 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploration of Mamba for Speech Self-Supervised Models
Jun 14, 2025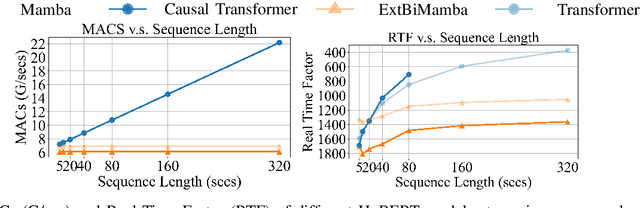
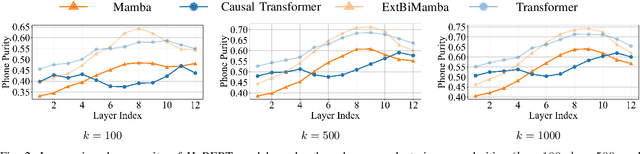
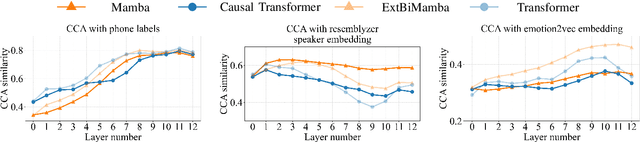
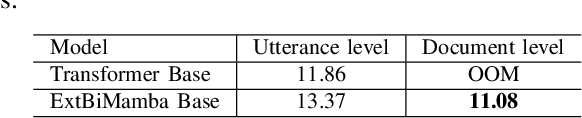
While Mamba has demonstrated strong performance in language modeling, its potential as a speech self-supervised (SSL) model remains underexplored, with prior studies limited to isolated tasks. To address this, we explore Mamba-based HuBERT models as alternatives to Transformer-based SSL architectures. Leveraging the linear-time Selective State Space, these models enable fine-tuning on long-context ASR with significantly lower compute. Moreover, they show superior performance when fine-tuned for streaming ASR. Beyond fine-tuning, these models show competitive performance on SUPERB probing benchmarks, particularly in causal settings. Our analysis shows that they yield higher-quality quantized representations and capture speaker-related features more distinctly than Transformer-based models. These findings highlight Mamba-based SSL as a promising and complementary direction for long-sequence modeling, real-time speech modeling, and speech unit extraction.
Detecting the Undetectable: Assessing the Efficacy of Current Spoof Detection Methods Against Seamless Speech Edits
Jan 07, 2025



Neural speech editing advancements have raised concerns about their misuse in spoofing attacks. Traditional partially edited speech corpora primarily focus on cut-and-paste edits, which, while maintaining speaker consistency, often introduce detectable discontinuities. Recent methods, like A\textsuperscript{3}T and Voicebox, improve transitions by leveraging contextual information. To foster spoofing detection research, we introduce the Speech INfilling Edit (SINE) dataset, created with Voicebox. We detailed the process of re-implementing Voicebox training and dataset creation. Subjective evaluations confirm that speech edited using this novel technique is more challenging to detect than conventional cut-and-paste methods. Despite human difficulty, experimental results demonstrate that self-supervised-based detectors can achieve remarkable performance in detection, localization, and generalization across different edit methods. The dataset and related models will be made publicly available.
Scalable Ensemble-based Detection Method against Adversarial Attacks for speaker verification
Dec 14, 2023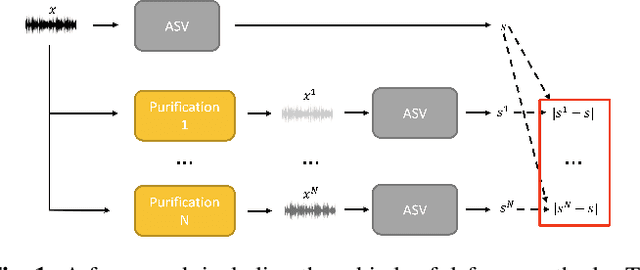

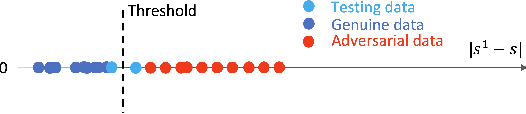
Automatic speaker verification (ASV) is highly susceptible to adversarial attacks. Purification modules are usually adopted as a pre-processing to mitigate adversarial noise. However, they are commonly implemented across diverse experimental settings, rendering direct comparisons challenging. This paper comprehensively compares mainstream purification techniques in a unified framework. We find these methods often face a trade-off between user experience and security, as they struggle to simultaneously maintain genuine sample performance and reduce adversarial perturbations. To address this challenge, some efforts have extended purification modules to encompass detection capabilities, aiming to alleviate the trade-off. However, advanced purification modules will always come into the stage to surpass previous detection method. As a result, we further propose an easy-to-follow ensemble approach that integrates advanced purification modules for detection, achieving state-of-the-art (SOTA) performance in countering adversarial noise. Our ensemble method has great potential due to its compatibility with future advanced purification techniques.
