 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Expert Failures Improves LLM Agent Tuning
Apr 18, 2025Large Language Models (LLMs) have shown tremendous potential as agents, excelling at tasks that require multiple rounds of reasoning and interactions. Rejection Sampling Fine-Tuning (RFT) has emerged as an effective method for finetuning LLMs as agents: it first imitates expert-generated successful trajectories and further improves agentic skills through iterative fine-tuning on successful, self-generated trajectories. However, since the expert (e.g., GPT-4) succeeds primarily on simpler subtasks and RFT inherently favors simpler scenarios, many complex subtasks remain unsolved and persistently out-of-distribution (OOD). Upon investigating these challenging subtasks, we discovered that previously failed expert trajectories can often provide valuable guidance, e.g., plans and key actions, that can significantly improve agent exploration efficiency and acquisition of critical skills. Motivated by these observations, we propose Exploring Expert Failures (EEF), which identifies beneficial actions from failed expert trajectories and integrates them into the training dataset. Potentially harmful actions are meticulously excluded to prevent contamination of the model learning process. By leveraging the beneficial actions in expert failures, EEF successfully solves some previously unsolvable subtasks and improves agent tuning performance. Remarkably, our approach achieved a 62\% win rate in WebShop, outperforming RFT (53. 6\%) and GPT-4 (35. 6\%), and to the best of our knowledge, setting a new state-of-the-art as the first method to surpass a score of 0.81 in WebShop and exceed 81 in SciWorld.
Expert Proximity as Surrogate Rewards for Single Demonstration Imitation Learning
Feb 01, 2024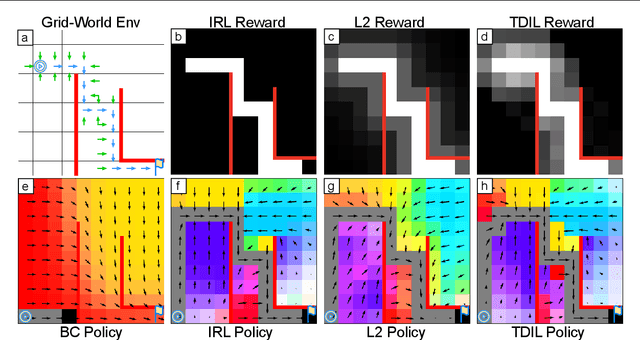
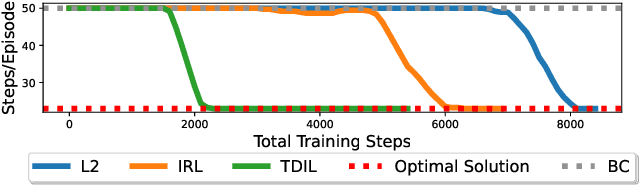
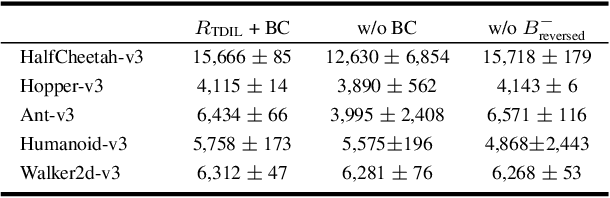
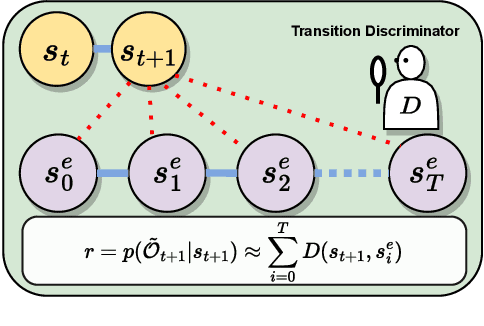
In this paper, we focus on single-demonstration imitation learning (IL), a practical approach for real-world applications where obtaining numerous expert demonstrations is costly or infeasible. In contrast to typical IL settings with multiple demonstrations, single-demonstration IL involves an agent having access to only one expert trajectory. We highlight the issue of sparse reward signals in this setting and propose to mitigate this issue through our proposed Transition Discriminator-based IL (TDIL) method. TDIL is an IRL method designed to address reward sparsity by introducing a denser surrogate reward function that considers environmental dynamics. This surrogate reward function encourages the agent to navigate towards states that are proximal to expert states. In practice, TDIL trains a transition discriminator to differentiate between valid and non-valid transitions in a given environment to compute the surrogate rewards. The experiments demonstrate that TDIL outperforms existing IL approaches and achieves expert-level performance in the single-demonstration IL setting across five widely adopted MuJoCo benchmarks as well as the "Adroit Door" environment.
Can Agents Run Relay Race with Strangers? Generalization of RL to Out-of-Distribution Trajectories
Apr 26, 2023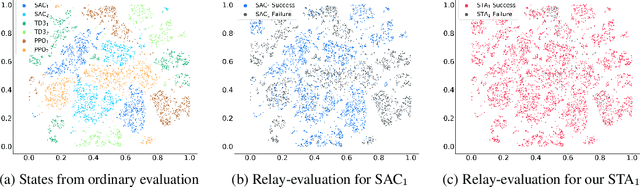



