 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaystyle and Artificial Intelligence: An Initial Blueprint Through the Lens of Video Games
Aug 26, 2025Contemporary artificial intelligence (AI) development largely centers on rational decision-making, valued for its measurability and suitability for objective evaluation. Yet in real-world contexts, an intelligent agent's decisions are shaped not only by logic but also by deeper influences such as beliefs, values, and preferences. The diversity of human decision-making styles emerges from these differences, highlighting that "style" is an essential but often overlooked dimension of intelligence. This dissertation introduces playstyle as an alternative lens for observing and analyzing the decision-making behavior of intelligent agents, and examines its foundational meaning and historical context from a philosophical perspective. By analyzing how beliefs and values drive intentions and actions, we construct a two-tier framework for style formation: the external interaction loop with the environment and the internal cognitive loop of deliberation. On this basis, we formalize style-related characteristics and propose measurable indicators such as style capacity, style popularity, and evolutionary dynamics. The study focuses on three core research directions: (1) Defining and measuring playstyle, proposing a general playstyle metric based on discretized state spaces, and extending it to quantify strategic diversity and competitive balance; (2) Expressing and generating playstyle, exploring how reinforcement learning and imitation learning can be used to train agents exhibiting specific stylistic tendencies, and introducing a novel approach for human-like style learning and modeling; and (3) Practical applications, analyzing the potential of these techniques in domains such as game design and interactive entertainment. Finally, the dissertation outlines future extensions, including the role of style as a core element in building artificial general intelligence (AGI).
Online Learning of Counter Categories and Ratings in PvP Games
Feb 06, 2025



In competitive games, strength ratings like Elo are widely used to quantify player skill and support matchmaking by accounting for skill disparities better than simple win rate statistics. However, scalar ratings cannot handle complex intransitive relationships, such as counter strategies seen in Rock-Paper-Scissors. To address this, recent work introduced Neural Rating Table and Neural Counter Table, which combine scalar ratings with discrete counter categories to model intransitivity. While effective, these methods rely on neural network training and cannot perform real-time updates. In this paper, we propose an online update algorithm that extends Elo principles to incorporate real-time learning of counter categories. Our method dynamically adjusts both ratings and counter relationships after each match, preserving the explainability of scalar ratings while addressing intransitivity. Experiments on zero-sum competitive games demonstrate its practicality, particularly in scenarios without complex team compositions.
Identifying and Clustering Counter Relationships of Team Compositions in PvP Games for Efficient Balance Analysis
Aug 30, 2024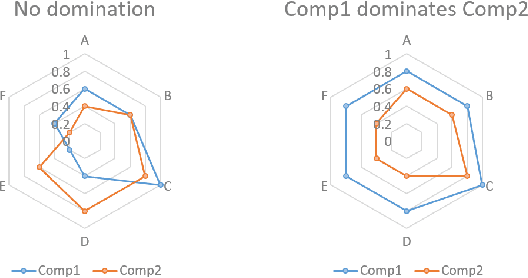
