 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Solving Life-and-Death Problems in Go Using Relevance-Zone Based Solvers
Dec 23, 2025This paper analyzes the behavior of solving Life-and-Death (L&D) problems in the game of Go using current state-of-the-art computer Go solvers with two techniques: the Relevance-Zone Based Search (RZS) and the relevance-zone pattern table. We examined the solutions derived by relevance-zone based solvers on seven L&D problems from the renowned book "Life and Death Dictionary" written by Cho Chikun, a Go grandmaster, and found several interesting results. First, for each problem, the solvers identify a relevance-zone that highlights the critical areas for solving. Second, the solvers discover a series of patterns, including some that are rare. Finally, the solvers even find different answers compared to the given solutions for two problems. We also identified two issues with the solver: (a) it misjudges values of rare patterns, and (b) it tends to prioritize living directly rather than maximizing territory, which differs from the behavior of human Go players. We suggest possible approaches to address these issues in future work. Our code and data are available at https://rlg.iis.sinica.edu.tw/papers/study-LD-RZ.
Learning Human-Like RL Agents Through Trajectory Optimization With Action Quantization
Nov 19, 2025Human-like agents have long been one of the goals in pursuing artificial intelligence. Although reinforcement learning (RL) has achieved superhuman performance in many domains, relatively little attention has been focused on designing human-like RL agents. As a result, many reward-driven RL agents often exhibit unnatural behaviors compared to humans, raising concerns for both interpretability and trustworthiness. To achieve human-like behavior in RL, this paper first formulates human-likeness as trajectory optimization, where the objective is to find an action sequence that closely aligns with human behavior while also maximizing rewards, and adapts the classic receding-horizon control to human-like learning as a tractable and efficient implementation. To achieve this, we introduce Macro Action Quantization (MAQ), a human-like RL framework that distills human demonstrations into macro actions via Vector-Quantized VAE. Experiments on D4RL Adroit benchmarks show that MAQ significantly improves human-likeness, increasing trajectory similarity scores, and achieving the highest human-likeness rankings among all RL agents in the human evaluation study. Our results also demonstrate that MAQ can be easily integrated into various off-the-shelf RL algorithms, opening a promising direction for learning human-like RL agents. Our code is available at https://rlg.iis.sinica.edu.tw/papers/MAQ.
Relevance-Zone Reduction in Game Solving
Oct 01, 2025Game solving aims to find the optimal strategies for all players and determine the theoretical outcome of a game. However, due to the exponential growth of game trees, many games remain unsolved, even though methods like AlphaZero have demonstrated super-human level in game playing. The Relevance-Zone (RZ) is a local strategy reuse technique that restricts the search to only the regions relevant to the outcome, significantly reducing the search space. However, RZs are not unique. Different solutions may result in RZs of varying sizes. Smaller RZs are generally more favorable, as they increase the chance of reuse and improve pruning efficiency. To this end, we propose an iterative RZ reduction method that repeatedly solves the same position while gradually restricting the region involved, guiding the solver toward smaller RZs. We design three constraint generation strategies and integrate an RZ Pattern Table to fully leverage past solutions. In experiments on 7x7 Killall-Go, our method reduces the average RZ size to 85.95% of the original. Furthermore, the reduced RZs can be permanently stored as reusable knowledge for future solving tasks, especially for larger board sizes or different openings.
Dynamic Sight Range Selection in Multi-Agent Reinforcement Learning
May 19, 2025Multi-agent reinforcement Learning (MARL) is often challenged by the sight range dilemma, where agents either receive insufficient or excessive information from their environment. In this paper, we propose a novel method, called Dynamic Sight Range Selection (DSR), to address this issue. DSR utilizes an Upper Confidence Bound (UCB) algorithm and dynamically adjusts the sight range during training. Experiment results show several advantages of using DSR. First, we demonstrate using DSR achieves better performance in three common MARL environments, including Level-Based Foraging (LBF), Multi-Robot Warehouse (RWARE), and StarCraft Multi-Agent Challenge (SMAC). Second, our results show that DSR consistently improves performance across multiple MARL algorithms, including QMIX and MAPPO. Third, DSR offers suitable sight ranges for different training steps, thereby accelerating the training process. Finally, DSR provides additional interpretability by indicating the optimal sight range used during training. Unlike existing methods that rely on global information or communication mechanisms, our approach operates solely based on the individual sight ranges of agents. This approach offers a practical and efficient solution to the sight range dilemma, making it broadly applicable to real-world complex environments.
