 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision meets mmWave Radar: 3D Object Perception Benchmark for Autonomous Driving
Nov 17, 2023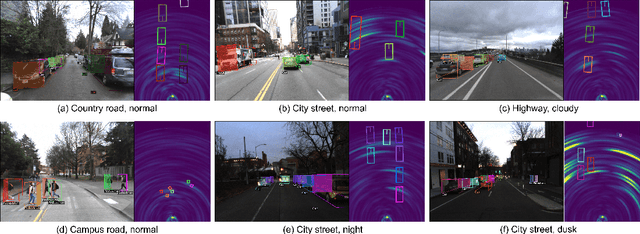
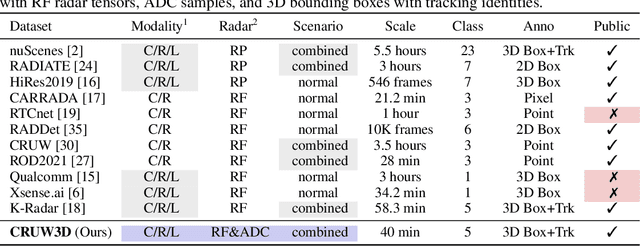

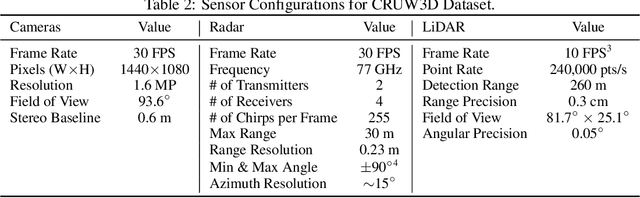
Sensor fusion is crucial for an accurate and robust perception system on autonomous vehicles. Most existing datasets and perception solutions focus on fusing cameras and LiDAR. However, the collaboration between camera and radar is significantly under-exploited. The incorporation of rich semantic information from the camera, and reliable 3D information from the radar can potentially achieve an efficient, cheap, and portable solution for 3D object perception tasks. It can also be robust to different lighting or all-weather driving scenarios due to the capability of mmWave radars. In this paper, we introduce the CRUW3D dataset, including 66K synchronized and well-calibrated camera, radar, and LiDAR frames in various driving scenarios. Unlike other large-scale autonomous driving datasets, our radar data is in the format of radio frequency (RF) tensors that contain not only 3D location information but also spatio-temporal semantic information. This kind of radar format can enable machine learning models to generate more reliable object perception results after interacting and fusing the information or features between the camera and radar.
Multi-Radar Inertial Odometry for 3D State Estimation using mmWave Imaging Radar
Nov 15, 2023State estimation is a crucial component for the successful implementation of robotic systems, relying on sensors such as cameras, LiDAR, and IMUs. However, in real-world scenarios, the performance of these sensors is degraded by challenging environments, e.g. adverse weather conditions and low-light scenarios. The emerging 4D imaging radar technology is capable of providing robust perception in adverse conditions. Despite its potential, challenges remain for indoor settings where noisy radar data does not present clear geometric features. Moreover, disparities in radar data resolution and field of view (FOV) can lead to inaccurate measurements. While prior research has explored radar-inertial odometry based on Doppler velocity information, challenges remain for the estimation of 3D motion because of the discrepancy in the FOV and resolution of the radar sensor. In this paper, we address Doppler velocity measurement uncertainties. We present a method to optimize body frame velocity while managing Doppler velocity uncertainty. Based on our observations, we propose a dual imaging radar configuration to mitigate the challenge of discrepancy in radar data. To attain high-precision 3D state estimation, we introduce a strategy that seamlessly integrates radar data with a consumer-grade IMU sensor using fixed-lag smoothing optimization. Finally, we evaluate our approach using real-world 3D motion data.