The 2nd Workshop on Maritime Computer Vision 2024
Nov 23, 2023



The 2nd Workshop on Maritime Computer Vision (MaCVi) 2024 addresses maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicles (USV). Three challenges categories are considered: (i) UAV-based Maritime Object Tracking with Re-identification, (ii) USV-based Maritime Obstacle Segmentation and Detection, (iii) USV-based Maritime Boat Tracking. The USV-based Maritime Obstacle Segmentation and Detection features three sub-challenges, including a new embedded challenge addressing efficicent inference on real-world embedded devices. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 195 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi24.
Sea You Later: Metadata-Guided Long-Term Re-Identification for UAV-Based Multi-Object Tracking
Nov 06, 2023



Re-identification (ReID) in multi-object tracking (MOT) for UAVs in maritime computer vision has been challenging for several reasons. More specifically, short-term re-identification (ReID) is difficult due to the nature of the characteristics of small targets and the sudden movement of the drone's gimbal. Long-term ReID suffers from the lack of useful appearance diversity. In response to these challenges, we present an adaptable motion-based MOT algorithm, called Metadata Guided MOT (MG-MOT). This algorithm effectively merges short-term tracking data into coherent long-term tracks, harnessing crucial metadata from UAVs, including GPS position, drone altitude, and camera orientations. Extensive experiments are conducted to validate the efficacy of our MOT algorithm. Utilizing the challenging SeaDroneSee tracking dataset, which encompasses the aforementioned scenarios, we achieve a much-improved performance in the latest edition of the UAV-based Maritime Object Tracking Challenge with a state-of-the-art HOTA of 69.5% and an IDF1 of 85.9% on the testing split.
Study on the Correlation between Objective Evaluations and Subjective Speech Quality and Intelligibility
Jul 10, 2023Subjective tests are the gold standard for evaluating speech quality and intelligibility, but they are time-consuming and expensive. Thus, objective measures that align with human perceptions are crucial. This study evaluates the correlation between commonly used objective measures and subjective speech quality and intelligibility using a Chinese speech dataset. Moreover, new objective measures are proposed combining current objective measures using deep learning techniques to predict subjective quality and intelligibility. The proposed deep learning model reduces the amount of training data without significantly impacting prediction performance. We interpret the deep learning model to understand how objective measures reflect subjective quality and intelligibility. We also explore the impact of including subjective speech quality ratings on speech intelligibility prediction. Our findings offer valuable insights into the relationship between objective measures and human perceptions.
Partially Fake Audio Detection by Self-attention-based Fake Span Discovery