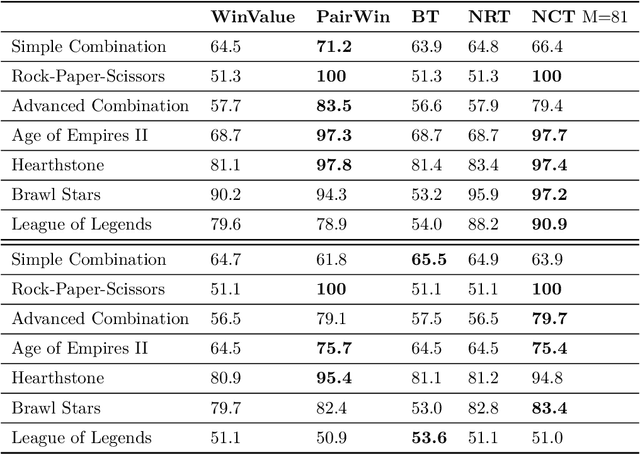
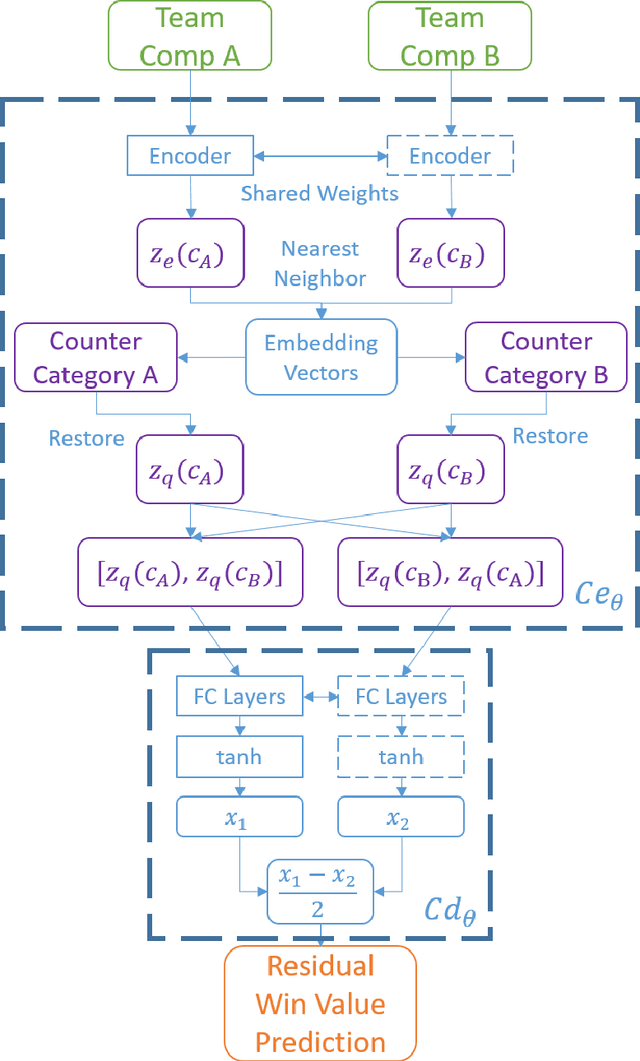
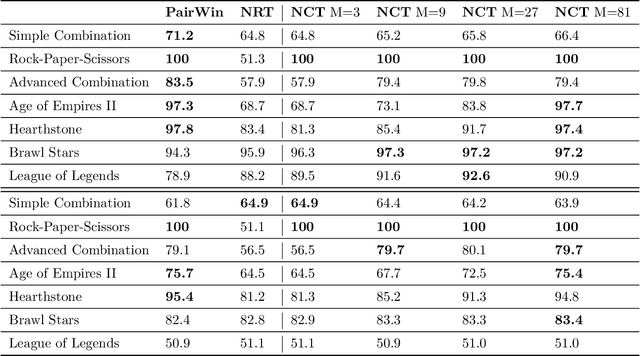
How can balance be quantified in game settings? This question is crucial for game designers, especially in player-versus-player (PvP) games, where analyzing the strength relations among predefined team compositions-such as hero combinations in multiplayer online battle arena (MOBA) games or decks in card games-is essential for enhancing gameplay and achieving balance. We have developed two advanced measures that extend beyond the simplistic win rate to quantify balance in zero-sum competitive scenarios. These measures are derived from win value estimations, which employ strength rating approximations via the Bradley-Terry model and counter relationship approximations via vector quantization, significantly reducing the computational complexity associated with traditional win value estimations. Throughout the learning process of these models, we identify useful categories of compositions and pinpoint their counter relationships, aligning with the experiences of human players without requiring specific game knowledge. Our methodology hinges on a simple technique to enhance codebook utilization in discrete representation with a deterministic vector quantization process for an extremely small state space. Our framework has been validated in popular online games, including Age of Empires II, Hearthstone, Brawl Stars, and League of Legends. The accuracy of the observed strength relations in these games is comparable to traditional pairwise win value predictions, while also offering a more manageable complexity for analysis. Ultimately, our findings contribute to a deeper understanding of PvP game dynamics and present a methodology that significantly improves game balance evaluation and design.
Perceptual Similarity for Measuring Decision-Making Style and Policy Diversity in Games
Aug 12, 2024Defining and measuring decision-making styles, also known as playstyles, is crucial in gaming, where these styles reflect a broad spectrum of individuality and diversity. However, finding a universally applicable measure for these styles poses a challenge. Building on Playstyle Distance, the first unsupervised metric to measure playstyle similarity based on game screens and raw actions, we introduce three enhancements to increase accuracy: multiscale analysis with varied state granularity, a perceptual kernel rooted in psychology, and the utilization of the intersection-over-union method for efficient evaluation. These innovations not only advance measurement precision but also offer insights into human cognition of similarity. Across two racing games and seven Atari games, our techniques significantly improve the precision of zero-shot playstyle classification, achieving an accuracy exceeding 90 percent with fewer than 512 observation-action pairs, which is less than half an episode of these games. Furthermore, our experiments with 2048 and Go demonstrate the potential of discrete playstyle measures in puzzle and board games. We also develop an algorithm for assessing decision-making diversity using these measures. Our findings improve the measurement of end-to-end game analysis and the evolution of artificial intelligence for diverse playstyles.
