 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Regularization for Action Smoothness in Robotic Control with Reinforcement Learning
Jul 05, 2024

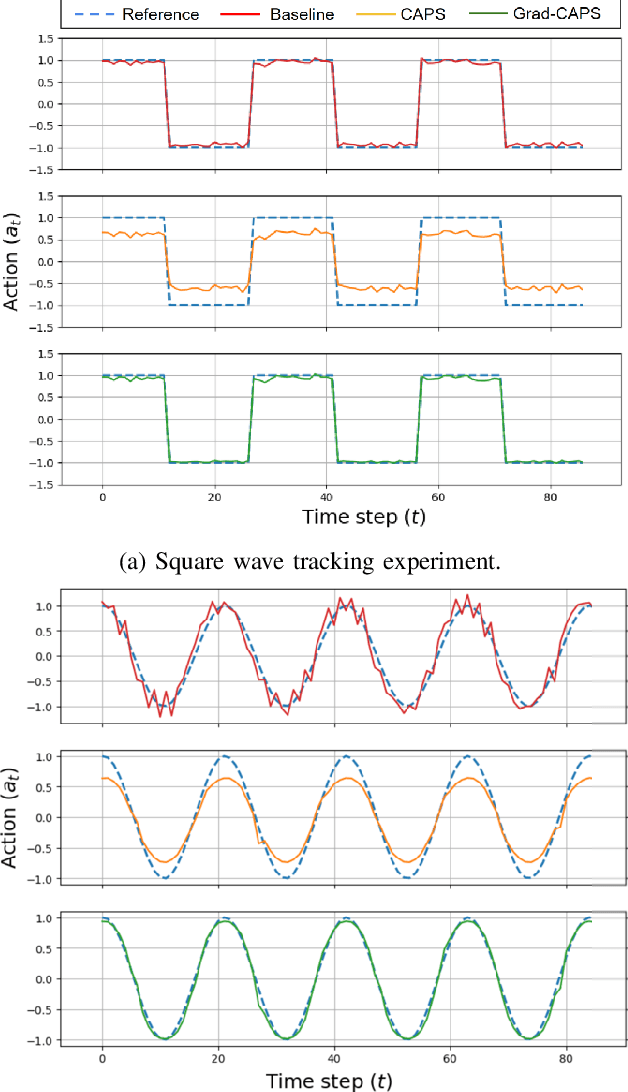
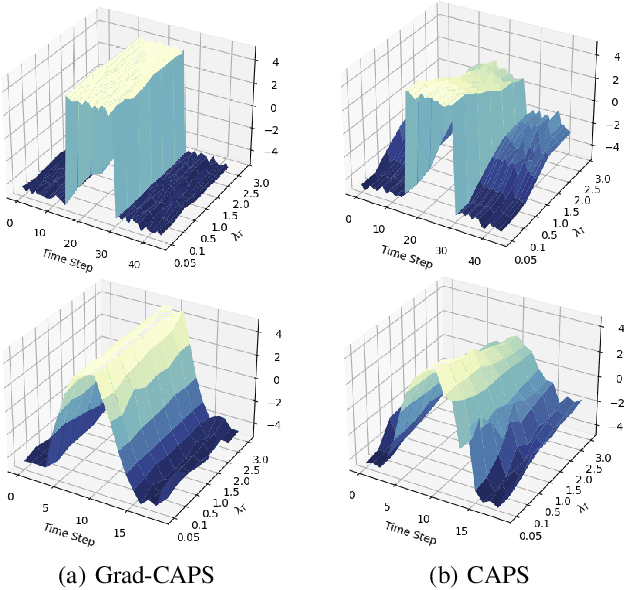
Deep Reinforcement Learning (DRL) has achieved remarkable success, ranging from complex computer games to real-world applications, showing the potential for intelligent agents capable of learning in dynamic environments. However, its application in real-world scenarios presents challenges, including the jerky problem, in which jerky trajectories not only compromise system safety but also increase power consumption and shorten the service life of robotic and autonomous systems. To address jerky actions, a method called conditioning for action policy smoothness (CAPS) was proposed by adding regularization terms to reduce the action changes. This paper further proposes a novel method, named Gradient-based CAPS (Grad-CAPS), that modifies CAPS by reducing the difference in the gradient of action and then uses displacement normalization to enable the agent to adapt to invariant action scales. Consequently, our method effectively reduces zigzagging action sequences while enhancing policy expressiveness and the adaptability of our method across diverse scenarios and environments. In the experiments, we integrated Grad-CAPS with different reinforcement learning algorithms and evaluated its performance on various robotic-related tasks in DeepMind Control Suite and OpenAI Gym environments. The results demonstrate that Grad-CAPS effectively improves performance while maintaining a comparable level of smoothness compared to CAPS and Vanilla agents.