Online Learning of Counter Categories and Ratings in PvP Games
Feb 06, 2025



In competitive games, strength ratings like Elo are widely used to quantify player skill and support matchmaking by accounting for skill disparities better than simple win rate statistics. However, scalar ratings cannot handle complex intransitive relationships, such as counter strategies seen in Rock-Paper-Scissors. To address this, recent work introduced Neural Rating Table and Neural Counter Table, which combine scalar ratings with discrete counter categories to model intransitivity. While effective, these methods rely on neural network training and cannot perform real-time updates. In this paper, we propose an online update algorithm that extends Elo principles to incorporate real-time learning of counter categories. Our method dynamically adjusts both ratings and counter relationships after each match, preserving the explainability of scalar ratings while addressing intransitivity. Experiments on zero-sum competitive games demonstrate its practicality, particularly in scenarios without complex team compositions.
Solving 7x7 Killall-Go with Seki Database
Nov 08, 2024


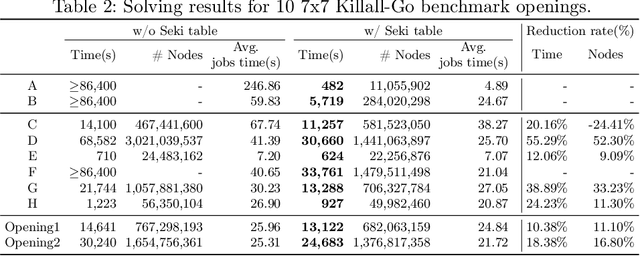
Game solving is the process of finding the theoretical outcome for a game, assuming that all player choices are optimal. This paper focuses on a technique that can reduce the heuristic search space significantly for 7x7 Killall-Go. In Go and Killall-Go, live patterns are stones that are protected from opponent capture. Mutual life, also referred to as seki, is when both players' stones achieve life by sharing liberties with their opponent. Whichever player attempts to capture the opponent first will leave their own stones vulnerable. Therefore, it is critical to recognize seki patterns to avoid putting oneself in jeopardy. Recognizing seki can reduce the search depth significantly. In this paper, we enumerate all seki patterns up to a predetermined area size, then store these patterns into a seki table. This allows us to recognize seki during search, which significantly improves solving efficiency for the game of Killall-Go. Experiments show that a day-long, unsolvable position can be solved in 482 seconds with the addition of a seki table. For general positions, a 10% to 20% improvement in wall clock time and node count is observed.
ResTNet: Defense against Adversarial Policies via Transformer in Computer Go
Oct 07, 2024Although AlphaZero has achieved superhuman levels in Go, recent research has highlighted its vulnerability in particular situations requiring a more comprehensive understanding of the entire board. To address this challenge, this paper introduces ResTNet, a network that interleaves residual networks and Transformer. Our empirical experiments demonstrate several advantages of using ResTNet. First, it not only improves playing strength but also enhances the ability of global information. Second, it defends against an adversary Go program, called cyclic-adversary, tailor-made for attacking AlphaZero algorithms, significantly reducing the average probability of being attacked rate from 70.44% to 23.91%. Third, it improves the accuracy from 59.15% to 80.01% in correctly recognizing ladder patterns, which are one of the challenging patterns for Go AIs. Finally, ResTNet offers a potential explanation of the decision-making process and can also be applied to other games like Hex. To the best of our knowledge, ResTNet is the first to integrate residual networks and Transformer in the context of AlphaZero for board games, suggesting a promising direction for enhancing AlphaZero's global understanding.
