 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlex4DHuman: Flexible Multi-view Video Diffusion for 4D Human Reconstruction
Jun 11, 2026We present Flex4DHuman, a multi-view video diffusion model that transforms a monocular or sparse multi-view video of a dynamic subject into synchronized dense multi-view videos using only relative camera-pose conditioning. Unlike prior human-centric methods that rely on skeletons, depth maps, normals, or rendered target-view geometry, Flex4DHuman requires no explicit geometry priors and instead conditions generation through relative camera-pose positional encoding. The generated videos can be directly ingested by downstream reconstruction pipelines to create dynamic 4D Gaussian splats. Built on the Wan 2.1 1.3B text-to-video model, Flex4DHuman preserves the backbone architecture and encodes camera and view information through a five-axis positional encoding that extends spatio-temporal RoPE with view indices and continuous SE(3) relative camera geometry. A three-stage curriculum progressively trains the model for pose following, flexible reference-to-target view generation, and temporal rollout. To support temporal rollout, we train with clean historical target-view tokens. We also add multi-view captions to enable test-time text control. Combined with an off-the-shelf 4D Gaussian Splatting stage, our framework lifts monocular static-camera videos into dynamic 4D Gaussian splats. Experiments on DNA-Rendering and ActorsHQ show that Flex4DHuman surpasses prior state-of-the-art methods, while the same formulation generalizes to animal categories after mixed human-animal training. These capabilities make Flex4DHuman a practical step toward scalable 4D content creation from casual monocular videos for simulation, gaming, AR/VR, and video re-shooting.
World Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
Jun 11, 2026Image-to-3D methods often trade off faithfulness and completeness: depth estimators are anchored to input pixels but stop at the visible surface, while image-to-3D models generate complete shapes that are often misaligned with the input. We introduce World Tracing, a generative pixel-aligned geometry representation that predicts 3D points aligned with observed pixels while completing geometry beyond the visible surface. For each input pixel, World Tracing predicts an ordered stack of camera-space 3D points, where the first layer represents the visible surface and subsequent layers represent front-to-back intersections with occluded surfaces. We instantiate this representation with a world-tracing diffusion transformer, WT-DiT, which treats multiple geometry layers as separate denoising tokens coupled through factorized and global attention. WT-DiT is trained with pixel-space flow matching and a mixed noise schedule that balances visible-surface reconstruction with occluded-geometry generation. World Tracing achieves strong performance on visible-surface reconstruction and complete geometry generation across object, scene, and dynamic benchmarks, outperforming both depth predictors and image-to-3D generators. It also preserves 2D-to-3D correspondence, enabling text-driven 3D scene editing, geometry-conditioned novel-view video synthesis, and training-free integration with textured-mesh generators.
Reasoning Matters for 3D Visual Grounding
Jan 13, 2026The recent development of Large Language Models (LLMs) with strong reasoning ability has driven research in various domains such as mathematics, coding, and scientific discovery. Meanwhile, 3D visual grounding, as a fundamental task in 3D understanding, still remains challenging due to the limited reasoning ability of recent 3D visual grounding models. Most of the current methods incorporate a text encoder and visual feature encoder to generate cross-modal fuse features and predict the referring object. These models often require supervised training on extensive 3D annotation data. On the other hand, recent research also focus on scaling synthetic data to train stronger 3D visual grounding LLM, however, the performance gain remains limited and non-proportional to the data collection cost. In this work, we propose a 3D visual grounding data pipeline, which is capable of automatically synthesizing 3D visual grounding data along with corresponding reasoning process. Additionally, we leverage the generated data for LLM fine-tuning and introduce Reason3DVG-8B, a strong 3D visual grounding LLM that outperforms previous LLM-based method 3D-GRAND using only 1.6% of their training data, demonstrating the effectiveness of our data and the importance of reasoning in 3D visual grounding.
