 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaLTM: Adaptive Layer-wise Task Vector Merging for Categorical Speech Emotion Recognition with ASR Knowledge Integration
Mar 26, 2026Integrating Automatic Speech Recognition (ASR) into Speech Emotion Recognition (SER) enhances modeling by providing linguistic context. However, conventional feature fusion faces performance bottlenecks, and multi-task learning often suffers from optimization conflicts. While task vectors and model merging have addressed such conflicts in NLP and CV, their potential in speech tasks remains largely unexplored. In this work, we propose an Adaptive Layer-wise Task Vector Merging (AdaLTM) framework based on WavLM-Large. Instead of joint optimization, we extract task vectors from in-domain ASR and SER models fine-tuned on emotion datasets. These vectors are integrated into a frozen base model using layer-wise learnable coefficients. This strategy enables depth-aware balancing of linguistic and paralinguistic knowledge across transformer layers without gradient interference. Experiments on the MSP-Podcast demonstrate that the proposed approach effectively mitigates conflicts between ASR and SER.
How Contrastive Decoding Enhances Large Audio Language Models?
Mar 10, 2026While Contrastive Decoding (CD) has proven effective at enhancing Large Audio Language Models (LALMs), the underlying mechanisms driving its success and the comparative efficacy of different strategies remain unclear. This study systematically evaluates four distinct CD strategies across diverse LALM architectures. We identify Audio-Aware Decoding and Audio Contrastive Decoding as the most effective methods. However, their impact varies significantly by model. To explain this variability, we introduce a Transition Matrix framework to map error pattern shifts during inference. Our analysis demonstrates that CD reliably rectifies errors in which models falsely claim an absence of audio or resort to uncertainty-driven guessing. Conversely, it fails to correct flawed reasoning or confident misassertions. Ultimately, these findings provide a clear guideline for determining which LALM architectures are most suitable for CD enhancement based on their baseline error profiles.
Pseudo2Real: Task Arithmetic for Pseudo-Label Correction in Automatic Speech Recognition
Oct 09, 2025Robust ASR under domain shift is crucial because real-world systems encounter unseen accents and domains with limited labeled data. Although pseudo-labeling offers a practical workaround, it often introduces systematic, accent-specific errors that filtering fails to fix. We ask: How can we correct these recurring biases without target ground truth? We propose a simple parameter-space correction: in a source domain containing both real and pseudo-labeled data, two ASR models are fine-tuned from the same initialization, one on ground-truth labels and the other on pseudo-labels, and their weight difference forms a correction vector that captures pseudo-label biases. When applied to a pseudo-labeled target model, this vector enhances recognition, achieving up to a 35% relative Word Error Rate (WER) reduction on AfriSpeech-200 across ten African accents with the Whisper tiny model.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025
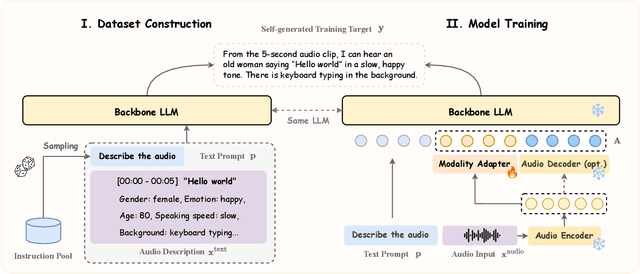