Identifying and Clustering Counter Relationships of Team Compositions in PvP Games for Efficient Balance Analysis
Aug 30, 2024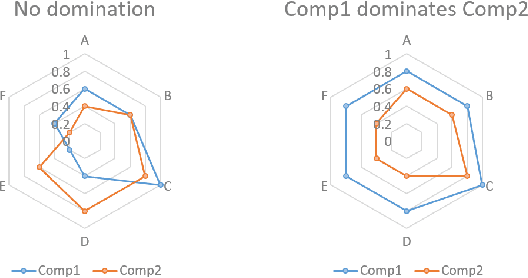
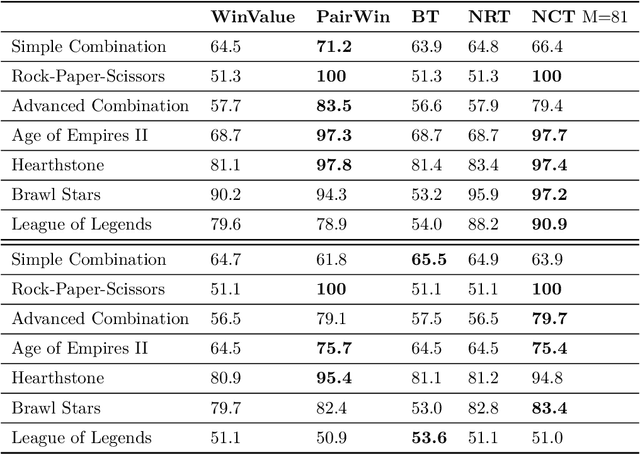
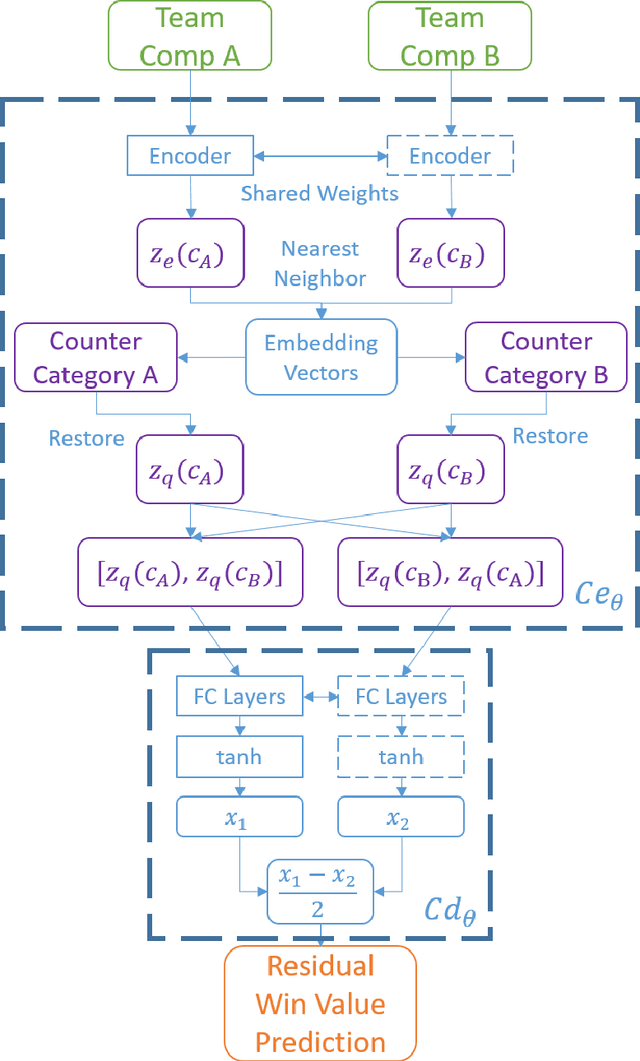
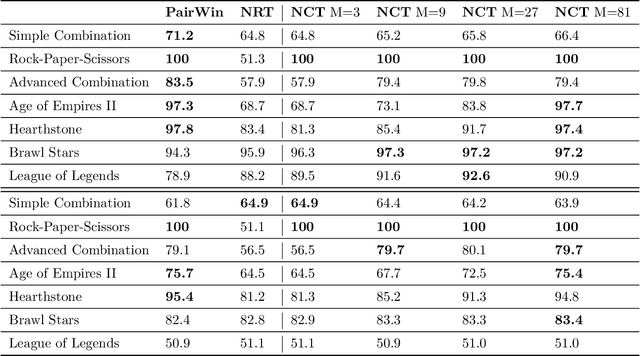
How can balance be quantified in game settings? This question is crucial for game designers, especially in player-versus-player (PvP) games, where analyzing the strength relations among predefined team compositions-such as hero combinations in multiplayer online battle arena (MOBA) games or decks in card games-is essential for enhancing gameplay and achieving balance. We have developed two advanced measures that extend beyond the simplistic win rate to quantify balance in zero-sum competitive scenarios. These measures are derived from win value estimations, which employ strength rating approximations via the Bradley-Terry model and counter relationship approximations via vector quantization, significantly reducing the computational complexity associated with traditional win value estimations. Throughout the learning process of these models, we identify useful categories of compositions and pinpoint their counter relationships, aligning with the experiences of human players without requiring specific game knowledge. Our methodology hinges on a simple technique to enhance codebook utilization in discrete representation with a deterministic vector quantization process for an extremely small state space. Our framework has been validated in popular online games, including Age of Empires II, Hearthstone, Brawl Stars, and League of Legends. The accuracy of the observed strength relations in these games is comparable to traditional