 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling LLM Agent Reviewer Dynamics in Elo-Ranked Review System
Jan 13, 2026In this work, we explore the Large Language Model (LLM) agent reviewer dynamics in an Elo-ranked review system using real-world conference paper submissions. Multiple LLM agent reviewers with different personas are engage in multi round review interactions moderated by an Area Chair. We compare a baseline setting with conditions that incorporate Elo ratings and reviewer memory. Our simulation results showcase several interesting findings, including how incorporating Elo improves Area Chair decision accuracy, as well as reviewers' adaptive review strategy that exploits our Elo system without improving review effort. Our code is available at https://github.com/hsiangwei0903/EloReview.
Reasoning Matters for 3D Visual Grounding
Jan 13, 2026The recent development of Large Language Models (LLMs) with strong reasoning ability has driven research in various domains such as mathematics, coding, and scientific discovery. Meanwhile, 3D visual grounding, as a fundamental task in 3D understanding, still remains challenging due to the limited reasoning ability of recent 3D visual grounding models. Most of the current methods incorporate a text encoder and visual feature encoder to generate cross-modal fuse features and predict the referring object. These models often require supervised training on extensive 3D annotation data. On the other hand, recent research also focus on scaling synthetic data to train stronger 3D visual grounding LLM, however, the performance gain remains limited and non-proportional to the data collection cost. In this work, we propose a 3D visual grounding data pipeline, which is capable of automatically synthesizing 3D visual grounding data along with corresponding reasoning process. Additionally, we leverage the generated data for LLM fine-tuning and introduce Reason3DVG-8B, a strong 3D visual grounding LLM that outperforms previous LLM-based method 3D-GRAND using only 1.6% of their training data, demonstrating the effectiveness of our data and the importance of reasoning in 3D visual grounding.
TEMPURA: Temporal Event Masked Prediction and Understanding for Reasoning in Action
May 02, 2025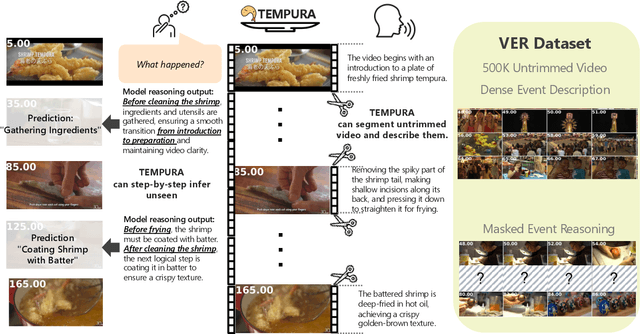

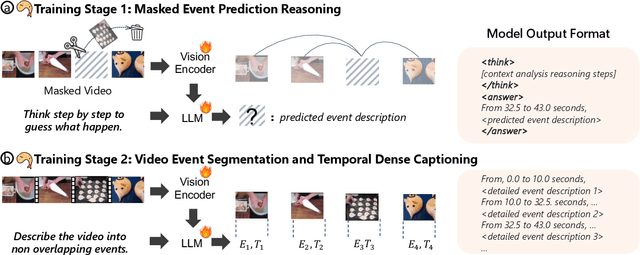
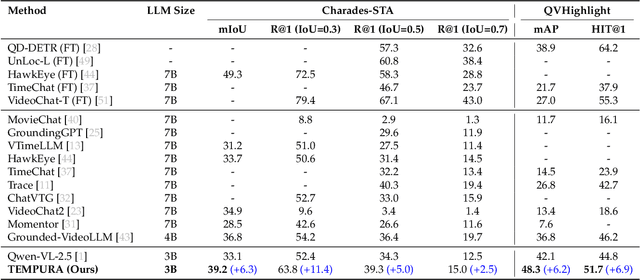
Understanding causal event relationships and achieving fine-grained temporal grounding in videos remain challenging for vision-language models. Existing methods either compress video tokens to reduce temporal resolution, or treat videos as unsegmented streams, which obscures fine-grained event boundaries and limits the modeling of causal dependencies. We propose TEMPURA (Temporal Event Masked Prediction and Understanding for Reasoning in Action), a two-stage training framework that enhances video temporal understanding. TEMPURA first applies masked event prediction reasoning to reconstruct missing events and generate step-by-step causal explanations from dense event annotations, drawing inspiration from effective infilling techniques. TEMPURA then learns to perform video segmentation and dense captioning to decompose videos into non-overlapping events with detailed, timestamp-aligned descriptions. We train TEMPURA on VER, a large-scale dataset curated by us that comprises 1M training instances and 500K videos with temporally aligned event descriptions and structured reasoning steps. Experiments on temporal grounding and highlight detection benchmarks demonstrate that TEMPURA outperforms strong baseline models, confirming that integrating causal reasoning with fine-grained temporal segmentation leads to improved video understanding.
InstructionCP: A fast approach to transfer Large Language Models into target language
May 30, 2024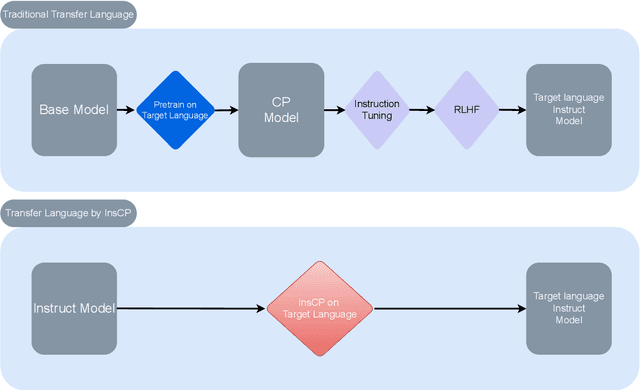
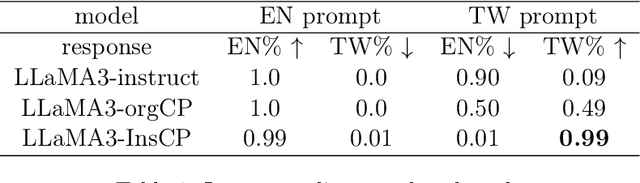
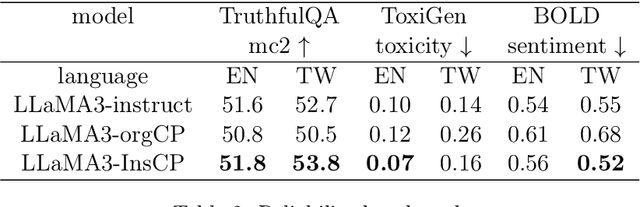

