 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ability of Self-Supervised Speech Models for Audio Representations
Paper and Code
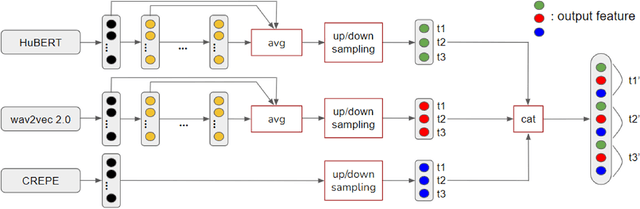
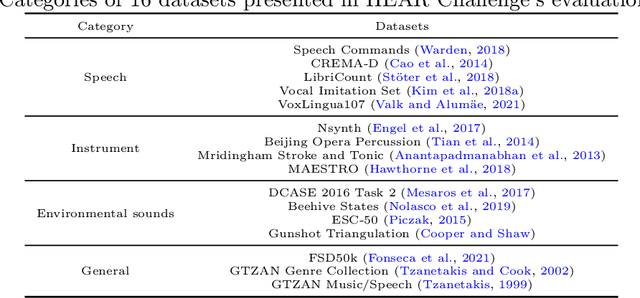
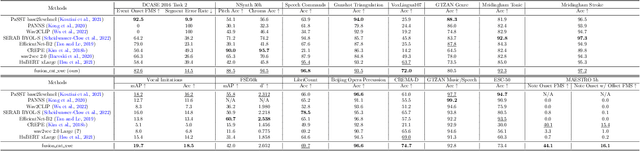

Self-supervised learning (SSL) speech models have achieved unprecedented success in speech representation learning, but some questions regarding their representation ability remain unanswered. This paper addresses two of them: (1) Can SSL speech models deal with non-speech audio?; (2) Would different SSL speech models have insights into diverse aspects of audio features? To answer the two questions, we conduct extensive experiments on abundant speech and non-speech audio datasets to evaluate the representation ability of currently state-of-the-art SSL speech models, which are wav2vec 2.0 and HuBERT in this paper. These experiments are carried out during NeurIPS 2021 HEAR Challenge as a standard evaluation pipeline provided by competition officials. Results show that (1) SSL speech models could extract meaningful features of a wide range of non-speech audio, while they may also fail on certain types of datasets; (2) different SSL speech models have insights into different aspects of audio features. The two conclusions provide a foundation for the ensemble of representation models. We further propose an ensemble framework to fuse speech representation models' embeddings. Our framework outperforms state-of-the-art SSL speech/audio models and has generally superior performance on abundant datasets compared with other teams in HEAR Challenge. Our code is available at https://github.com/tony10101105/HEAR-2021-NeurIPS-Challenge -- NTU-GURA.