Cross-Modal Contrastive Learning of Representations for Navigation using Lightweight, Low-Cost Millimeter Wave Radar for Adverse Environmental Conditions
Jan 10, 2021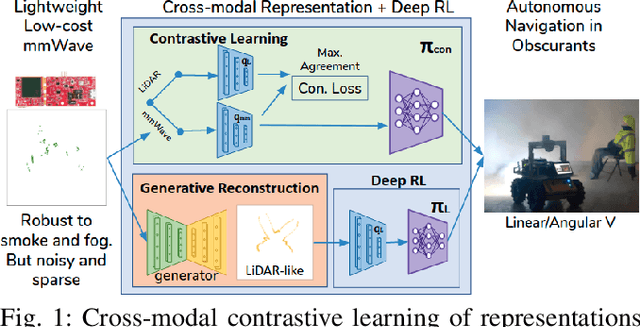
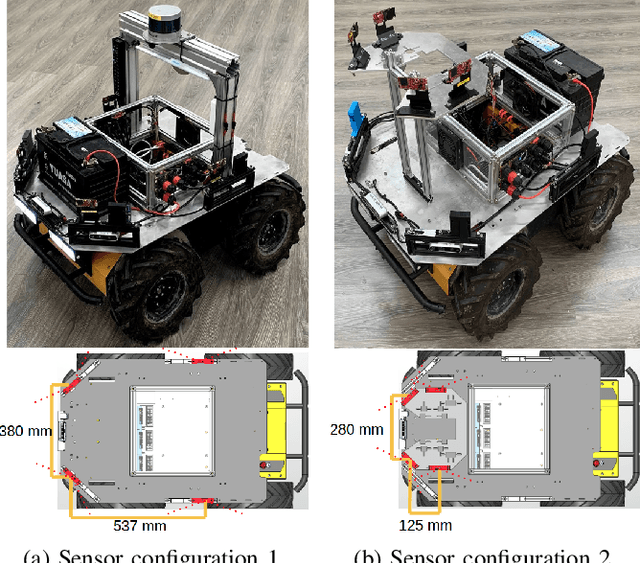
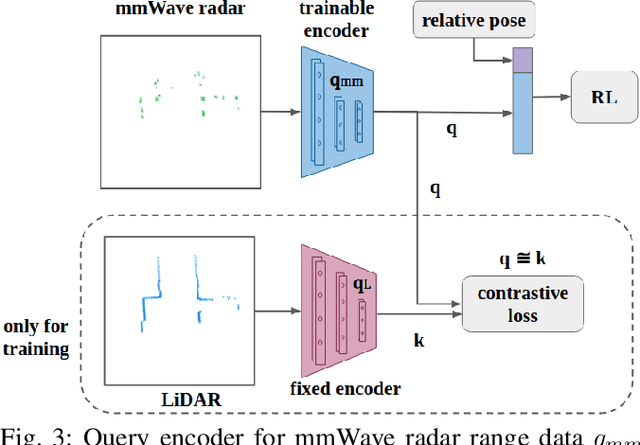
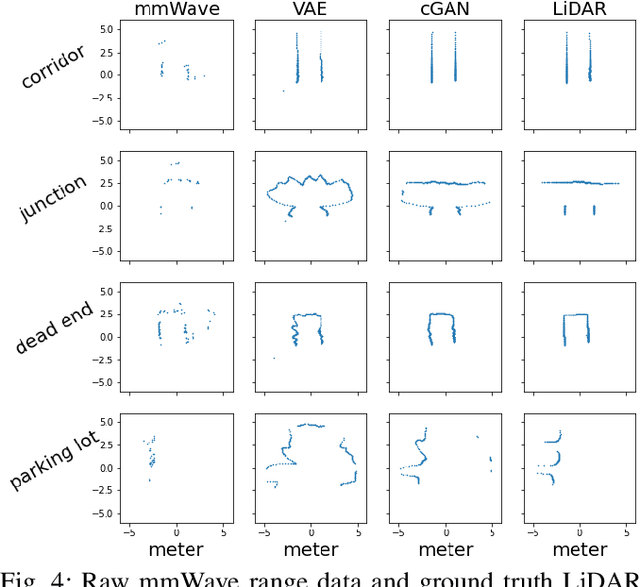
Deep reinforcement learning (RL), where the agent learns from mistakes, has been successfully applied to a variety of tasks. With the aim of learning collision-free policies for unmanned vehicles, deep RL has been used for training with various types of data, such as colored images, depth images, and LiDAR point clouds, without the use of classic map--localize--plan approaches. However, existing methods are limited by their reliance on cameras and LiDAR devices, which have degraded sensing under adverse environmental conditions (e.g., smoky environments). In response, we propose the use of single-chip millimeter-wave (mmWave) radar, which is lightweight and inexpensive, for learning-based autonomous navigation. However, because mmWave radar signals are often noisy and sparse, we propose a cross-modal contrastive learning for representation (CM-CLR) method that maximizes the agreement between mmWave radar data and LiDAR data in the training stage. We evaluated our method in real-world robot compared with 1) a method with two separate networks using cross-modal generative reconstruction and an RL policy and 2) a baseline RL policy without cross-modal representation. Our proposed end-to-end deep RL policy with contrastive learning successfully navigated the robot through smoke-filled maze environments and achieved better performance compared with generative reconstruction methods, in which noisy artifact walls or obstacles were produced. All pretrained models and hardware settings are open access for reproducing this study and can be obtained at https://arg-nctu.github.io/projects/deeprl-mmWave.html
Team NCTU: Toward AI-Driving for Autonomous Surface Vehicles -- From Duckietown to RobotX
Oct 31, 2019



