 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Physical-Virtual Interaction in AR Gaming by Tracking Identical Real Objects
Feb 24, 2025



Augmented reality (AR) games, particularly those designed for headsets, have become increasingly prevalent with advancements in both hardware and software. However, the majority of AR games still rely on pre-scanned or static scenes, and interaction mechanisms are often limited to controllers or hand-tracking. Additionally, the presence of identical objects in AR games poses challenges for conventional object tracking techniques, which often struggle to differentiate between identical objects or necessitate the installation of fixed cameras for global object movement tracking. In response to these limitations, we present a novel approach to address the tracking of identical objects in an AR scene to enrich physical-virtual interaction. Our method leverages partial scene observations captured by an AR headset, utilizing the perspective and spatial data provided by this technology. Object identities within the scene are determined through the solution of a label assignment problem using integer programming. To enhance computational efficiency, we incorporate a Voronoi diagram-based pruning method into our approach. Our implementation of this approach in a farm-to-table AR game demonstrates its satisfactory performance and robustness. Furthermore, we showcase the versatility and practicality of our method through applications in AR storytelling and a simulated gaming robot. Our video demo is available at: https://youtu.be/rPGkLYuKvCQ.
Image-based Regularization for Action Smoothness in Autonomous Miniature Racing Car with Deep Reinforcement Learning
Jul 17, 2023



Deep reinforcement learning has achieved significant results in low-level controlling tasks. However, for some applications like autonomous driving and drone flying, it is difficult to control behavior stably since the agent may suddenly change its actions which often lowers the controlling system's efficiency, induces excessive mechanical wear, and causes uncontrollable, dangerous behavior to the vehicle. Recently, a method called conditioning for action policy smoothness (CAPS) was proposed to solve the problem of jerkiness in low-dimensional features for applications such as quadrotor drones. To cope with high-dimensional features, this paper proposes image-based regularization for action smoothness (I-RAS) for solving jerky control in autonomous miniature car racing. We also introduce a control based on impact ratio, an adaptive regularization weight to control the smoothness constraint, called IR control. In the experiment, an agent with I-RAS and IR control significantly improves the success rate from 59% to 95%. In the real-world-track experiment, the agent also outperforms other methods, namely reducing the average finish lap time, while also improving the completion rate even without real world training. This is also justified by an agent based on I-RAS winning the 2022 AWS DeepRacer Final Championship Cup.
Digital Twins for Marine Operations: A Brief Review on Their Implementation
Jan 16, 2023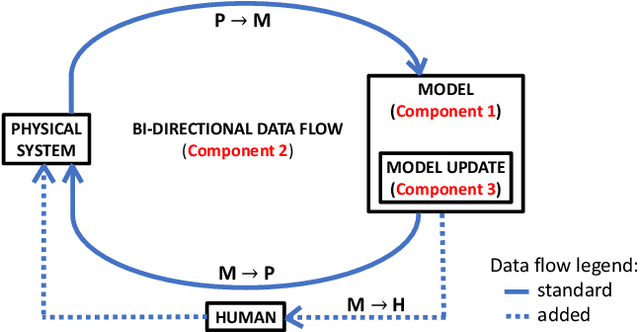


While the concept of a digital twin to support maritime operations is gaining attention for predictive maintenance, real-time monitoring, control, and overall process optimization, clarity on its implementation is missing in the literature. Therefore, in this review we show how different authors implemented their digital twins, discuss our findings, and finally give insights on future research directions.
Towards More Efficient EfficientDets and Low-Light Real-Time Marine Debris Detection
Mar 14, 2022
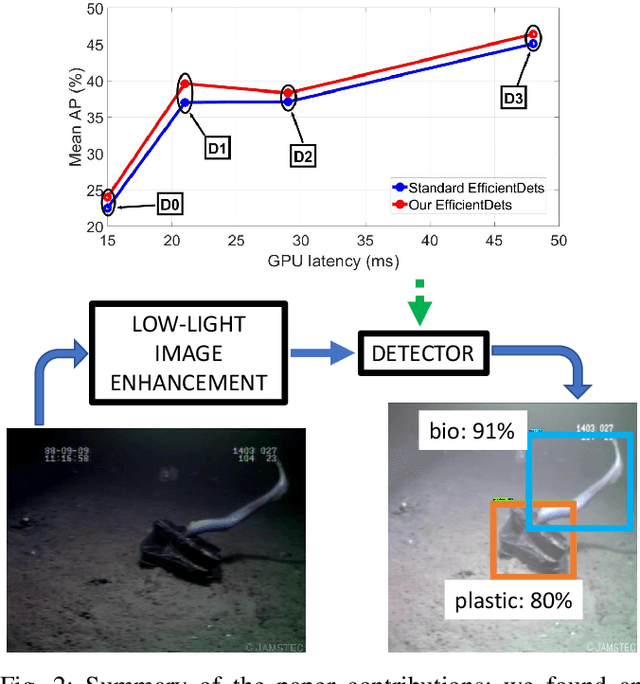

