 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDGAMES: A Live Arena for Evaluating Social and Strategic Reasoning in Multi-Agent LLMs
May 28, 2026Large language models (LLMs) are increasingly deployed as interactive agents, yet their capacity for social and strategic reasoning over extended interaction remains poorly understood. Existing evaluations rely on static vignettes or single-game benchmarks that cannot capture the sustained, multi-faceted reasoning that real-world multi-agent settings demand. We introduce Mindgames, a multi-game arena and evaluation platform for LLM agents that operationalizes complementary reasoning demands relevant to ``theory of mind'': belief attribution under hidden information, opponent modeling through repeated strategic interaction, cooperative inference under knowledge asymmetries, and sustained deception in social deduction. Built on TextArena, Mindgames provides a unified interaction interface, TrueSkill-based rating, and full trajectory logging across four game environments. We instantiate Mindgames through a 2025 competition cycle hosted at a major AI conference, which assessed 944 submitted agents from 76 teams across four games: Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, and Secret Mafia. Our analysis surfaces both agent-level and evaluation-level limitations: brittle rule adherence remains a major bottleneck, top-performing systems repeatedly rely on explicit structural scaffolding, and leaderboard validity differs sharply across environments. In particular, failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound in this cycle. We release a dataset of 29,571 multi-agent games with turn-level observations, actions, and rewards, together with MG-Ref, a deterministic offline tournament protocol that scores new agents against a frozen reference pool of top-ranked, low-error Stage~II submissions under the same error-attribution lens used in this analysis.
MAPLE: Multi-State Aggregated Policy Evaluation for AlphaZero in Imperfect-Information Games
May 22, 2026Imperfect-information games (IIGs) are challenging, as players must make decisions without fully observing the true game state. While AlphaZero has achieved remarkable success in perfect-information games, extending it to IIGs remains difficult. Existing search-based approaches, such as Perfect Information Monte Carlo (PIMC), suffer from strategy fusion, while Information Set Monte Carlo Tree Search (IS-MCTS) incurs high computational cost when combined with neural networks. In this paper, we propose Multi-State Aggregated PoLicy Evaluation (MAPLE), a tree search method that aggregates policy and value evaluations from multiple sampled world states within a single search tree, combining the advantages of PIMC and IS-MCTS while maintaining a controllable computational cost. We further incorporate a Siamese-based sampling strategy to select informative world states from the information set. Experiments on Phantom Go and Dark Hex show that MAPLE significantly outperforms the PIMC-based AlphaZero baseline, achieving Elo improvements of 291 and 136, respectively. These results demonstrate that MAPLE is an effective approach for AlphaZero-style learning in imperfect-information games.
Evaluating Game Difficulty in Tetris Block Puzzle
Mar 19, 2026Tetris Block Puzzle is a single player stochastic puzzle in which a player places blocks on an 8 x 8 grid to complete lines; its popular variants have amassed tens of millions of downloads. Despite this reach, there is little principled assessment of which rule sets are more difficult. Inspired by prior work that uses AlphaZero as a strong evaluator for chess variants, we study difficulty in this domain using Stochastic Gumbel AlphaZero (SGAZ), a budget-aware planning agent for stochastic environments. We evaluate rule changes including holding block h, preview holding block p, and additional Tetris block variants using metrics such as training reward and convergence iterations. Empirically, increasing h and p reduces difficulty (higher reward and faster convergence), while adding more Tetris block variants increases difficulty, with the T-pentomino producing the largest slowdown. Through analysis, SGAZ delivers strong play under small simulation budgets, enabling efficient, reproducible comparisons across rule sets and providing a reference for future design in stochastic puzzle games.
