 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Contrastive Learning of Representations for Navigation using Lightweight, Low-Cost Millimeter Wave Radar for Adverse Environmental Conditions
Paper and Code
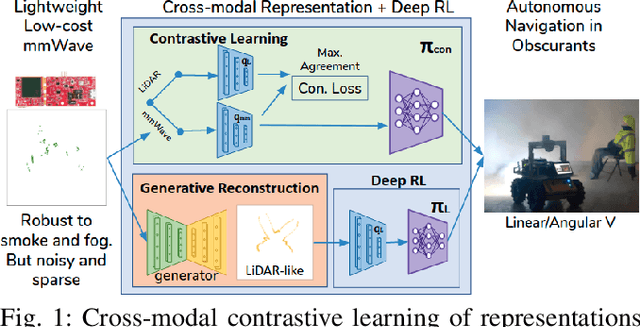
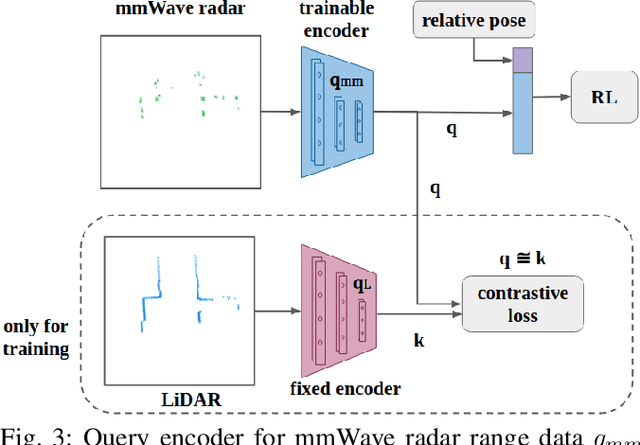
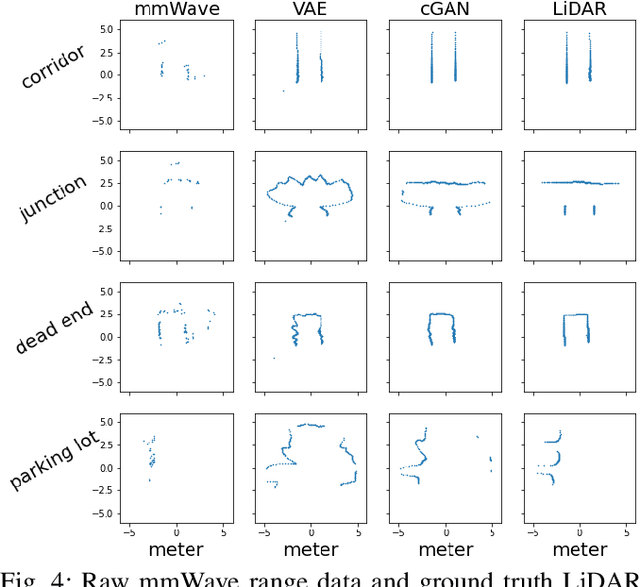
Deep reinforcement learning (RL), where the agent learns from mistakes, has been successfully applied to a variety of tasks. With the aim of learning collision-free policies for unmanned vehicles, deep RL has been used for training with various types of data, such as colored images, depth images, and LiDAR point clouds, without the use of classic map--localize--plan approaches. However, existing methods are limited by their reliance on cameras and LiDAR devices, which have degraded sensing under adverse environmental conditions (e.g., smoky environments). In response, we propose the use of single-chip millimeter-wave (mmWave) radar, which is lightweight and inexpensive, for learning-based autonomous navigation. However, because mmWave radar signals are often noisy and sparse, we propose a cross-modal contrastive learning for representation (CM-CLR) method that maximizes the agreement between mmWave radar data and LiDAR data in the training stage. We evaluated our method in real-world robot compared with 1) a method with two separate networks using cross-modal generative reconstruction and an RL policy and 2) a baseline RL policy without cross-modal representation. Our proposed end-to-end deep RL policy with contrastive learning successfully navigated the robot through smoke-filled maze environments and achieved better performance compared with generative reconstruction methods, in which noisy artifact walls or obstacles were produced. All pretrained models and hardware settings are open access for reproducing this study and can be obtained at https://arg-nctu.github.io/projects/deeprl-mmWave.html