 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human-Like RL Agents Through Trajectory Optimization With Action Quantization
Nov 19, 2025Human-like agents have long been one of the goals in pursuing artificial intelligence. Although reinforcement learning (RL) has achieved superhuman performance in many domains, relatively little attention has been focused on designing human-like RL agents. As a result, many reward-driven RL agents often exhibit unnatural behaviors compared to humans, raising concerns for both interpretability and trustworthiness. To achieve human-like behavior in RL, this paper first formulates human-likeness as trajectory optimization, where the objective is to find an action sequence that closely aligns with human behavior while also maximizing rewards, and adapts the classic receding-horizon control to human-like learning as a tractable and efficient implementation. To achieve this, we introduce Macro Action Quantization (MAQ), a human-like RL framework that distills human demonstrations into macro actions via Vector-Quantized VAE. Experiments on D4RL Adroit benchmarks show that MAQ significantly improves human-likeness, increasing trajectory similarity scores, and achieving the highest human-likeness rankings among all RL agents in the human evaluation study. Our results also demonstrate that MAQ can be easily integrated into various off-the-shelf RL algorithms, opening a promising direction for learning human-like RL agents. Our code is available at https://rlg.iis.sinica.edu.tw/papers/MAQ.
QCA-MolGAN: Quantum Circuit Associative Molecular GAN with Multi-Agent Reinforcement Learning
Sep 05, 2025Navigating the vast chemical space of molecular structures to design novel drug molecules with desired target properties remains a central challenge in drug discovery. Recent advances in generative models offer promising solutions. This work presents a novel quantum circuit Born machine (QCBM)-enabled Generative Adversarial Network (GAN), called QCA-MolGAN, for generating drug-like molecules. The QCBM serves as a learnable prior distribution, which is associatively trained to define a latent space aligning with high-level features