The rapid development of large language models (LLMs) in recent years has largely focused on English, resulting in models that respond exclusively in English. To adapt these models to other languages, continual pre-training (CP) is often employed, followed by supervised fine-tuning (SFT) to maintain conversational abilities. However, CP and SFT can reduce a model's ability to filter harmful content. We propose Instruction Continual Pre-training (InsCP), which integrates instruction tags into the CP process to prevent loss of conversational proficiency while acquiring new languages. Our experiments demonstrate that InsCP retains conversational and Reinforcement Learning from Human Feedback (RLHF) abilities. Empirical evaluations on language alignment, reliability, and knowledge benchmarks confirm the efficacy of InsCP. Notably, this approach requires only 0.1 billion tokens of high-quality instruction-following data, thereby reducing resource consumption.
Chat Vector: A Simple Approach to Equip LLMs With New Language Chat Capabilities
Oct 07, 2023
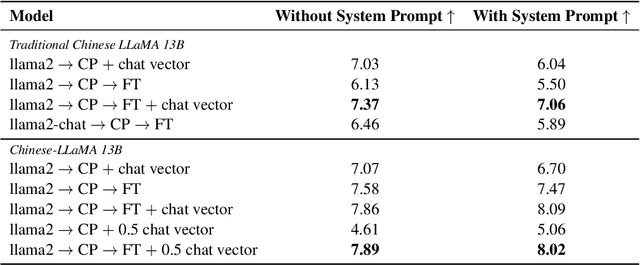

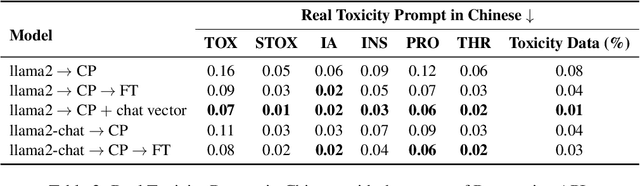
With the advancements in conversational AI, such as ChatGPT, this paper focuses on exploring developing Large Language Models (LLMs) for non-English languages, especially emphasizing alignment with human preferences. We introduce a computationally efficient method, leveraging chat vector, to synergize pre-existing knowledge and behaviors in LLMs, restructuring the conventional training paradigm from continual pre-train -> SFT -> RLHF to continual pre-train + chat vector. Our empirical studies, primarily focused on Traditional Chinese, employ LLaMA2 as the base model and acquire the chat vector by subtracting the pre-trained weights, LLaMA2, from the weights of LLaMA2-chat. Evaluating from three distinct facets, which are toxicity, ability of instruction following, and multi-turn dialogue demonstrates the chat vector's superior efficacy in chatting. To confirm the adaptability of our approach, we extend our experiments to include models pre-trained in both Korean and Simplified Chinese, illustrating the versatility of our methodology. Overall, we present a significant solution in aligning LLMs with human preferences efficiently across various languages, accomplished by the chat vector.
Compressing Transformer-based self-supervised models for speech processing
Nov 17, 2022Despite the success of Transformers in self-supervised learning with applications to various downstream tasks, the computational cost of training and inference remains a major challenge for applying these models to a wide spectrum of devices. Several isolated attempts have been made to compress Transformers, prior to applying them to downstream tasks. In this work, we aim to provide context for the isolated results, studying several commonly used compression techniques, including weight pruning, head pruning, low-rank approximation, and knowledge distillation. We report wall-clock time, the number of parameters, and the number of multiply-accumulate operations for these techniques, charting the landscape of compressing Transformer-based self-supervised models.