Marine debris is a problem both for the health of marine environments and for the human health since tiny pieces of plastic called "microplastics" resulting from the debris decomposition over the time are entering the food chain at any levels. For marine debris detection and removal, autonomous underwater vehicles (AUVs) are a potential solution. In this letter, we focus on the efficiency of AUV vision for real-time and low-light object detection. First, we improved the efficiency of a class of state-of-the-art object detectors, namely EfficientDets, by 1.5% AP on D0, 2.6% AP on D1, 1.2% AP on D2 and 1.3% AP on D3 without increasing the GPU latency. Subsequently, we created and made publicly available a dataset for the detection of in-water plastic bags and bottles and trained our improved EfficientDets on this and another dataset for marine debris detection. Finally, we investigated how the detector performance is affected by low-light conditions and compared two low-light underwater image enhancement strategies both in terms of accuracy and latency. Source code and dataset are publicly available.
Cross-Modal Contrastive Learning of Representations for Navigation using Lightweight, Low-Cost Millimeter Wave Radar for Adverse Environmental Conditions
Jan 10, 2021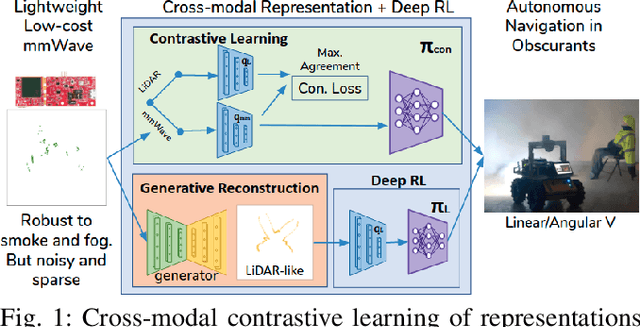
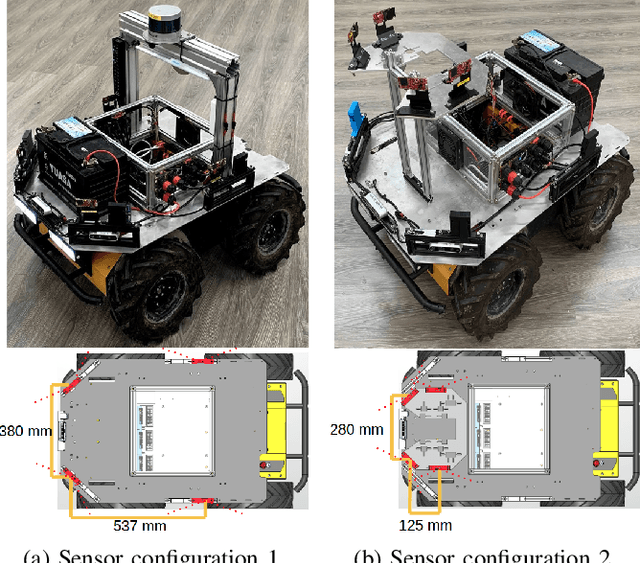
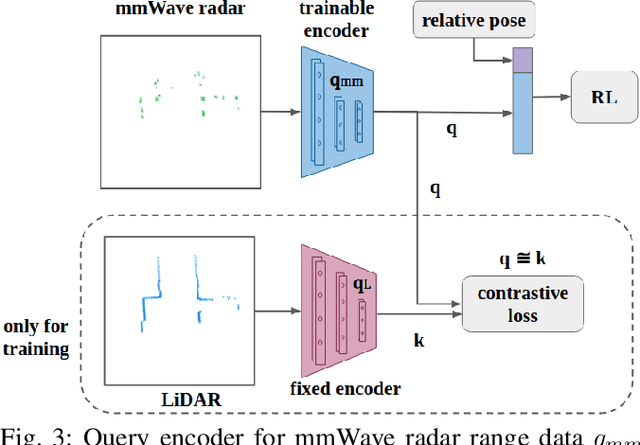
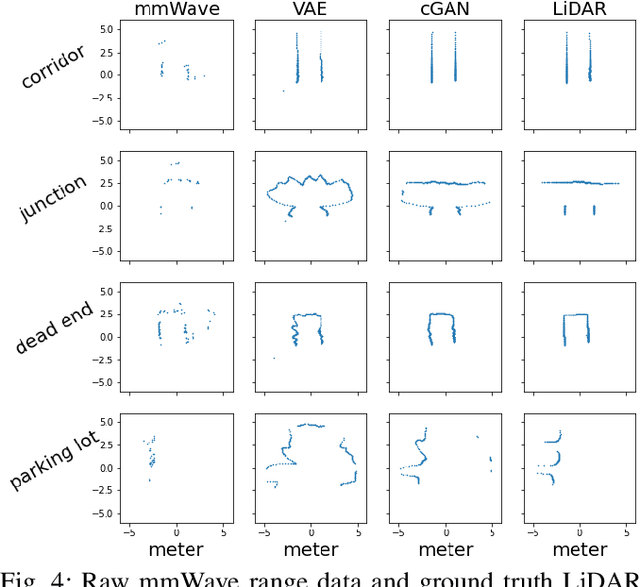
Deep reinforcement learning (RL), where the agent learns from mistakes, has been successfully applied to a variety of tasks. With the aim of learning collision-free policies for unmanned vehicles, deep RL has been used for training with various types of data, such as colored images, depth images, and LiDAR point clouds, without the use of classic map--localize--plan approaches. However, existing methods are limited by their reliance on cameras and LiDAR devices, which have degraded sensing under adverse environmental conditions (e.g., smoky environments). In response, we propose the use of single-chip millimeter-wave (mmWave) radar, which is lightweight and inexpensive, for learning-based autonomous navigation. However, because mmWave radar signals are often noisy and sparse, we propose a cross-modal contrastive learning for representation (CM-CLR) method that maximizes the agreement between mmWave radar data and LiDAR data in the training stage. We evaluated our method in real-world robot compared with 1) a method with two separate networks using cross-modal generative reconstruction and an RL policy and 2) a baseline RL policy without cross-modal representation. Our proposed end-to-end deep RL policy with contrastive learning successfully navigated the robot through smoke-filled maze environments and achieved better performance compared with generative reconstruction methods, in which noisy artifact walls or obstacles were produced. All pretrained models and hardware settings are open access for reproducing this study and can be obtained at https://arg-nctu.github.io/projects/deeprl-mmWave.html
Team NCTU: Toward AI-Driving for Autonomous Surface Vehicles -- From Duckietown to RobotX
Oct 31, 2019



