a standard evaluation pipeline provided by competition officials. Results show that (1) SSL speech models could extract meaningful features of a wide range of non-speech audio, while they may also fail on certain types of datasets; (2) different SSL speech models have insights into different aspects of audio features. The two conclusions provide a foundation for the ensemble of representation models. We further propose an ensemble framework to fuse speech representation models' embeddings. Our framework outperforms state-of-the-art SSL speech/audio models and has generally superior performance on abundant datasets compared with other teams in HEAR Challenge. Our code is available at https://github.com/tony10101105/HEAR-2021-NeurIPS-Challenge -- NTU-GURA.
On the Efficiency of Integrating Self-supervised Learning and Meta-learning for User-defined Few-shot Keyword Spotting
Apr 01, 2022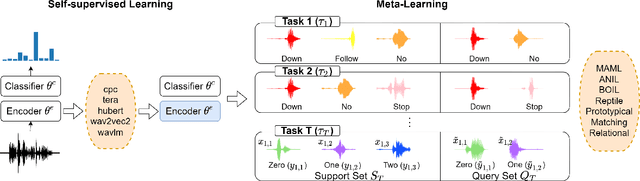
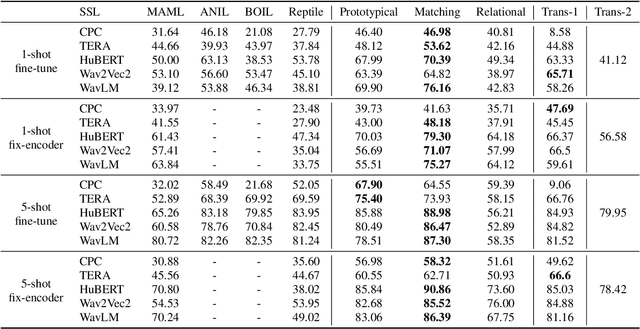
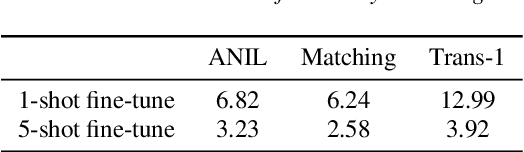
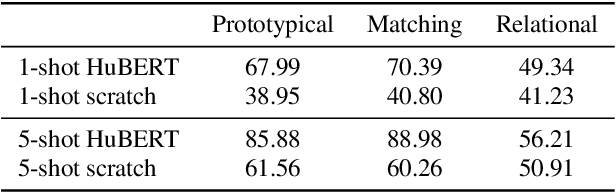
User-defined keyword spotting is a task to detect new spoken terms defined by users. This can be viewed as a few-shot learning problem since it is unreasonable for users to define their desired keywords by providing many examples. To solve this problem, previous works try to incorporate self-supervised learning models or apply meta-learning algorithms. But it is unclear whether self-supervised learning and meta-learning are complementary and which combination of the two types of approaches is most effective for few-shot keyword discovery. In this work, we systematically study these questions by utilizing various self-supervised learning models and combining them with a wide variety of meta-learning algorithms. Our result shows that HuBERT combined with Matching network achieves the best result and is robust to the changes of few-shot examples.
Partially Fake Audio Detection by Self-attention-based Fake Span Discovery
Feb 15, 2022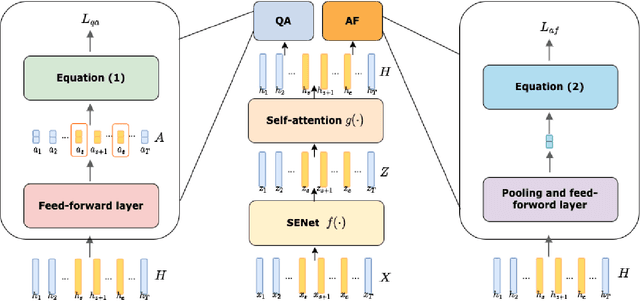
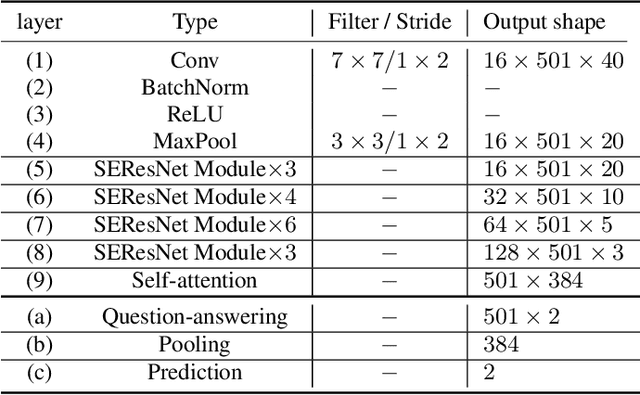

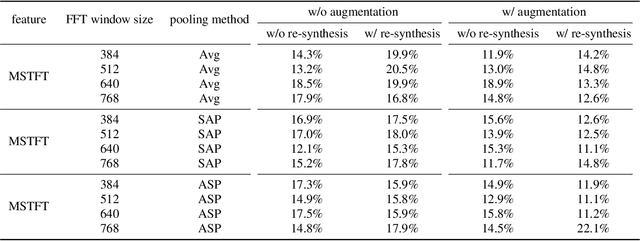
The past few years have witnessed the significant advances of speech synthesis and voice conversion technologies. However, such technologies can undermine the robustness of broadly implemented biometric identification models and can be harnessed by in-the-wild attackers for illegal uses. The ASVspoof challenge mainly focuses on synthesized audios by advanced speech synthesis and voice conversion models, and replay attacks. Recently, the first Audio Deep Synthesis Detection challenge (ADD 2022) extends the attack scenarios into more aspects. Also ADD 2022 is the first challenge to propose the partially fake audio detection task. Such brand new attacks are dangerous and how to tackle such attacks remains an open question. Thus, we propose a novel framework by introducing the question-answering (fake span discovery) strategy with the self-attention mechanism to detect partially fake audios. The proposed fake span detection module tasks the anti-spoofing model to predict the start and end positions of the fake clip within the partially fake audio, address the model's attention into discovering the fake spans rather than other shortcuts with less generalization, and finally equips the model with the discrimination capacity between real and partially fake audios. Our submission ranked second in the partially fake audio detection track of ADD 2022.