TEMPURA: Temporal Event Masked Prediction and Understanding for Reasoning in Action
May 02, 2025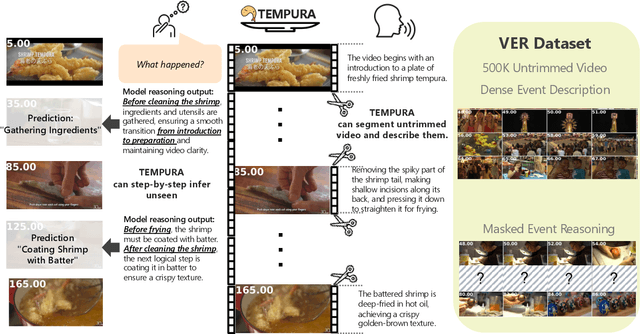

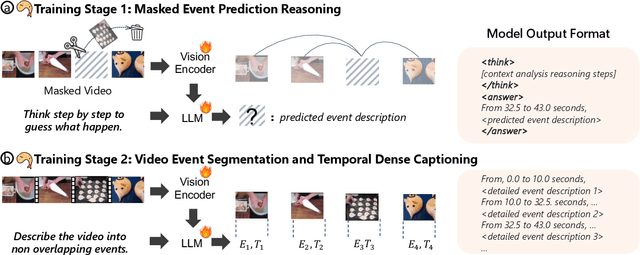
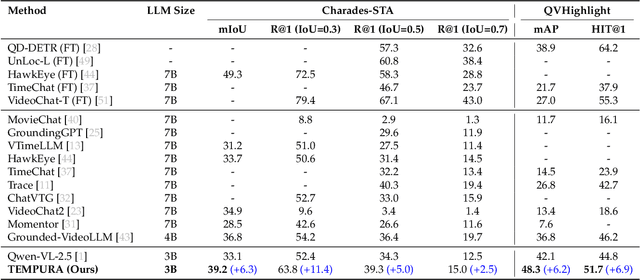
Understanding causal event relationships and achieving fine-grained temporal grounding in videos remain challenging for vision-language models. Existing methods either compress video tokens to reduce temporal resolution, or treat videos as unsegmented streams, which obscures fine-grained event boundaries and limits the modeling of causal dependencies. We propose TEMPURA (Temporal Event Masked Prediction and Understanding for Reasoning in Action), a two-stage training framework that enhances video temporal understanding. TEMPURA first applies masked event prediction reasoning to reconstruct missing events and generate step-by-step causal explanations from dense event annotations, drawing inspiration from effective infilling techniques. TEMPURA then learns to perform video segmentation and dense captioning to decompose videos into non-overlapping events with detailed, timestamp-aligned descriptions. We train TEMPURA on VER, a large-scale dataset curated by us that comprises 1M training instances and 500K videos with temporally aligned event descriptions and structured reasoning steps. Experiments on temporal grounding and highlight detection benchmarks demonstrate that TEMPURA outperforms strong baseline models, confirming that integrating causal reasoning with fine-grained temporal segmentation leads to improved video understanding.
Boosting Online 3D Multi-Object Tracking through Camera-Radar Cross Check
Jul 18, 2024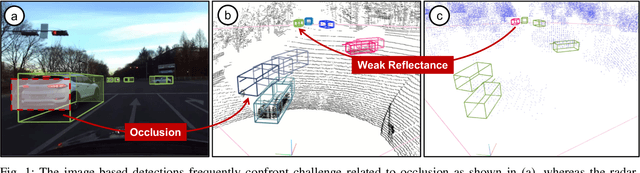
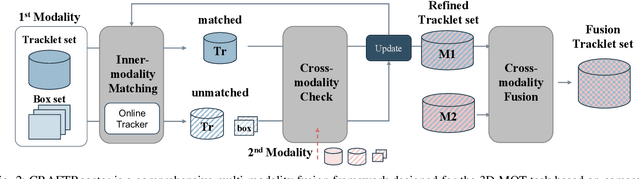
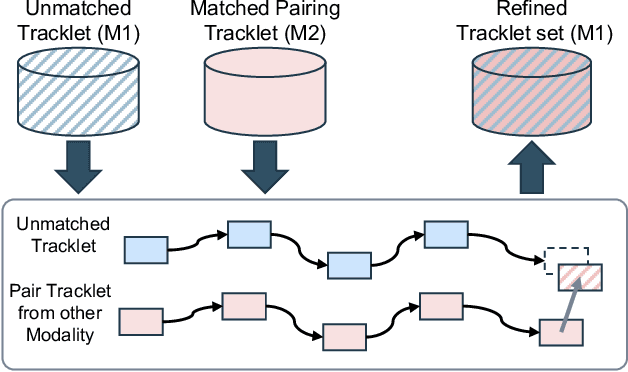
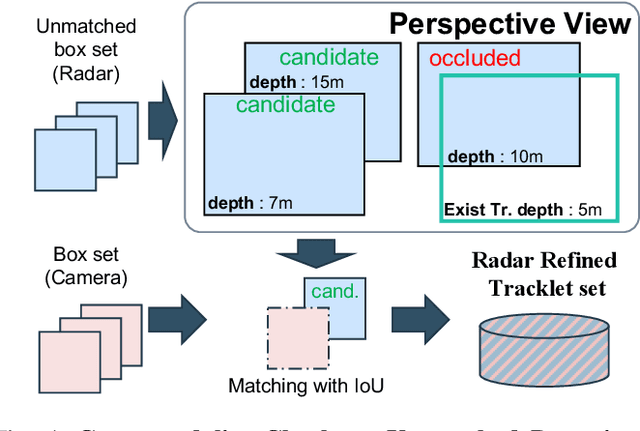
In the domain of autonomous driving, the integration of multi-modal perception techniques based on data from diverse sensors has demonstrated substantial progress. Effectively surpassing the capabilities of state-of-the-art single-modality detectors through sensor fusion remains an active challenge. This work leverages the respective advantages of cameras in perspective view and radars in Bird's Eye View (BEV) to greatly enhance overall detection and tracking performance. Our approach, Camera-Radar Associated Fusion Tracking Booster (CRAFTBooster), represents a pioneering effort to enhance radar-camera fusion in the tracking stage, contributing to improved 3D MOT accuracy. The superior experimental results on the K-Radaar dataset, which exhibit 5-6% on IDF1 tracking performance gain, validate the potential of effective sensor fusion in advancing autonomous driving.
