 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURENet: Combining Unified Representations for Efficient Chronic Disease Prediction
Nov 14, 2025Electronic health records (EHRs) are designed to synthesize diverse data types, including unstructured clinical notes, structured lab tests, and time-series visit data. Physicians draw on these multimodal and temporal sources of EHR data to form a comprehensive view of a patient's health, which is crucial for informed therapeutic decision-making. Yet, most predictive models fail to fully capture the interactions, redundancies, and temporal patterns across multiple data modalities, often focusing on a single data type or overlooking these complexities. In this paper, we present CURENet, a multimodal model (Combining Unified Representations for Efficient chronic disease prediction) that integrates unstructured clinical notes, lab tests, and patients' time-series data by utilizing large language models (LLMs) for clinical text processing and textual lab tests, as well as transformer encoders for longitudinal sequential visits. CURENet has been capable of capturing the intricate interaction between different forms of clinical data and creating a more reliable predictive model for chronic illnesses. We evaluated CURENet using the public MIMIC-III and private FEMH datasets, where it achieved over 94\% accuracy in predicting the top 10 chronic conditions in a multi-label framework. Our findings highlight the potential of multimodal EHR integration to enhance clinical decision-making and improve patient outcomes.
Multi-OphthaLingua: A Multilingual Benchmark for Assessing and Debiasing LLM Ophthalmological QA in LMICs
Dec 18, 2024



Current ophthalmology clinical workflows are plagued by over-referrals, long waits, and complex and heterogeneous medical records. Large language models (LLMs) present a promising solution to automate various procedures such as triaging, preliminary tests like visual acuity assessment, and report summaries. However, LLMs have demonstrated significantly varied performance across different languages in natural language question-answering tasks, potentially exacerbating healthcare disparities in Low and Middle-Income Countries (LMICs). This study introduces the first multilingual ophthalmological question-answering benchmark with manually curated questions parallel across languages, allowing for direct cross-lingual comparisons. Our evaluation of 6 popular LLMs across 7 different languages reveals substantial bias across different languages, highlighting risks for clinical deployment of LLMs in LMICs. Existing debiasing methods such as Translation Chain-of-Thought or Retrieval-augmented generation (RAG) by themselves fall short of closing this performance gap, often failing to improve performance across all languages and lacking specificity for the medical domain. To address this issue, We propose CLARA (Cross-Lingual Reflective Agentic system), a novel inference time de-biasing method leveraging retrieval augmented generation and self-verification. Our approach not only improves performance across all languages but also significantly reduces the multilingual bias gap, facilitating equitable LLM application across the globe.
MEDFuse: Multimodal EHR Data Fusion with Masked Lab-Test Modeling and Large Language Models
Jul 17, 2024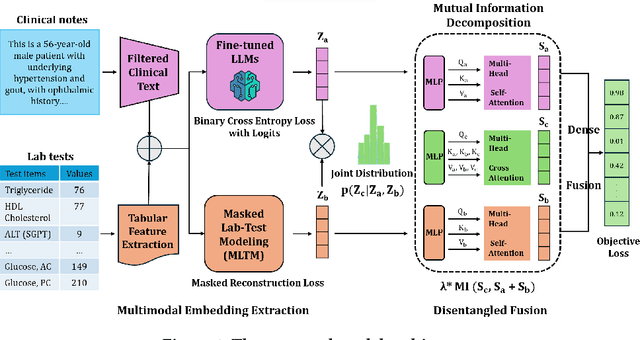
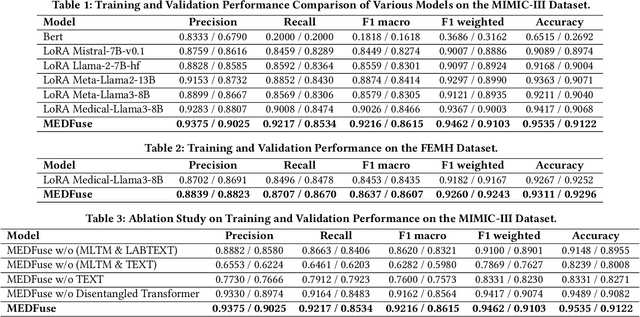
Electronic health records (EHRs) are multimodal by nature, consisting of structured tabular features like lab tests and unstructured clinical notes. In real-life clinical practice, doctors use complementary multimodal EHR data sources to get a clearer picture of patients' health and support clinical decision-making. However, most EHR predictive models do not reflect these procedures, as they either focus on a single modality or overlook the inter-modality interactions/redundancy. In this work, we propose MEDFuse, a Multimodal EHR Data Fusion framework that incorporates masked lab-test modeling and large language models (LLMs) to effectively integrate structured and unstructured medical data. MEDFuse leverages multimodal embeddings extracted from two sources: LLMs fine-tuned on free clinical text and masked tabular transformers trained on structured lab test results. We design a disentangled transformer module, optimized by a mutual information loss to 1) decouple modality-specific and modality-shared information and 2) extract useful joint representation from the noise and redundancy present in clinical notes. Through comprehensive validation on the public MIMIC-III dataset and the in-house FEMH dataset, MEDFuse demonstrates great potential in advancing clinical predictions, achieving over 90% F1 score in the 10-disease multi-label classification task.