Multi-Agent Training for Pommerman: Curriculum Learning and Population-based Self-Play Approach
Jun 30, 2024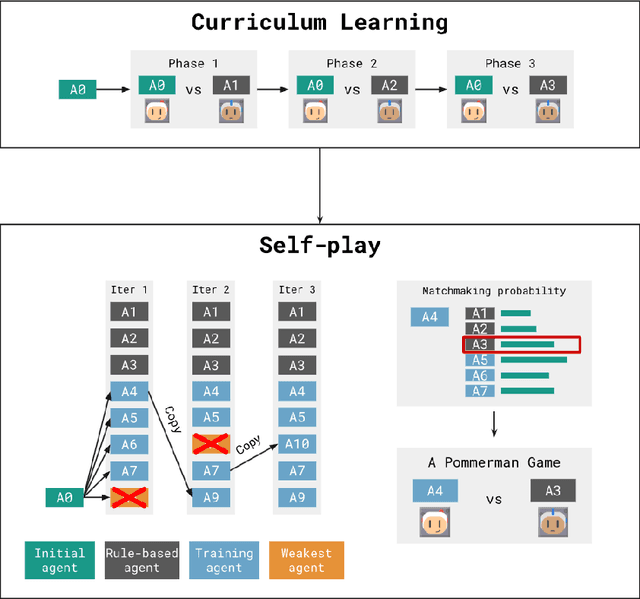
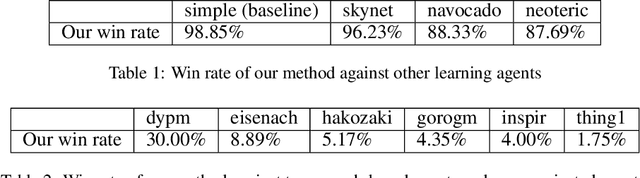
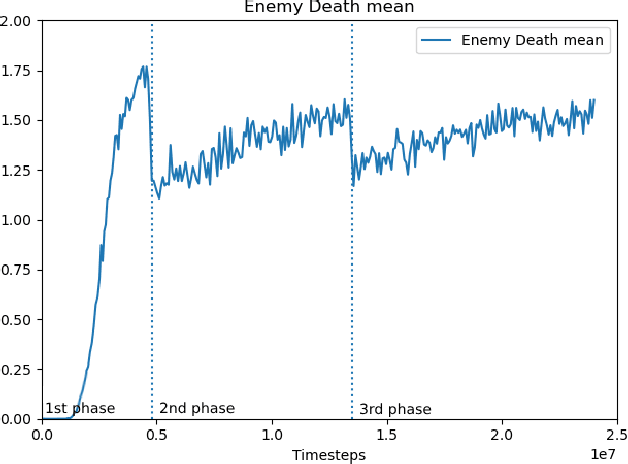
Pommerman is a multi-agent environment that has received considerable attention from researchers in recent years. This environment is an ideal benchmark for multi-agent training, providing a battleground for two teams with communication capabilities among allied agents. Pommerman presents significant challenges for model-free reinforcement learning due to delayed action effects, sparse rewards, and false positives, where opponent players can lose due to their own mistakes. This study introduces a system designed to train multi-agent systems to play Pommerman using a combination of curriculum learning and population-based self-play. We also tackle two challenging problems when deploying the multi-agent training system for competitive games: sparse reward and suitable matchmaking mechanism. Specifically, we propose an adaptive annealing factor based on agents' performance to adjust the dense exploration reward during training dynamically. Additionally, we implement a matchmaking mechanism utilizing the Elo rating system to pair agents effectively. Our experimental results demonstrate that our trained agent can outperform top learning agents without requiring communication among allied agents.