Robotic software and hardware systems of autonomous surface vehicles have been developed in transportation, military, and ocean researches for decades. Previous efforts in RobotX Challenges 2014 and 2016 facilitates the developments for important tasks such as obstacle avoidance and docking. Team NCTU is motivated by the AI Driving Olympics (AI-DO) developed by the Duckietown community, and adopts the principles to RobotX challenge. With the containerization (Docker) and uniformed AI agent (with observations and actions), we could better 1) integrate solutions developed in different middlewares (ROS and MOOS), 2) develop essential functionalities of from simulation (Gazebo) to real robots (either miniaturized or full-sized WAM-V), and 3) compare different approaches either from classic model-based or learning-based. Finally, we setup an outdoor on-surface platform with localization services for evaluation. Some of the preliminary results will be presented for the Team NCTU participations of the RobotX competition in Hawaii in 2018.
Duckiefloat: a Collision-Tolerant Resource-Constrained Blimp for Long-Term Autonomy in Subterranean Environments
Oct 31, 2019
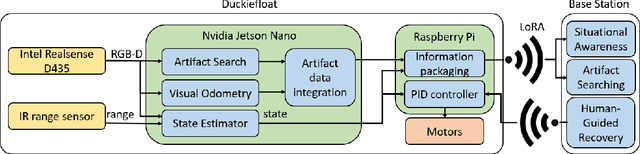
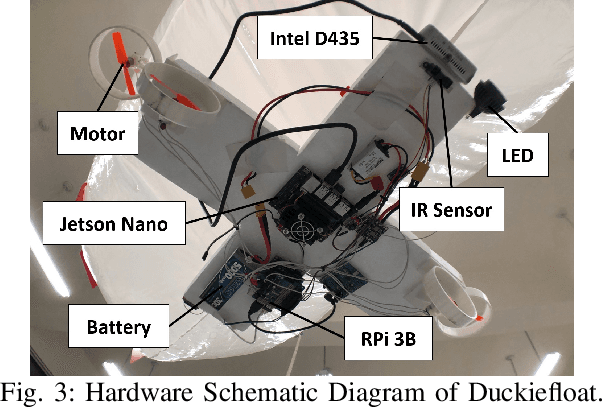

There are several challenges for search and rescue robots: mobility, perception, autonomy, and communication. Inspired by the DARPA Subterranean (SubT) Challenge, we propose an autonomous blimp robot, which has the advantages of low power consumption and collision-tolerance compared to other aerial vehicles like drones. This is important for search and rescue tasks that usually last for one or more hours. However, the underground constrained passages limit the size of blimp envelope and its payload, making the proposed system resource-constrained. Therefore, a careful design consideration is needed to build a blimp system with on-board artifact search and SLAM. In order to reach long-term operation, a failure-aware algorithm with minimal communication to human supervisor to have situational awareness and send control signals to the blimp when needed.