Regret-Guided Search Control for Efficient Learning in AlphaZero
Feb 24, 2026Reinforcement learning (RL) agents achieve remarkable performance but remain far less learning-efficient than humans. While RL agents require extensive self-play games to extract useful signals, humans often need only a few games, improving rapidly by repeatedly revisiting states where mistakes occurred. This idea, known as search control, aims to restart from valuable states rather than always from the initial state. In AlphaZero, prior work Go-Exploit applies this idea by sampling past states from self-play or search trees, but it treats all states equally, regardless of their learning potential. We propose Regret-Guided Search Control (RGSC), which extends AlphaZero with a regret network that learns to identify high-regret states, where the agent's evaluation diverges most from the actual outcome. These states are collected from both self-play trajectories and MCTS nodes, stored in a prioritized regret buffer, and reused as new starting positions. Across 9x9 Go, 10x10 Othello, and 11x11 Hex, RGSC outperforms AlphaZero and Go-Exploit by an average of 77 and 89 Elo, respectively. When training on a well-trained 9x9 Go model, RGSC further improves the win rate against KataGo from 69.3% to 78.2%, while both baselines show no improvement. These results demonstrate that RGSC provides an effective mechanism for search control, improving both efficiency and robustness of AlphaZero training. Our code is available at https://rlg.iis.sinica.edu.tw/papers/rgsc.
A Study of Solving Life-and-Death Problems in Go Using Relevance-Zone Based Solvers
Dec 23, 2025This paper analyzes the behavior of solving Life-and-Death (L&D) problems in the game of Go using current state-of-the-art computer Go solvers with two techniques: the Relevance-Zone Based Search (RZS) and the relevance-zone pattern table. We examined the solutions derived by relevance-zone based solvers on seven L&D problems from the renowned book "Life and Death Dictionary" written by Cho Chikun, a Go grandmaster, and found several interesting results. First, for each problem, the solvers identify a relevance-zone that highlights the critical areas for solving. Second, the solvers discover a series of patterns, including some that are rare. Finally, the solvers even find different answers compared to the given solutions for two problems. We also identified two issues with the solver: (a) it misjudges values of rare patterns, and (b) it tends to prioritize living directly rather than maximizing territory, which differs from the behavior of human Go players. We suggest possible approaches to address these issues in future work. Our code and data are available at https://rlg.iis.sinica.edu.tw/papers/study-LD-RZ.
Learning Human-Like RL Agents Through Trajectory Optimization With Action Quantization
Nov 19, 2025Human-like agents have long been one of the goals in pursuing artificial intelligence. Although reinforcement learning (RL) has achieved superhuman performance in many domains, relatively little attention has been focused on designing human-like RL agents. As a result, many reward-driven RL agents often exhibit unnatural behaviors compared to humans, raising concerns for both interpretability and trustworthiness. To achieve human-like behavior in RL, this paper first formulates human-likeness as trajectory optimization, where the objective is to find an action sequence that closely aligns with human behavior while also maximizing rewards, and adapts the classic receding-horizon control to human-like learning as a tractable and efficient implementation. To achieve this, we introduce Macro Action Quantization (MAQ), a human-like RL framework that distills human demonstrations into macro actions via Vector-Quantized VAE. Experiments on D4RL Adroit benchmarks show that MAQ significantly improves human-likeness, increasing trajectory similarity scores, and achieving the highest human-likeness rankings among all RL agents in the human evaluation study. Our results also demonstrate that MAQ can be easily integrated into various off-the-shelf RL algorithms, opening a promising direction for learning human-like RL agents. Our code is available at https://rlg.iis.sinica.edu.tw/papers/MAQ.
Relevance-Zone Reduction in Game Solving
Oct 01, 2025Game solving aims to find the optimal strategies for all players and determine the theoretical outcome of a game. However, due to the exponential growth of game trees, many games remain unsolved, even though methods like AlphaZero have demonstrated super-human level in game playing. The Relevance-Zone (RZ) is a local strategy reuse technique that restricts the search to only the regions relevant to the outcome, significantly reducing the search space. However, RZs are not unique. Different solutions may result in RZs of varying sizes. Smaller RZs are generally more favorable, as they increase the chance of reuse and improve pruning efficiency. To this end, we propose an iterative RZ reduction method that repeatedly solves the same position while gradually restricting the region involved, guiding the solver toward smaller RZs. We design three constraint generation strategies and integrate an RZ Pattern Table to fully leverage past solutions. In experiments on 7x7 Killall-Go, our method reduces the average RZ size to 85.95% of the original. Furthermore, the reduced RZs can be permanently stored as reusable knowledge for future solving tasks, especially for larger board sizes or different openings.