Towards Human-Like RL: Taming Non-Naturalistic Behavior in Deep RL via Adaptive Behavioral Costs in 3D Games
Sep 27, 2023In this paper, we propose a new approach called Adaptive Behavioral Costs in Reinforcement Learning (ABC-RL) for training a human-like agent with competitive strength. While deep reinforcement learning agents have recently achieved superhuman performance in various video games, some of these unconstrained agents may exhibit actions, such as shaking and spinning, that are not typically observed in human behavior, resulting in peculiar gameplay experiences. To behave like humans and retain similar performance, ABC-RL augments behavioral limitations as cost signals in reinforcement learning with dynamically adjusted weights. Unlike traditional constrained policy optimization, we propose a new formulation that minimizes the behavioral costs subject to a constraint of the value function. By leveraging the augmented Lagrangian, our approach is an approximation of the Lagrangian adjustment, which handles the trade-off between the performance and the human-like behavior. Through experiments conducted on 3D games in DMLab-30 and Unity ML-Agents Toolkit, we demonstrate that ABC-RL achieves the same performance level while significantly reducing instances of shaking and spinning. These findings underscore the effectiveness of our proposed approach in promoting more natural and human-like behavior during gameplay.
An Unsupervised Video Game Playstyle Metric via State Discretization
Oct 03, 2021
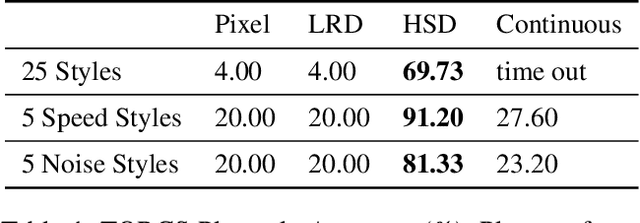
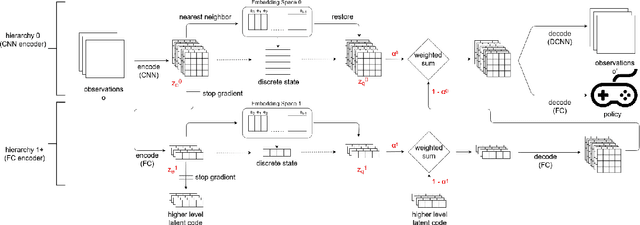
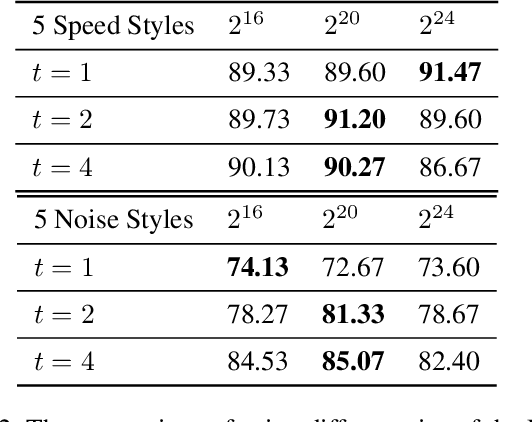
On playing video games, different players usually have their own playstyles. Recently, there have been great improvements for the video game AIs on the playing strength. However, past researches for analyzing the behaviors of players still used heuristic rules or the behavior features with the game-environment support, thus being exhausted for the developers to define the features of discriminating various playstyles. In this paper, we propose the first metric for video game playstyles directly from the game observations and actions, without any prior specification on the playstyle in the target game. Our proposed method is built upon a novel scheme of learning discrete representations that can map game observations into latent discrete states, such that playstyles can be exhibited from these discrete states. Namely, we measure the playstyle distance based on game observations aligned to the same states. We demonstrate high playstyle accuracy of our metric in experiments on some video game platforms, including TORCS, RGSK, and seven Atari games, and for different agents including rule-based AI bots, learning-based AI bots, and human players.
* This version was also published on UAI 2021