captured by the GANs discriminator. Additionally, we integrate a novel multi-agent reinforcement learning network to guide molecular generation with desired targeted properties, optimising key metrics such as quantitative estimate of drug-likeness (QED), octanol-water partition coefficient (LogP) and synthetic accessibility (SA) scores in conjunction with one another. Experimental results demonstrate that our approach enhances the property alignment of generated molecules with the multi-agent reinforcement learning agents effectively balancing chemical properties.
Frankenstein Optimizer: Harnessing the Potential by Revisiting Optimization Tricks
Mar 04, 2025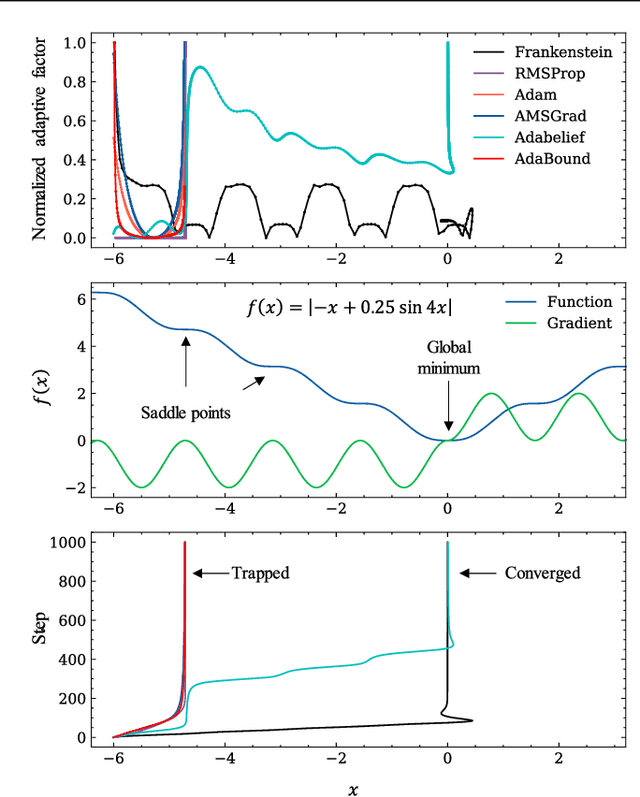
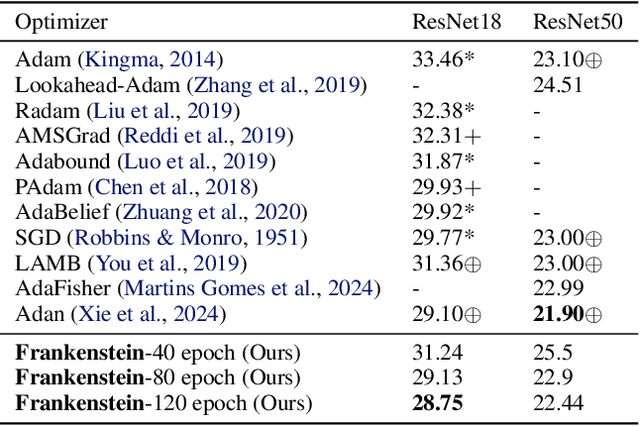
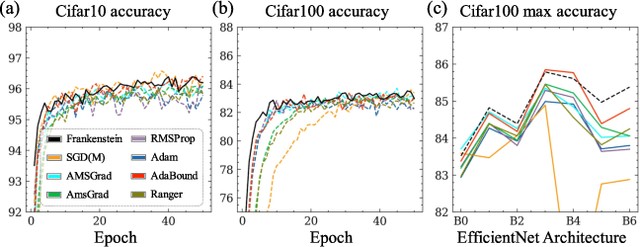
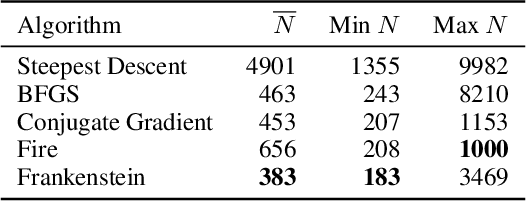
Gradient-based optimization drives the unprecedented performance of modern deep neural network models across diverse applications. Adaptive algorithms have accelerated neural network training due to their rapid convergence rates; however, they struggle to find ``flat minima" reliably, resulting in suboptimal generalization compared to stochastic gradient descent (SGD). By revisiting various adaptive algorithms' mechanisms, we propose the Frankenstein optimizer, which combines their advantages. The proposed Frankenstein dynamically adjusts first- and second-momentum coefficients according to the optimizer's current state to directly maintain consistent learning dynamics and immediately reflect sudden gradient changes. Extensive experiments across several research domains such as computer vision, natural language processing, few-shot learning, and scientific simulations show that Frankenstein surpasses existing adaptive algorithms and SGD empirically regarding convergence speed and generalization performance. Furthermore, this research deepens our understanding of adaptive algorithms through centered kernel alignment analysis and loss landscape visualization during the learning process.
Identifying and Clustering Counter Relationships of Team Compositions in PvP Games for Efficient Balance Analysis
Aug 30, 2024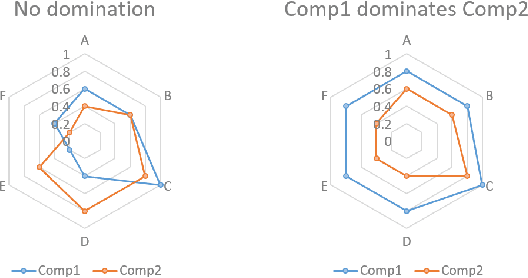