pairwise win value predictions, while also offering a more manageable complexity for analysis. Ultimately, our findings contribute to a deeper understanding of PvP game dynamics and present a methodology that significantly improves game balance evaluation and design.
Perceptual Similarity for Measuring Decision-Making Style and Policy Diversity in Games
Aug 12, 2024Defining and measuring decision-making styles, also known as playstyles, is crucial in gaming, where these styles reflect a broad spectrum of individuality and diversity. However, finding a universally applicable measure for these styles poses a challenge. Building on Playstyle Distance, the first unsupervised metric to measure playstyle similarity based on game screens and raw actions, we introduce three enhancements to increase accuracy: multiscale analysis with varied state granularity, a perceptual kernel rooted in psychology, and the utilization of the intersection-over-union method for efficient evaluation. These innovations not only advance measurement precision but also offer insights into human cognition of similarity. Across two racing games and seven Atari games, our techniques significantly improve the precision of zero-shot playstyle classification, achieving an accuracy exceeding 90 percent with fewer than 512 observation-action pairs, which is less than half an episode of these games. Furthermore, our experiments with 2048 and Go demonstrate the potential of discrete playstyle measures in puzzle and board games. We also develop an algorithm for assessing decision-making diversity using these measures. Our findings improve the measurement of end-to-end game analysis and the evolution of artificial intelligence for diverse playstyles.