RT-Pose: A 4D Radar Tensor-based 3D Human Pose Estimation and Localization Benchmark
Jul 18, 2024


Traditional methods for human localization and pose estimation (HPE), which mainly rely on RGB images as an input modality, confront substantial limitations in real-world applications due to privacy concerns. In contrast, radar-based HPE methods emerge as a promising alternative, characterized by distinctive attributes such as through-wall recognition and privacy-preserving, rendering the method more conducive to practical deployments. This paper presents a Radar Tensor-based human pose (RT-Pose) dataset and an open-source benchmarking framework. The RT-Pose dataset comprises 4D radar tensors, LiDAR point clouds, and RGB images, and is collected for a total of 72k frames across 240 sequences with six different complexity-level actions. The 4D radar tensor provides raw spatio-temporal information, differentiating it from other radar point cloud-based datasets. We develop an annotation process using RGB images and LiDAR point clouds to accurately label 3D human skeletons. In addition, we propose HRRadarPose, the first single-stage architecture that extracts the high-resolution representation of 4D radar tensors in 3D space to aid human keypoint estimation. HRRadarPose outperforms previous radar-based HPE work on the RT-Pose benchmark. The overall HRRadarPose performance on the RT-Pose dataset, as reflected in a mean per joint position error (MPJPE) of 9.91cm, indicates the persistent challenges in achieving accurate HPE in complex real-world scenarios. RT-Pose is available at https://huggingface.co/datasets/uwipl/RT-Pose.
MonoTAKD: Teaching Assistant Knowledge Distillation for Monocular 3D Object Detection
Apr 07, 2024



Monocular 3D object detection (Mono3D) is an indispensable research topic in autonomous driving, thanks to the cost-effective monocular camera sensors and its wide range of applications. Since the image perspective has depth ambiguity, the challenges of Mono3D lie in understanding 3D scene geometry and reconstructing 3D object information from a single image. Previous methods attempted to transfer 3D information directly from the LiDAR-based teacher to the camera-based student. However, a considerable gap in feature representation makes direct cross-modal distillation inefficient, resulting in a significant performance deterioration between the LiDAR-based teacher and the camera-based student. To address this issue, we propose the Teaching Assistant Knowledge Distillation (MonoTAKD) to break down the learning objective by integrating intra-modal distillation with cross-modal residual distillation. In particular, we employ a strong camera-based teaching assistant model to distill powerful visual knowledge effectively through intra-modal distillation. Subsequently, we introduce the cross-modal residual distillation to transfer the 3D spatial cues. By acquiring both visual knowledge and 3D spatial cues, the predictions of our approach are rigorously evaluated on the KITTI 3D object detection benchmark and achieve state-of-the-art performance in Mono3D.