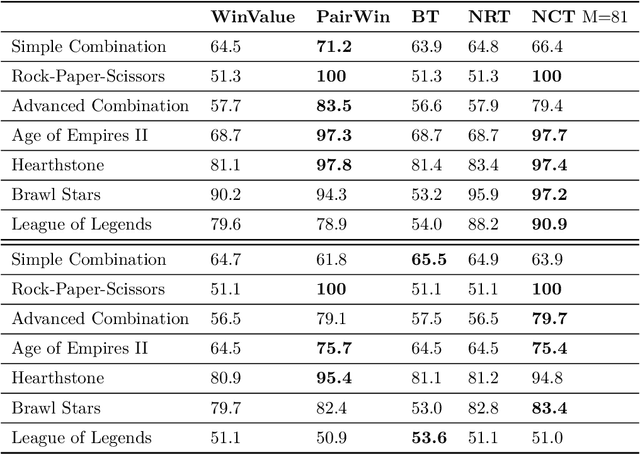
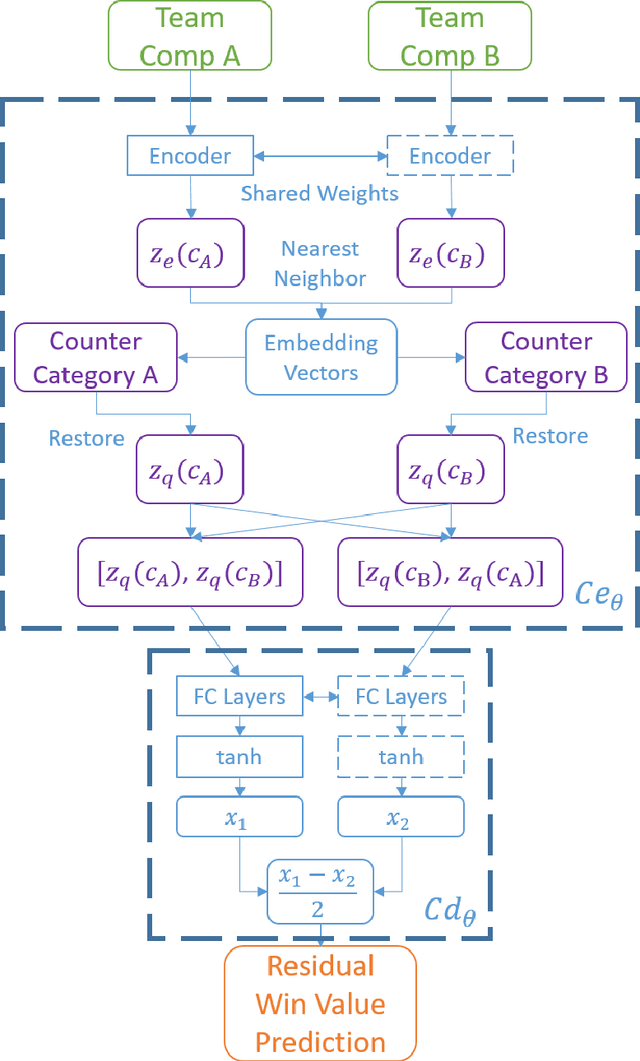
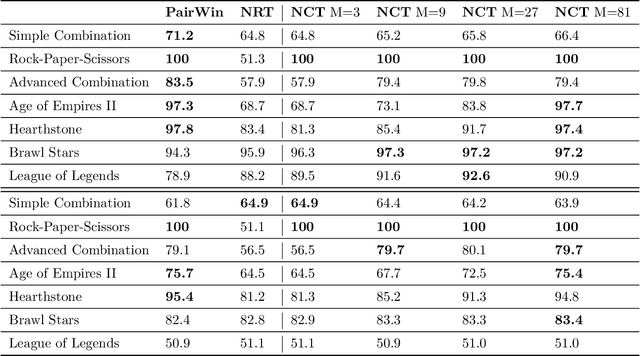
How can balance be quantified in game settings? This question is crucial for game designers, especially in player-versus-player (PvP) games, where analyzing the strength relations among predefined team compositions-such as hero combinations in multiplayer online battle arena (MOBA) games or decks in card games-is essential for enhancing gameplay and achieving balance. We have developed two advanced measures that extend beyond the simplistic win rate to quantify balance in zero-sum competitive scenarios. These measures are derived from win value estimations, which employ strength rating approximations via the Bradley-Terry model and counter relationship approximations via vector quantization, significantly reducing the computational complexity associated with traditional win value estimations. Throughout the learning process of these models, we identify useful categories of compositions and pinpoint their counter relationships, aligning with the experiences of human players without requiring specific game knowledge. Our methodology hinges on a simple technique to enhance codebook utilization in discrete representation with a deterministic vector quantization process for an extremely small state space. Our framework has been validated in popular online games, including Age of Empires II, Hearthstone, Brawl Stars, and League of Legends. The accuracy of the observed strength relations in these games is comparable to traditional pairwise win value predictions, while also offering a more manageable complexity for analysis. Ultimately, our findings contribute to a deeper understanding of PvP game dynamics and present a methodology that significantly improves game balance evaluation and design.
Gradient-based Regularization for Action Smoothness in Robotic Control with Reinforcement Learning
Jul 05, 2024

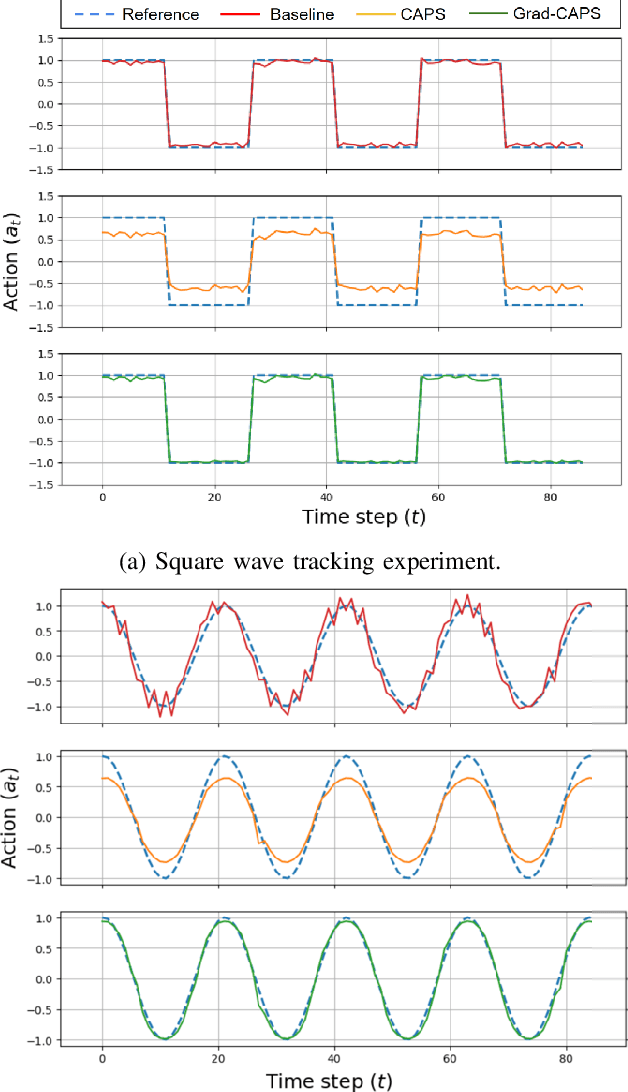
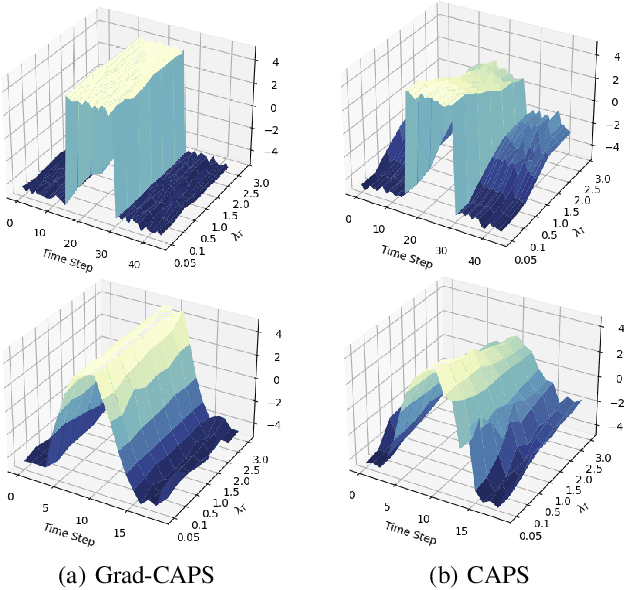