A SAM-based Solution for Hierarchical Panoptic Segmentation of Crops and Weeds Competition
Sep 24, 2023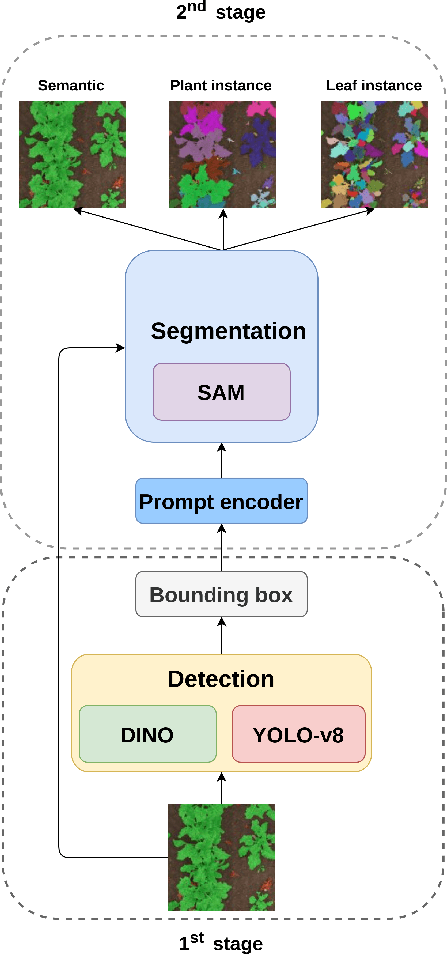
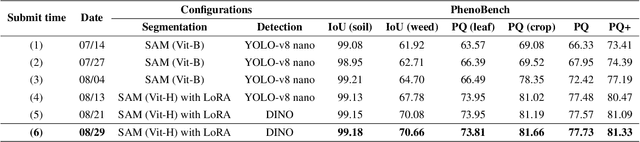
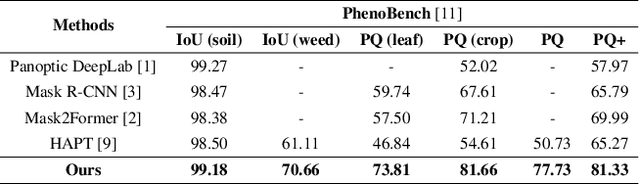

Panoptic segmentation in agriculture is an advanced computer vision technique that provides a comprehensive understanding of field composition. It facilitates various tasks such as crop and weed segmentation, plant panoptic segmentation, and leaf instance segmentation, all aimed at addressing challenges in agriculture. Exploring the application of panoptic segmentation in agriculture, the 8th Workshop on Computer Vision in Plant Phenotyping and Agriculture (CVPPA) hosted the challenge of hierarchical panoptic segmentation of crops and weeds using the PhenoBench dataset. To tackle the tasks presented in this competition, we propose an approach that combines the effectiveness of the Segment AnyThing Model (SAM) for instance segmentation with prompt input from object detection models. Specifically, we integrated two notable approaches in object detection, namely DINO and YOLO-v8. Our best-performing model achieved a PQ+ score of 81.33 based on the evaluation metrics of the competition.
Image-based Regularization for Action Smoothness in Autonomous Miniature Racing Car with Deep Reinforcement Learning
Jul 17, 2023



Deep reinforcement learning has achieved significant results in low-level controlling tasks. However, for some applications like autonomous driving and drone flying, it is difficult to control behavior stably since the agent may suddenly change its actions which often lowers the controlling system's efficiency, induces excessive mechanical wear, and causes uncontrollable, dangerous behavior to the vehicle. Recently, a method called conditioning for action policy smoothness (CAPS) was proposed to solve the problem of jerkiness in low-dimensional features for applications such as quadrotor drones. To cope with high-dimensional features, this paper proposes image-based regularization for action smoothness (I-RAS) for solving jerky control in autonomous miniature car racing. We also introduce a control based on impact ratio, an adaptive regularization weight to control the smoothness constraint, called IR control. In the experiment, an agent with I-RAS and IR control significantly improves the success rate from 59% to 95%. In the real-world-track experiment, the agent also outperforms other methods, namely reducing the average finish lap time, while also improving the completion rate even without real world training. This is also justified by an agent based on I-RAS winning the 2022 AWS DeepRacer Final Championship Cup.