Feb 15, 2022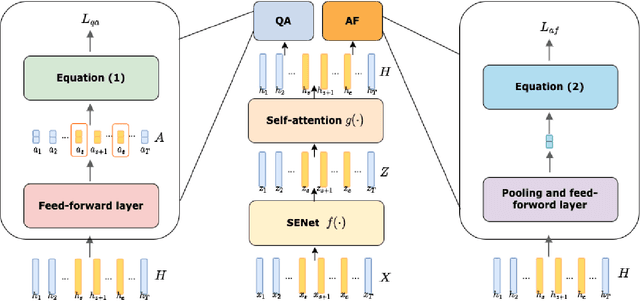
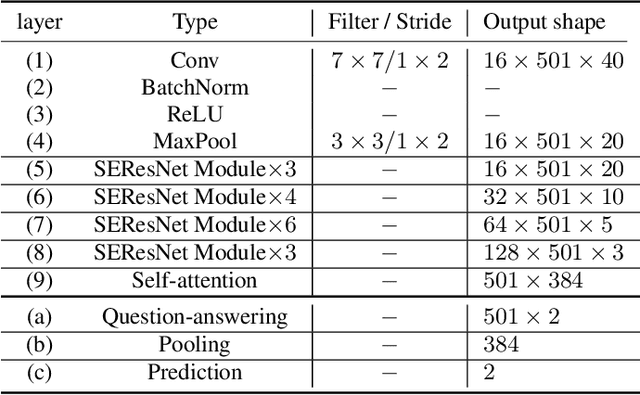

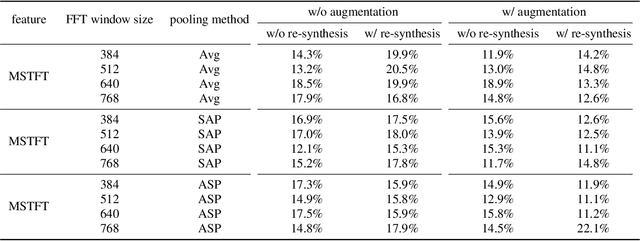
The past few years have witnessed the significant advances of speech synthesis and voice conversion technologies. However, such technologies can undermine the robustness of broadly implemented biometric identification models and can be harnessed by in-the-wild attackers for illegal uses. The ASVspoof challenge mainly focuses on synthesized audios by advanced speech synthesis and voice conversion models, and replay attacks. Recently, the first Audio Deep Synthesis Detection challenge (ADD 2022) extends the attack scenarios into more aspects. Also ADD 2022 is the first challenge to propose the partially fake audio detection task. Such brand new attacks are dangerous and how to tackle such attacks remains an open question. Thus, we propose a novel framework by introducing the question-answering (fake span discovery) strategy with the self-attention mechanism to detect partially fake audios. The proposed fake span detection module tasks the anti-spoofing model to predict the start and end positions of the fake clip within the partially fake audio, address the model's attention into discovering the fake spans rather than other shortcuts with less generalization, and finally equips the model with the discrimination capacity between real and partially fake audios. Our submission ranked second in the partially fake audio detection track of ADD 2022.
Toward Real-World Pathological Voice Detection
Dec 05, 2021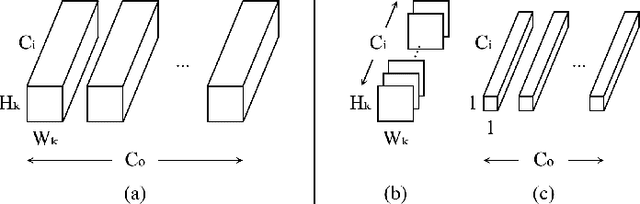
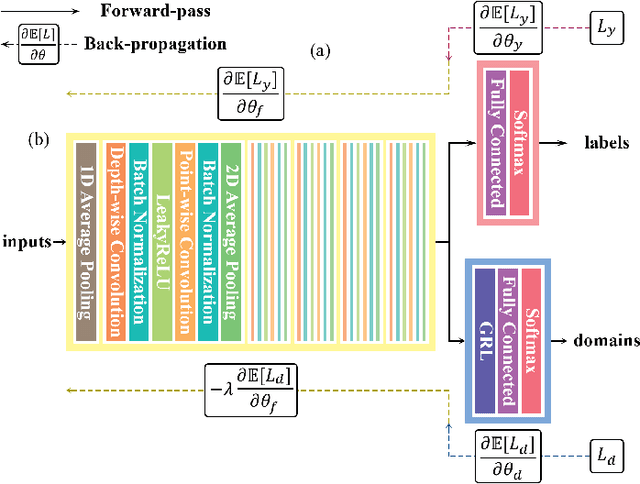
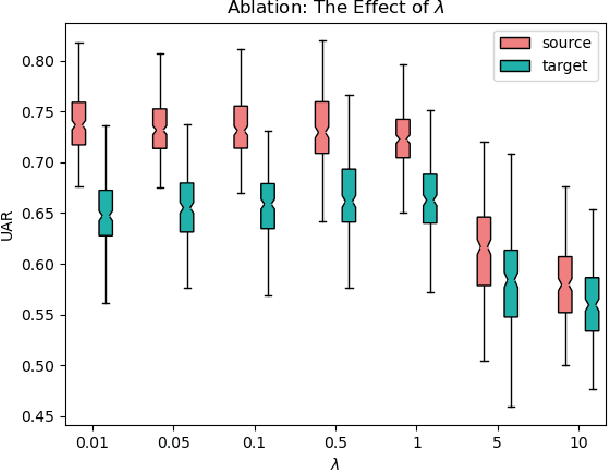
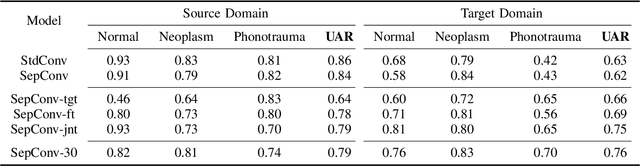
Voice disorders significantly undermine people's ability to speak in their daily lives. Without early diagnoses and treatments, these disorders may drastically deteriorate. Thus, automatic detection systems at home are desired for people inaccessible to disease assessments. However, more accurate systems usually require more cumbersome machine learning models, whereas the memory and computational resources of the systems at home are limited. Moreover, the performance of the systems may be weakened due to domain mismatch between clinic and real-world data. Therefore, we aimed to develop a compressed and domain-robust pathological voice detection system. Domain adversarial training was utilized to address domain mismatch by extracting domain-invariant features. In addition, factorized convolutional neural networks were exploited to compress the feature extractor model. The results showed that only 4% of degradation of unweighted average recall occurred in the target domain compared to the source domain, indicating that the domain mismatch was effectively eliminated. Furthermore, our system reduced both usages of memory and computation by over 73.9%. We concluded that this proposed system successfully resolved domain mismatch and may be applicable to embedded systems at home with limited resources.