Gradient-based Regularization for Action Smoothness in Robotic Control with Reinforcement Learning
Jul 05, 2024

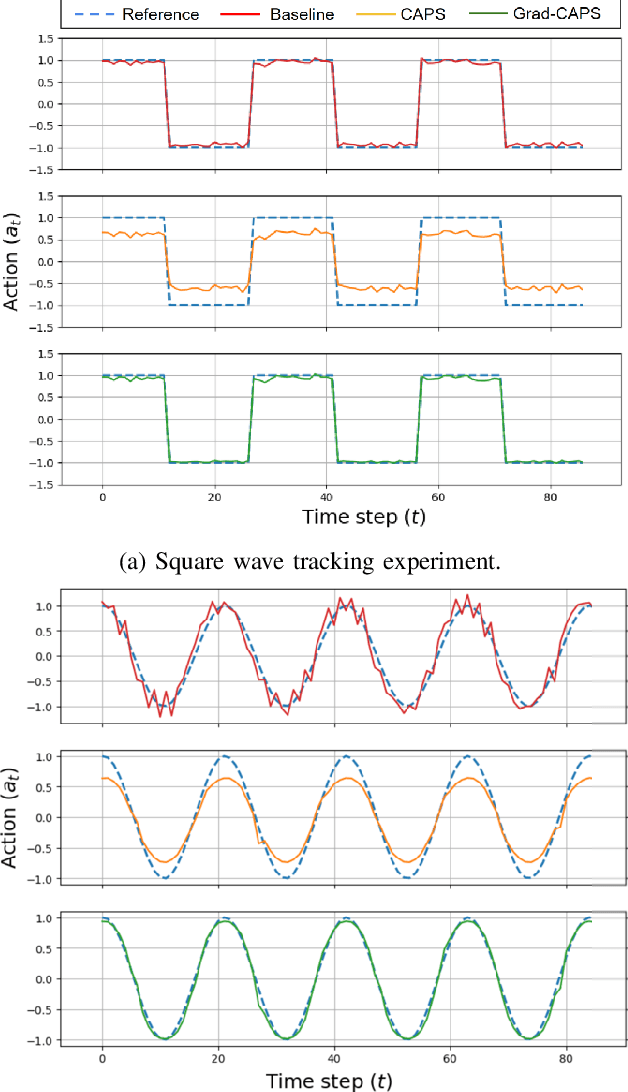
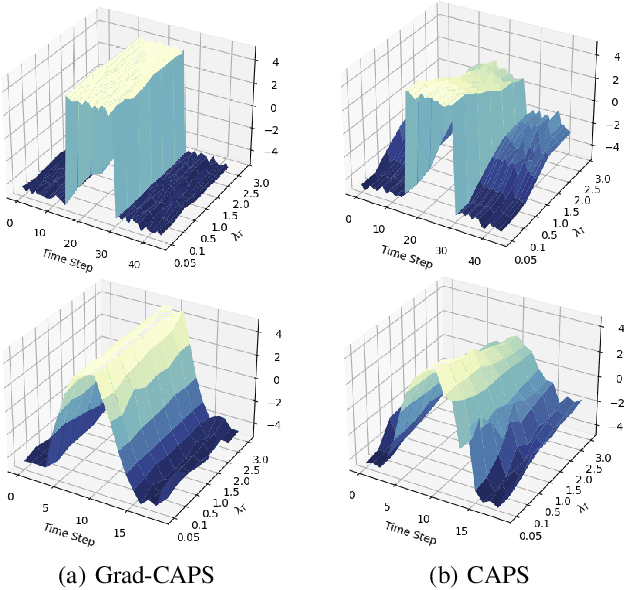
Deep Reinforcement Learning (DRL) has achieved remarkable success, ranging from complex computer games to real-world applications, showing the potential for intelligent agents capable of learning in dynamic environments. However, its application in real-world scenarios presents challenges, including the jerky problem, in which jerky trajectories not only compromise system safety but also increase power consumption and shorten the service life of robotic and autonomous systems. To address jerky actions, a method called conditioning for action policy smoothness (CAPS) was proposed by adding regularization terms to reduce the action changes. This paper further proposes a novel method, named Gradient-based CAPS (Grad-CAPS), that modifies CAPS by reducing the difference in the gradient of action and then uses displacement normalization to enable the agent to adapt to invariant action scales. Consequently, our method effectively reduces zigzagging action sequences while enhancing policy expressiveness and the adaptability of our method across diverse scenarios and environments. In the experiments, we integrated Grad-CAPS with different reinforcement learning algorithms and evaluated its performance on various robotic-related tasks in DeepMind Control Suite and OpenAI Gym environments. The results demonstrate that Grad-CAPS effectively improves performance while maintaining a comparable level of smoothness compared to CAPS and Vanilla agents.