Robotic software and hardware systems of autonomous surface vehicles have been developed in transportation, military, and ocean researches for decades. Previous efforts in RobotX Challenges 2014 and 2016 facilitates the developments for important tasks such as obstacle avoidance and docking. Team NCTU is motivated by the AI Driving Olympics (AI-DO) developed by the Duckietown community, and adopts the principles to RobotX challenge. With the containerization (Docker) and uniformed AI agent (with observations and actions), we could better 1) integrate solutions developed in different middlewares (ROS and MOOS), 2) develop essential functionalities of from simulation (Gazebo) to real robots (either miniaturized or full-sized WAM-V), and 3) compare different approaches either from classic model-based or learning-based. Finally, we setup an outdoor on-surface platform with localization services for evaluation. Some of the preliminary results will be presented for the Team NCTU participations of the RobotX competition in Hawaii in 2018.
Duckiefloat: a Collision-Tolerant Resource-Constrained Blimp for Long-Term Autonomy in Subterranean Environments
Oct 31, 2019
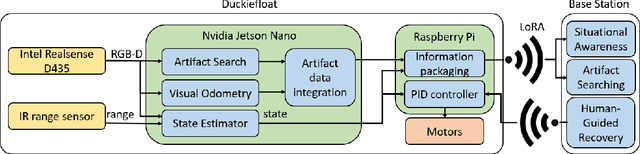
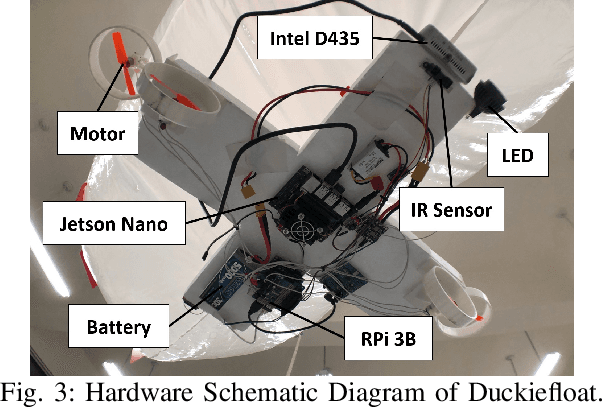

There are several challenges for search and rescue robots: mobility, perception, autonomy, and communication. Inspired by the DARPA Subterranean (SubT) Challenge, we propose an autonomous blimp robot, which has the advantages of low power consumption and collision-tolerance compared to other aerial vehicles like drones. This is important for search and rescue tasks that usually last for one or more hours. However, the underground constrained passages limit the size of blimp envelope and its payload, making the proposed system resource-constrained. Therefore, a careful design consideration is needed to build a blimp system with on-board artifact search and SLAM. In order to reach long-term operation, a failure-aware algorithm with minimal communication to human supervisor to have situational awareness and send control signals to the blimp when needed.