We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
An Exploration of Mamba for Speech Self-Supervised Models
Jun 14, 2025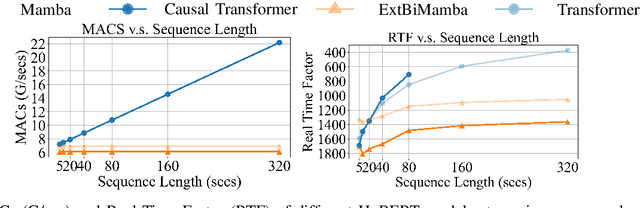
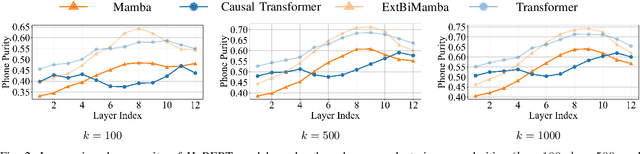
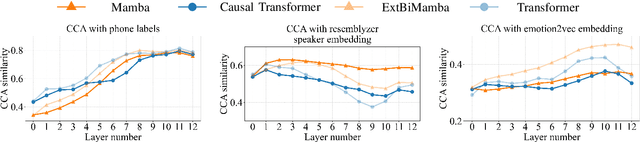
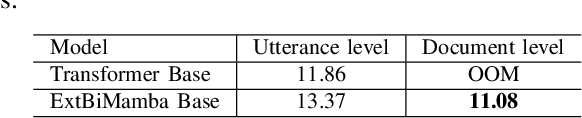
While Mamba has demonstrated strong performance in language modeling, its potential as a speech self-supervised (SSL) model remains underexplored, with prior studies limited to isolated tasks. To address this, we explore Mamba-based HuBERT models as alternatives to Transformer-based SSL architectures. Leveraging the linear-time Selective State Space, these models enable fine-tuning on long-context ASR with significantly lower compute. Moreover, they show superior performance when fine-tuned for streaming ASR. Beyond fine-tuning, these models show competitive performance on SUPERB probing benchmarks, particularly in causal settings. Our analysis shows that they yield higher-quality quantized representations and capture speaker-related features more distinctly than Transformer-based models. These findings highlight Mamba-based SSL as a promising and complementary direction for long-sequence modeling, real-time speech modeling, and speech unit extraction.
Speech-FT: A Fine-tuning Strategy for Enhancing Speech Representation Models Without Compromising Generalization Ability
Feb 18, 2025



Speech representation models are highly effective at extracting general features for various tasks. While fine-tuning can enhance these representations for specific applications, it often compromises their generalization ability. To address this challenge, we propose Speech-FT, a fine-tuning strategy for speech representation models that leverages model merging to preserve generalization ability while still benefiting from fine-tuning. Speech-FT is effective across different fine-tuning scenarios and is compatible with various types of speech representation models, providing a versatile solution. Speech-FT offers an efficient and practical approach to further improving general speech representations after pre-training.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Property Neurons in Self-Supervised Speech Transformers
Sep 07, 2024



There have been many studies on analyzing self-supervised speech Transformers, in particular, with layer-wise analysis. It is, however, desirable to have an approach that can pinpoint exactly a subset of neurons that is responsible for a particular property of speech, being amenable to model pruning and model editing. In this work, we identify a set of property neurons in the feedforward layers of Transformers to study how speech-related properties, such as phones, gender, and pitch, are stored. When removing neurons of a particular property (a simple form of model editing), the respective downstream performance significantly degrades, showing the importance of the property neurons. We apply this approach to pruning the feedforward layers in Transformers, where most of the model parameters are. We show that protecting property neurons during pruning is significantly more effective than norm-based pruning.
Listen and Speak Fairly: A Study on Semantic Gender Bias in Speech Integrated Large Language Models
Jul 09, 2024Speech Integrated Large Language Models (SILLMs) combine large language models with speech perception to perform diverse tasks, such as emotion recognition to speaker verification, demonstrating universal audio understanding capability. However, these models may amplify biases present in training data, potentially leading to biased access to information for marginalized groups. This work introduces a curated spoken bias evaluation toolkit and corresponding dataset. We evaluate gender bias in SILLMs across four semantic-related tasks: speech-to-text translation (STT), spoken coreference resolution (SCR), spoken sentence continuation (SSC), and spoken question answering (SQA). Our analysis reveals that bias levels are language-dependent and vary with different evaluation methods. Our findings emphasize the necessity of employing multiple approaches to comprehensively assess biases in SILLMs, providing insights for developing fairer SILLM systems.