 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human-Like RL Agents Through Trajectory Optimization With Action Quantization
Nov 19, 2025Human-like agents have long been one of the goals in pursuing artificial intelligence. Although reinforcement learning (RL) has achieved superhuman performance in many domains, relatively little attention has been focused on designing human-like RL agents. As a result, many reward-driven RL agents often exhibit unnatural behaviors compared to humans, raising concerns for both interpretability and trustworthiness. To achieve human-like behavior in RL, this paper first formulates human-likeness as trajectory optimization, where the objective is to find an action sequence that closely aligns with human behavior while also maximizing rewards, and adapts the classic receding-horizon control to human-like learning as a tractable and efficient implementation. To achieve this, we introduce Macro Action Quantization (MAQ), a human-like RL framework that distills human demonstrations into macro actions via Vector-Quantized VAE. Experiments on D4RL Adroit benchmarks show that MAQ significantly improves human-likeness, increasing trajectory similarity scores, and achieving the highest human-likeness rankings among all RL agents in the human evaluation study. Our results also demonstrate that MAQ can be easily integrated into various off-the-shelf RL algorithms, opening a promising direction for learning human-like RL agents. Our code is available at https://rlg.iis.sinica.edu.tw/papers/MAQ.
Accelerating Inference for Multilayer Neural Networks with Quantum Computers
Oct 08, 2025



Fault-tolerant Quantum Processing Units (QPUs) promise to deliver exponential speed-ups in select computational tasks, yet their integration into modern deep learning pipelines remains unclear. In this work, we take a step towards bridging this gap by presenting the first fully-coherent quantum implementation of a multilayer neural network with non-linear activation functions. Our constructions mirror widely used deep learning architectures based on ResNet, and consist of residual blocks with multi-filter 2D convolutions, sigmoid activations, skip-connections, and layer normalizations. We analyse the complexity of inference for networks under three quantum data access regimes. Without any assumptions, we establish a quadratic speedup over classical methods for shallow bilinear-style networks. With efficient quantum access to the weights, we obtain a quartic speedup over classical methods. With efficient quantum access to both the inputs and the network weights, we prove that a network with an $N$-dimensional vectorized input, $k$ residual block layers, and a final residual-linear-pooling layer can be implemented with an error of $\epsilon$ with $O(\text{polylog}(N/\epsilon)^k)$ inference cost.
OptionZero: Planning with Learned Options
Feb 23, 2025

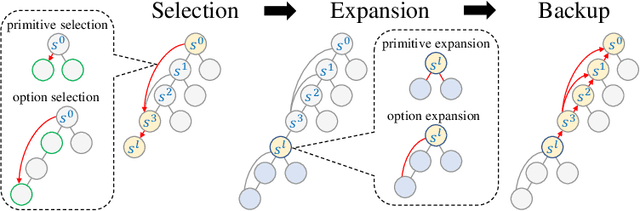

Planning with options -- a sequence of primitive actions -- has been shown effective in reinforcement learning within complex environments. Previous studies have focused on planning with predefined options or learned options through expert demonstration data. Inspired by MuZero, which learns superhuman heuristics without any human knowledge, we propose a novel approach, named OptionZero. OptionZero incorporates an option network into MuZero, providing autonomous discovery of options through self-play games. Furthermore, we modify the dynamics network to provide environment transitions when using options, allowing searching deeper under the same simulation constraints. Empirical experiments conducted in 26 Atari games demonstrate that OptionZero outperforms MuZero, achieving a 131.58% improvement in mean human-normalized score. Our behavior analysis shows that OptionZero not only learns options but also acquires strategic skills tailored to different game characteristics. Our findings show promising directions for discovering and using options in planning. Our code is available at https://rlg.iis.sinica.edu.tw/papers/optionzero.
Concept learning of parameterized quantum models from limited measurements
Aug 09, 2024Classical learning of the expectation values of observables for quantum states is a natural variant of learning quantum states or channels. While learning-theoretic frameworks establish the sample complexity and the number of measurement shots per sample required for learning such statistical quantities, the interplay between these two variables has not been adequately quantified before. In this work, we take the probabilistic nature of quantum measurements into account in classical modelling and discuss these quantities under a single unified learning framework. We provide provable guarantees for learning parameterized quantum models that also quantify the asymmetrical effects and interplay of the two variables on the performance of learning algorithms. These results show that while increasing the sample size enhances the learning performance of classical machines, even with single-shot estimates, the improvements from increasing measurements become asymptotically trivial beyond a constant factor. We further apply our framework and theoretical guarantees to study the impact of measurement noise on the classical surrogation of parameterized quantum circuit models. Our work provides new tools to analyse the operational influence of finite measurement noise in the classical learning of quantum systems.
MiniZero: Comparative Analysis of AlphaZero and MuZero on Go, Othello, and Atari Games
Oct 17, 2023



This paper presents MiniZero, a zero-knowledge learning framework that supports four state-of-the-art algorithms, including AlphaZero, MuZero, Gumbel AlphaZero, and Gumbel MuZero. While these algorithms have demonstrated super-human performance in many games, it remains unclear which among them is most suitable or efficient for specific tasks. Through MiniZero, we systematically evaluate the performance of each algorithm in two board games, 9x9 Go and 8x8 Othello, as well as 57 Atari games. Our empirical findings are summarized as follows. For two board games, using more simulations generally results in higher performance. However, the choice of AlphaZero and MuZero may differ based on game properties. For Atari games, both MuZero and Gumbel MuZero are worth considering. Since each game has unique characteristics, different algorithms and simulations yield varying results. In addition, we introduce an approach, called progressive simulation, which progressively increases the simulation budget during training to allocate computation more efficiently. Our empirical results demonstrate that progressive simulation achieves significantly superior performance in two board games. By making our framework and trained models publicly available, this paper contributes a benchmark for future research on zero-knowledge learning algorithms, assisting researchers in algorithm selection and comparison against these zero-knowledge learning baselines.
Post-variational quantum neural networks
Jul 20, 2023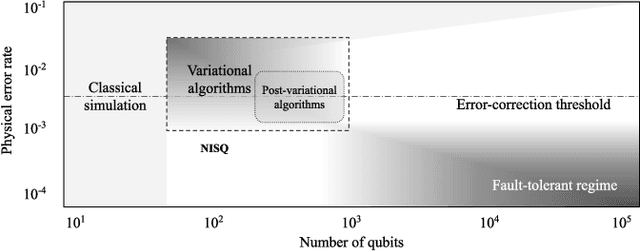



Quantum computing has the potential to provide substantial computational advantages over current state-of-the-art classical supercomputers. However, current hardware is not advanced enough to execute fault-tolerant quantum algorithms. An alternative of using hybrid quantum-classical computing with variational algorithms can exhibit barren plateau issues, causing slow convergence of gradient-based optimization techniques. In this paper, we discuss "post-variational strategies", which shift tunable parameters from the quantum computer to the classical computer, opting for ensemble strategies when optimizing quantum models. We discuss various strategies and design principles for constructing individual quantum circuits, where the resulting ensembles can be optimized with convex programming. Further, we discuss architectural designs of post-variational quantum neural networks and analyze the propagation of estimation errors throughout such neural networks. Lastly, we show that our algorithm can be applied to real-world applications such as image classification on handwritten digits, producing a 96% classification accuracy.