Dynamic Sight Range Selection in Multi-Agent Reinforcement Learning
May 19, 2025Multi-agent reinforcement Learning (MARL) is often challenged by the sight range dilemma, where agents either receive insufficient or excessive information from their environment. In this paper, we propose a novel method, called Dynamic Sight Range Selection (DSR), to address this issue. DSR utilizes an Upper Confidence Bound (UCB) algorithm and dynamically adjusts the sight range during training. Experiment results show several advantages of using DSR. First, we demonstrate using DSR achieves better performance in three common MARL environments, including Level-Based Foraging (LBF), Multi-Robot Warehouse (RWARE), and StarCraft Multi-Agent Challenge (SMAC). Second, our results show that DSR consistently improves performance across multiple MARL algorithms, including QMIX and MAPPO. Third, DSR offers suitable sight ranges for different training steps, thereby accelerating the training process. Finally, DSR provides additional interpretability by indicating the optimal sight range used during training. Unlike existing methods that rely on global information or communication mechanisms, our approach operates solely based on the individual sight ranges of agents. This approach offers a practical and efficient solution to the sight range dilemma, making it broadly applicable to real-world complex environments.
Strength Estimation and Human-Like Strength Adjustment in Games
Feb 24, 2025Strength estimation and adjustment are crucial in designing human-AI interactions, particularly in games where AI surpasses human players. This paper introduces a novel strength system, including a strength estimator (SE) and an SE-based Monte Carlo tree search, denoted as SE-MCTS, which predicts strengths from games and offers different playing strengths with human styles. The strength estimator calculates strength scores and predicts ranks from games without direct human interaction. SE-MCTS utilizes the strength scores in a Monte Carlo tree search to adjust playing strength and style. We first conduct experiments in Go, a challenging board game with a wide range of ranks. Our strength estimator significantly achieves over 80% accuracy in predicting ranks by observing 15 games only, whereas the previous method reached 49% accuracy for 100 games. For strength adjustment, SE-MCTS successfully adjusts to designated ranks while achieving a 51.33% accuracy in aligning to human actions, outperforming a previous state-of-the-art, with only 42.56% accuracy. To demonstrate the generality of our strength system, we further apply SE and SE-MCTS to chess and obtain consistent results. These results show a promising approach to strength estimation and adjustment, enhancing human-AI interactions in games. Our code is available at https://rlg.iis.sinica.edu.tw/papers/strength-estimator.
OptionZero: Planning with Learned Options
Feb 23, 2025

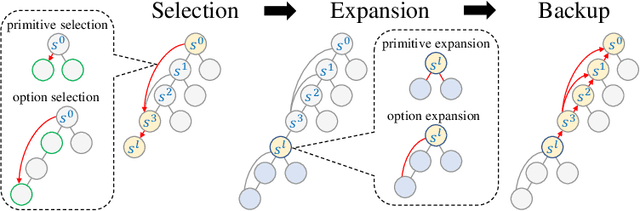

Planning with options -- a sequence of primitive actions -- has been shown effective in reinforcement learning within complex environments. Previous studies have focused on planning with predefined options or learned options through expert demonstration data. Inspired by MuZero, which learns superhuman heuristics without any human knowledge, we propose a novel approach, named OptionZero. OptionZero incorporates an option network into MuZero, providing autonomous discovery of options through self-play games. Furthermore, we modify the dynamics network to provide environment transitions when using options, allowing searching deeper under the same simulation constraints. Empirical experiments conducted in 26 Atari games demonstrate that OptionZero outperforms MuZero, achieving a 131.58% improvement in mean human-normalized score. Our behavior analysis shows that OptionZero not only learns options but also acquires strategic skills tailored to different game characteristics. Our findings show promising directions for discovering and using options in planning. Our code is available at https://rlg.iis.sinica.edu.tw/papers/optionzero.