Reinforcement Learning for Picking Cluttered General Objects with Dense Object Descriptors
Apr 20, 2023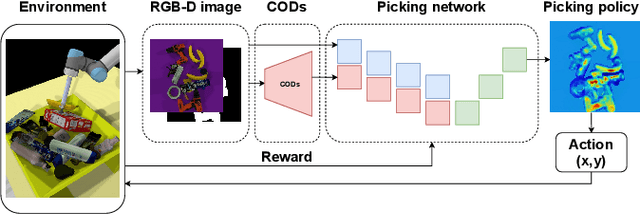
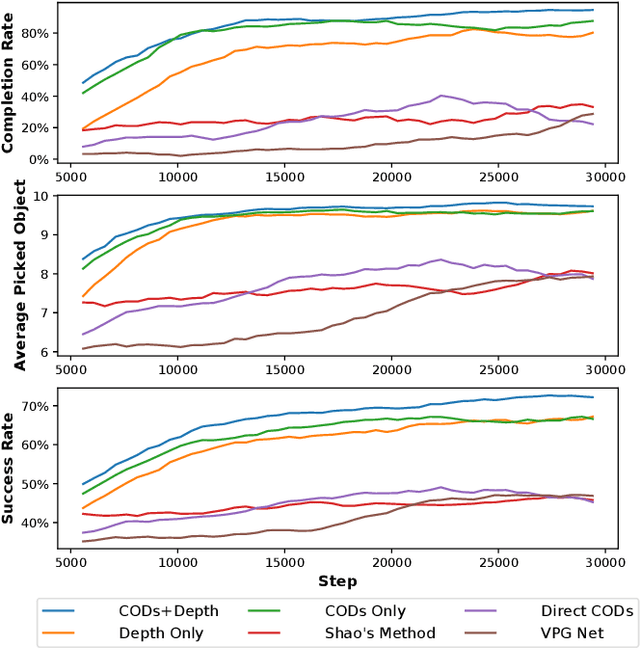

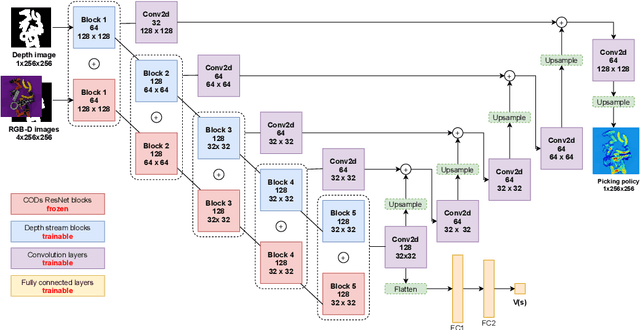
Picking cluttered general objects is a challenging task due to the complex geometries and various stacking configurations. Many prior works utilize pose estimation for picking, but pose estimation is difficult on cluttered objects. In this paper, we propose Cluttered Objects Descriptors (CODs), a dense cluttered objects descriptor that can represent rich object structures, and use the pre-trained CODs network along with its intermediate outputs to train a picking policy. Additionally, we train the policy with reinforcement learning, which enable the policy to learn picking without supervision. We conduct experiments to demonstrate that our CODs is able to consistently represent seen and unseen cluttered objects, which allowed for the picking policy to robustly pick cluttered general objects. The resulting policy can pick 96.69% of unseen objects in our experimental environment which is twice as cluttered as the training scenarios.