Deep Reinforcement Learning (DRL) has achieved remarkable success, ranging from complex computer games to real-world applications, showing the potential for intelligent agents capable of learning in dynamic environments. However, its application in real-world scenarios presents challenges, including the jerky problem, in which jerky trajectories not only compromise system safety but also increase power consumption and shorten the service life of robotic and autonomous systems. To address jerky actions, a method called conditioning for action policy smoothness (CAPS) was proposed by adding regularization terms to reduce the action changes. This paper further proposes a novel method, named Gradient-based CAPS (Grad-CAPS), that modifies CAPS by reducing the difference in the gradient of action and then uses displacement normalization to enable the agent to adapt to invariant action scales. Consequently, our method effectively reduces zigzagging action sequences while enhancing policy expressiveness and the adaptability of our method across diverse scenarios and environments. In the experiments, we integrated Grad-CAPS with different reinforcement learning algorithms and evaluated its performance on various robotic-related tasks in DeepMind Control Suite and OpenAI Gym environments. The results demonstrate that Grad-CAPS effectively improves performance while maintaining a comparable level of smoothness compared to CAPS and Vanilla agents.
Best of Three Worlds: Adaptive Experimentation for Digital Marketing in Practice
Feb 26, 2024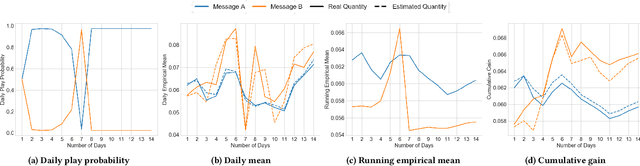
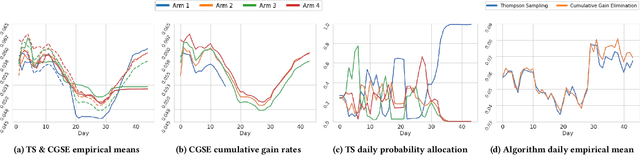
Adaptive experimental design (AED) methods are increasingly being used in industry as a tool to boost testing throughput or reduce experimentation cost relative to traditional A/B/N testing methods. However, the behavior and guarantees of such methods are not well-understood beyond idealized stationary settings. This paper shares lessons learned regarding the challenges of naively using AED systems in industrial settings where non-stationarity is prevalent, while also providing perspectives on the proper objectives and system specifications in such settings. We developed an AED framework for counterfactual inference based on these experiences, and tested it in a commercial environment.