S3PRL-VC: Open-source Voice Conversion Framework with Self-supervised Speech Representations
Oct 12, 2021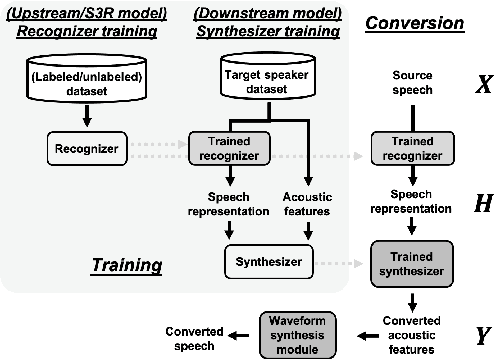
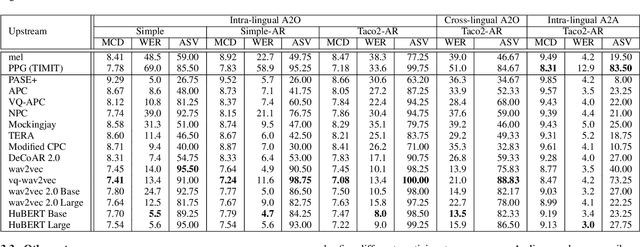
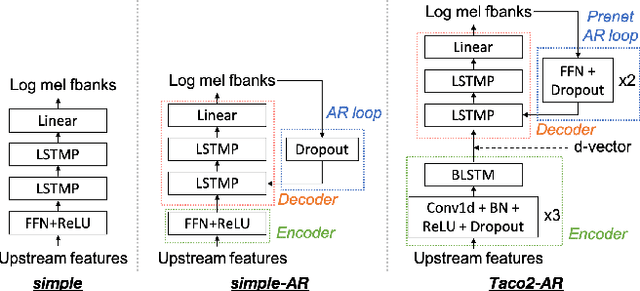
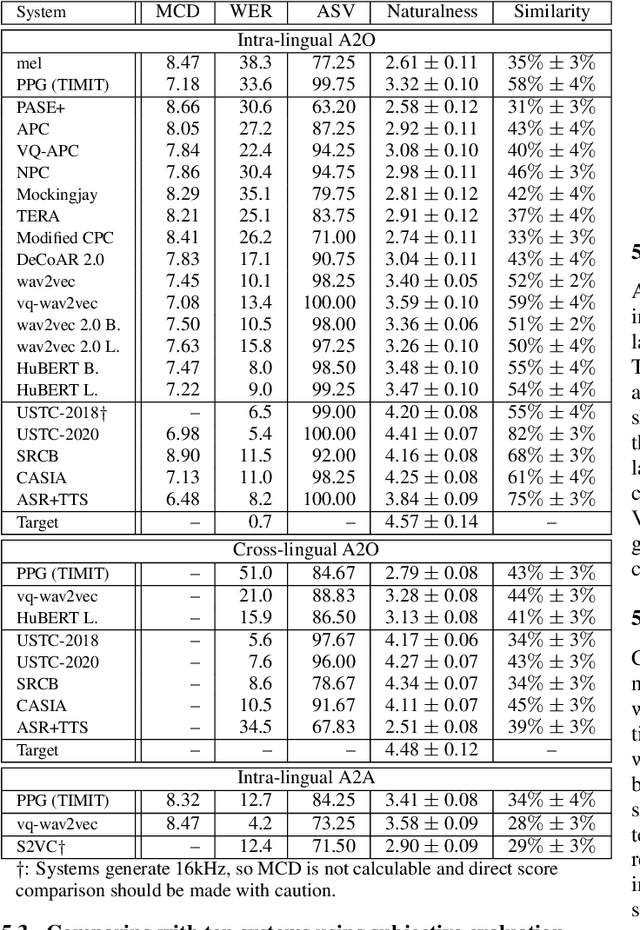
This paper introduces S3PRL-VC, an open-source voice conversion (VC) framework based on the S3PRL toolkit. In the context of recognition-synthesis VC, self-supervised speech representation (S3R) is valuable in its potential to replace the expensive supervised representation adopted by state-of-the-art VC systems. Moreover, we claim that VC is a good probing task for S3R analysis. In this work, we provide a series of in-depth analyses by benchmarking on the two tasks in VCC2020, namely intra-/cross-lingual any-to-one (A2O) VC, as well as an any-to-any (A2A) setting. We also provide comparisons between not only different S3Rs but also top systems in VCC2020 with supervised representations. Systematic objective and subjective evaluation were conducted, and we show that S3R is comparable with VCC2020 top systems in the A2O setting in terms of similarity, and achieves state-of-the-art in S3R-based A2A VC. We believe the extensive analysis, as well as the toolkit itself, contribute to not only the S3R community but also the VC community. The codebase is now open-sourced.