Learning Sim-to-Real Dense Object Descriptors for Robotic Manipulation
Apr 18, 2023
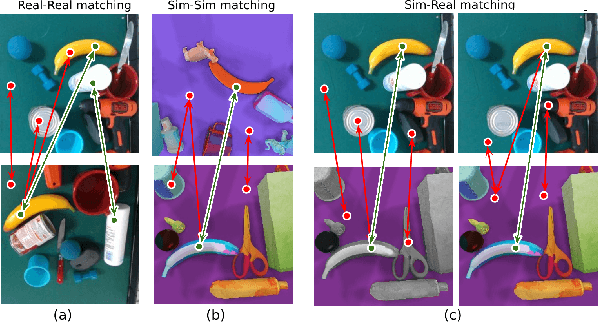


It is crucial to address the following issues for ubiquitous robotics manipulation applications: (a) vision-based manipulation tasks require the robot to visually learn and understand the object with rich information like dense object descriptors; and (b) sim-to-real transfer in robotics aims to close the gap between simulated and real data. In this paper, we present Sim-to-Real Dense Object Nets (SRDONs), a dense object descriptor that not only understands the object via appropriate representation but also maps simulated and real data to a unified feature space with pixel consistency. We proposed an object-to-object matching method for image pairs from different scenes and different domains. This method helps reduce the effort of training data from real-world by taking advantage of public datasets, such as GraspNet. With sim-to-real object representation consistency, our SRDONs can serve as a building block for a variety of sim-to-real manipulation tasks. We demonstrate in experiments that pre-trained SRDONs significantly improve performances on unseen objects and unseen visual environments for various robotic tasks with zero real-world training.
Image-Based Conditioning for Action Policy Smoothness in Autonomous Miniature Car Racing with Reinforcement Learning
May 19, 2022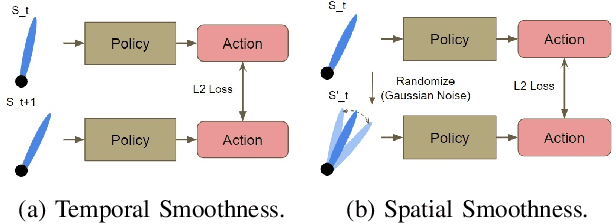


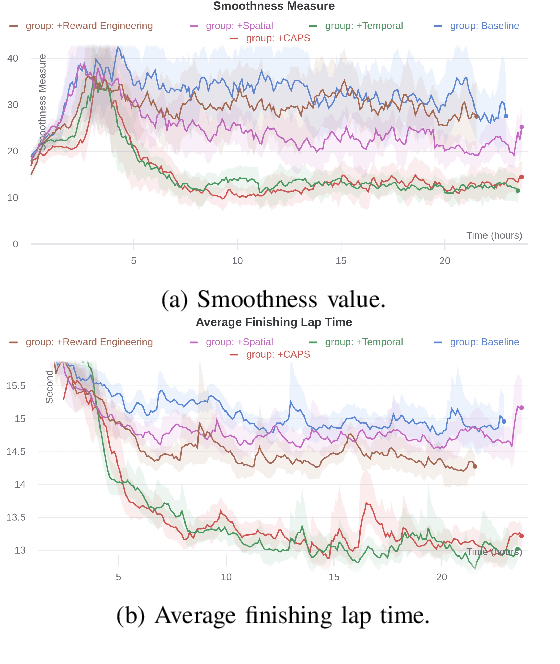
In recent years, deep reinforcement learning has achieved significant results in low-level controlling tasks. However, the problem of control smoothness has less attention. In autonomous driving, unstable control is inevitable since the vehicle might suddenly change its actions. This problem will lower the controlling system's efficiency, induces excessive mechanical wear, and causes uncontrollable, dangerous behavior to the vehicle. In this paper, we apply the Conditioning for Action Policy Smoothness (CAPS) with image-based input to smooth the control of an autonomous miniature car racing. Applying CAPS and sim-to-real transfer methods helps to stabilize the control at a higher speed. Especially, the agent with CAPS and CycleGAN reduces 21.80% of the average finishing lap time. Moreover, we also conduct extensive experiments to analyze the impact of CAPS components.