 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptionZero: Planning with Learned Options
Feb 23, 2025

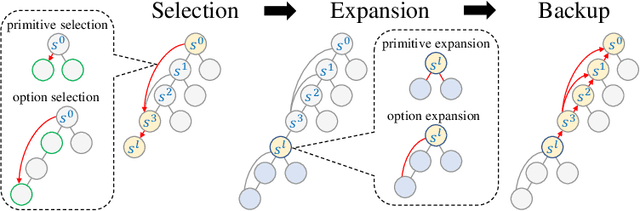

Planning with options -- a sequence of primitive actions -- has been shown effective in reinforcement learning within complex environments. Previous studies have focused on planning with predefined options or learned options through expert demonstration data. Inspired by MuZero, which learns superhuman heuristics without any human knowledge, we propose a novel approach, named OptionZero. OptionZero incorporates an option network into MuZero, providing autonomous discovery of options through self-play games. Furthermore, we modify the dynamics network to provide environment transitions when using options, allowing searching deeper under the same simulation constraints. Empirical experiments conducted in 26 Atari games demonstrate that OptionZero outperforms MuZero, achieving a 131.58% improvement in mean human-normalized score. Our behavior analysis shows that OptionZero not only learns options but also acquires strategic skills tailored to different game characteristics. Our findings show promising directions for discovering and using options in planning. Our code is available at https://rlg.iis.sinica.edu.tw/papers/optionzero.
MiniZero: Comparative Analysis of AlphaZero and MuZero on Go, Othello, and Atari Games
Oct 17, 2023



This paper presents MiniZero, a zero-knowledge learning framework that supports four state-of-the-art algorithms, including AlphaZero, MuZero, Gumbel AlphaZero, and Gumbel MuZero. While these algorithms have demonstrated super-human performance in many games, it remains unclear which among them is most suitable or efficient for specific tasks. Through MiniZero, we systematically evaluate the performance of each algorithm in two board games, 9x9 Go and 8x8 Othello, as well as 57 Atari games. Our empirical findings are summarized as follows. For two board games, using more simulations generally results in higher performance. However, the choice of AlphaZero and MuZero may differ based on game properties. For Atari games, both MuZero and Gumbel MuZero are worth considering. Since each game has unique characteristics, different algorithms and simulations yield varying results. In addition, we introduce an approach, called progressive simulation, which progressively increases the simulation budget during training to allocate computation more efficiently. Our empirical results demonstrate that progressive simulation achieves significantly superior performance in two board games. By making our framework and trained models publicly available, this paper contributes a benchmark for future research on zero-knowledge learning algorithms, assisting researchers in algorithm selection and comparison against these zero-knowledge learning baselines.