Vision meets mmWave Radar: 3D Object Perception Benchmark for Autonomous Driving
Nov 17, 2023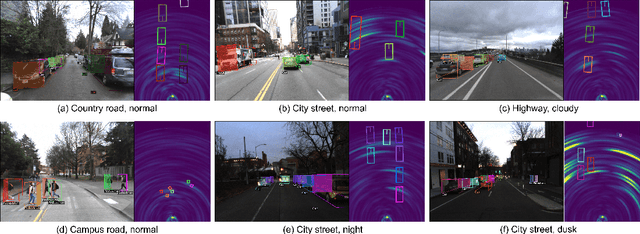
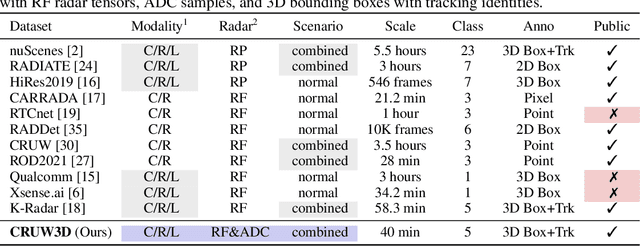

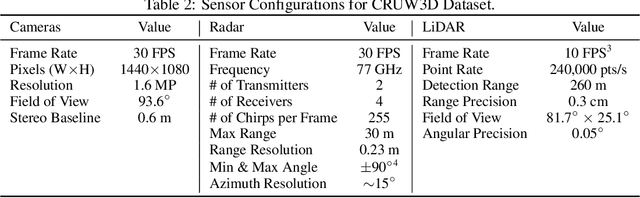
Sensor fusion is crucial for an accurate and robust perception system on autonomous vehicles. Most existing datasets and perception solutions focus on fusing cameras and LiDAR. However, the collaboration between camera and radar is significantly under-exploited. The incorporation of rich semantic information from the camera, and reliable 3D information from the radar can potentially achieve an efficient, cheap, and portable solution for 3D object perception tasks. It can also be robust to different lighting or all-weather driving scenarios due to the capability of mmWave radars. In this paper, we introduce the CRUW3D dataset, including 66K synchronized and well-calibrated camera, radar, and LiDAR frames in various driving scenarios. Unlike other large-scale autonomous driving datasets, our radar data is in the format of radio frequency (RF) tensors that contain not only 3D location information but also spatio-temporal semantic information. This kind of radar format can enable machine learning models to generate more reliable object perception results after interacting and fusing the information or features between the camera and radar.
CenterRadarNet: Joint 3D Object Detection and Tracking Framework using 4D FMCW Radar
Nov 04, 2023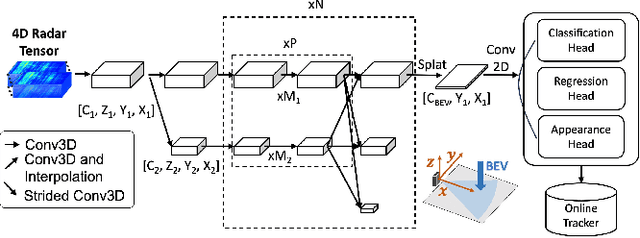
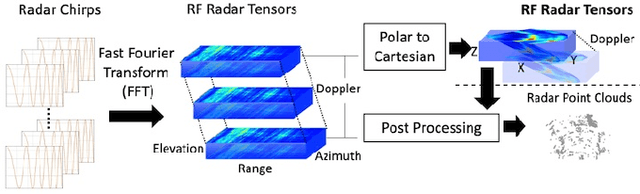
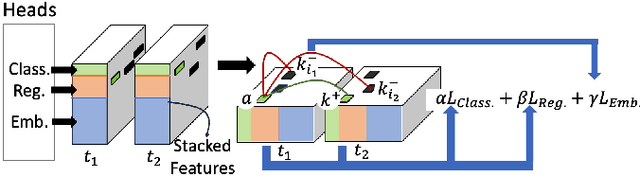
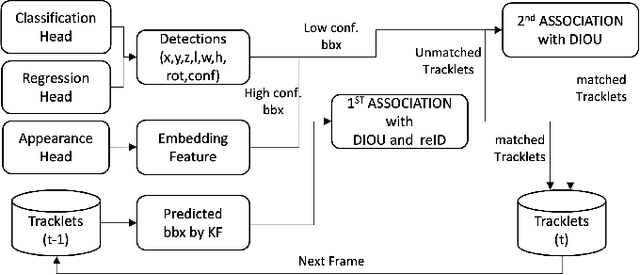
Robust perception is a vital component for ensuring safe autonomous and assisted driving. Automotive radar (77 to 81 GHz), which offers weather-resilient sensing, provides a complementary capability to the vision- or LiDAR-based autonomous driving systems. Raw radio-frequency (RF) radar tensors contain rich spatiotemporal semantics besides 3D location information. The majority of previous methods take in 3D (Doppler-range-azimuth) RF radar tensors, allowing prediction of an object's location, heading angle, and size in bird's-eye-view (BEV). However, they lack the ability to at the same time infer objects' size, orientation, and identity in the 3D space. To overcome this limitation, we propose an efficient joint architecture called CenterRadarNet, designed to facilitate high-resolution representation learning from 4D (Doppler-range-azimuth-elevation) radar data for 3D object detection and re-identification (re-ID) tasks. As a single-stage 3D object detector, CenterRadarNet directly infers the BEV object distribution confidence maps, corresponding 3D bounding box attributes, and appearance embedding for each pixel. Moreover, we build an online tracker utilizing the learned appearance embedding for re-ID. CenterRadarNet achieves the state-of-the-art result on the K-Radar 3D object detection benchmark. In addition, we present the first 3D object-tracking result using radar on the K-Radar dataset V2. In diverse driving scenarios, CenterRadarNet shows consistent, robust performance, emphasizing its wide applicability.