Boosting Objective Scores of Speech Enhancement Model through MetricGAN Post-Processing
Jun 18, 2020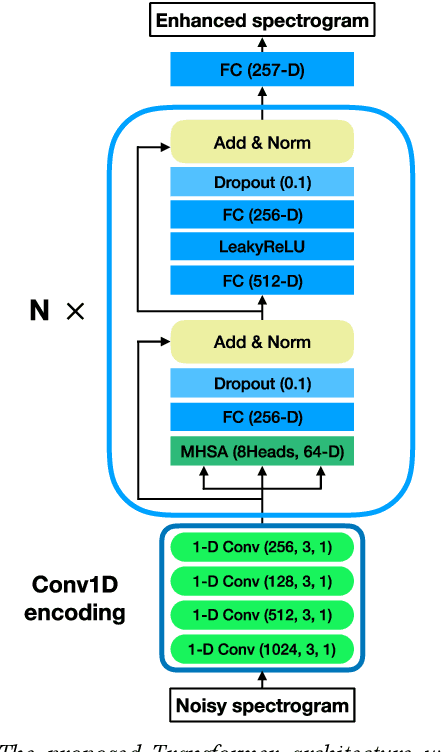
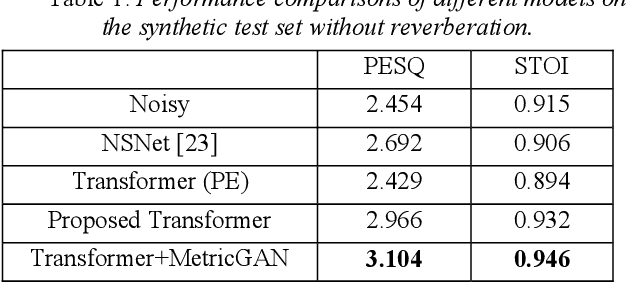
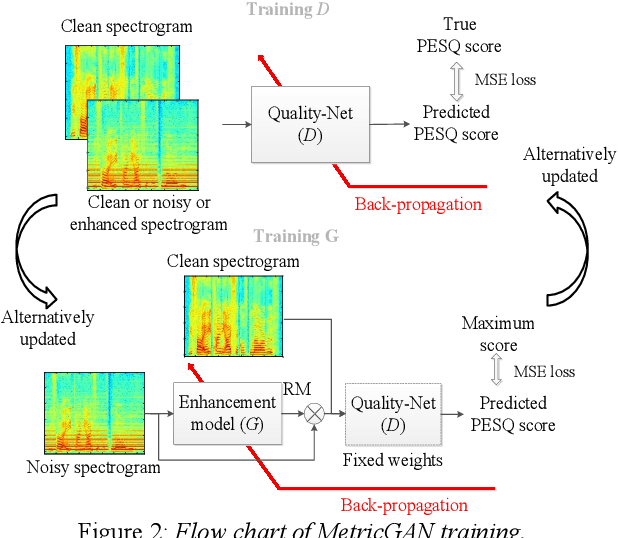

The Transformer architecture has shown its superior ability than recurrent neural networks on many different natural language processing applications. Therefore, this study applies a modified Transformer on the speech enhancement task. Specifically, the positional encoding may not be necessary and hence is replaced by convolutional layers. To further improve PESQ scores of enhanced speech, the L_1 pre-trained Transformer is fine-tuned by MetricGAN framework. The proposed MetricGAN can be treated as a general post-processing module to further boost interested objective scores. The experiments are conducted using the data sets provided by the organizer of the Deep Noise Suppression (DNS) challenge. Experimental results demonstrate that the proposed system outperforms the challenge baseline in both subjective and objective evaluation with a large margin.