Gradient-based Regularization for Action Smoothness in Robotic Control with Reinforcement Learning
Jul 05, 2024

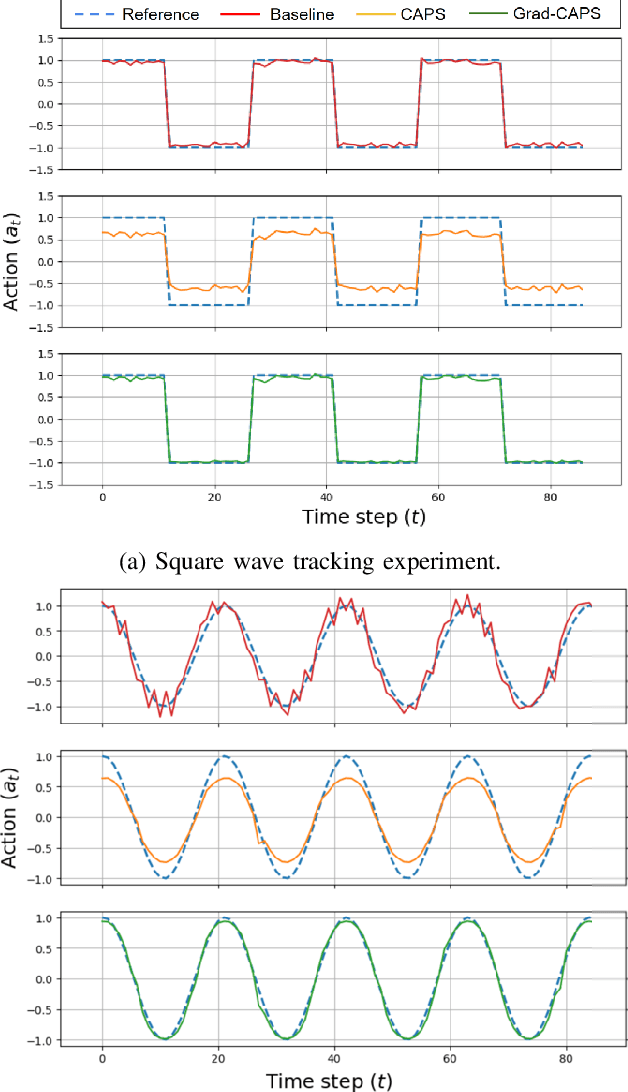
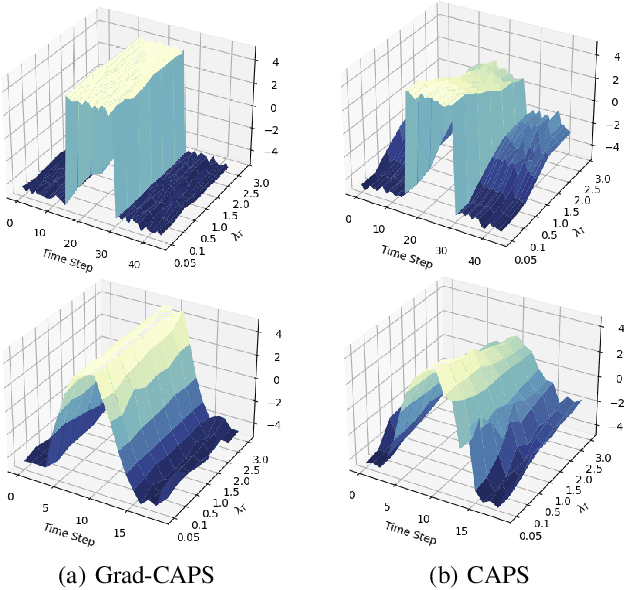
Deep Reinforcement Learning (DRL) has achieved remarkable success, ranging from complex computer games to real-world applications, showing the potential for intelligent agents capable of learning in dynamic environments. However, its application in real-world scenarios presents challenges, including the jerky problem, in which jerky trajectories not only compromise system safety but also increase power consumption and shorten the service life of robotic and autonomous systems. To address jerky actions, a method called conditioning for action policy smoothness (CAPS) was proposed by adding regularization terms to reduce the action changes. This paper further proposes a novel method, named Gradient-based CAPS (Grad-CAPS), that modifies CAPS by reducing the difference in the gradient of action and then uses displacement normalization to enable the agent to adapt to invariant action scales. Consequently, our method effectively reduces zigzagging action sequences while enhancing policy expressiveness and the adaptability of our method across diverse scenarios and environments. In the experiments, we integrated Grad-CAPS with different reinforcement learning algorithms and evaluated its performance on various robotic-related tasks in DeepMind Control Suite and OpenAI Gym environments. The results demonstrate that Grad-CAPS effectively improves performance while maintaining a comparable level of smoothness compared to CAPS and Vanilla agents.