In this paper, we define, evaluate, and improve the ``relay-generalization'' performance of reinforcement learning (RL) agents on the out-of-distribution ``controllable'' states. Ideally, an RL agent that generally masters a task should reach its goal starting from any controllable state of the environment instead of memorizing a small set of trajectories. For example, a self-driving system should be able to take over the control from humans in the middle of driving and must continue to drive the car safely. To practically evaluate this type of generalization, we start the test agent from the middle of other independently well-trained \emph{stranger} agents' trajectories. With extensive experimental evaluation, we show the prevalence of \emph{generalization failure} on controllable states from stranger agents. For example, in the Humanoid environment, we observed that a well-trained Proximal Policy Optimization (PPO) agent, with only 3.9\% failure rate during regular testing, failed on 81.6\% of the states generated by well-trained stranger PPO agents. To improve "relay generalization," we propose a novel method called Self-Trajectory Augmentation (STA), which will reset the environment to the agent's old states according to the Q function during training. After applying STA to the Soft Actor Critic's (SAC) training procedure, we reduced the failure rate of SAC under relay-evaluation by more than three times in most settings without impacting agent performance and increasing the needed number of environment interactions. Our code is available at https://github.com/lan-lc/STA.
Are AlphaZero-like Agents Robust to Adversarial Perturbations?
Nov 07, 2022



The success of AlphaZero (AZ) has demonstrated that neural-network-based Go AIs can surpass human performance by a large margin. Given that the state space of Go is extremely large and a human player can play the game from any legal state, we ask whether adversarial states exist for Go AIs that may lead them to play surprisingly wrong actions. In this paper, we first extend the concept of adversarial examples to the game of Go: we generate perturbed states that are ``semantically'' equivalent to the original state by adding meaningless moves to the game, and an adversarial state is a perturbed state leading to an undoubtedly inferior action that is obvious even for Go beginners. However, searching the adversarial state is challenging due to the large, discrete, and non-differentiable search space. To tackle this challenge, we develop the first adversarial attack on Go AIs that can efficiently search for adversarial states by strategically reducing the search space. This method can also be extended to other board games such as NoGo. Experimentally, we show that the actions taken by both Policy-Value neural network (PV-NN) and Monte Carlo tree search (MCTS) can be misled by adding one or two meaningless stones; for example, on 58\% of the AlphaGo Zero self-play games, our method can make the widely used KataGo agent with 50 simulations of MCTS plays a losing action by adding two meaningless stones. We additionally evaluated the adversarial examples found by our algorithm with amateur human Go players and 90\% of examples indeed lead the Go agent to play an obviously inferior action. Our code is available at \url{https://PaperCode.cc/GoAttack}.
Learning to Stop: Dynamic Simulation Monte-Carlo Tree Search
Dec 14, 2020



Monte Carlo tree search (MCTS) has achieved state-of-the-art results in many domains such as Go and Atari games when combining with deep neural networks (DNNs). When more simulations are executed, MCTS can achieve higher performance but also requires enormous amounts of CPU and GPU resources. However, not all states require a long searching time to identify the best action that the agent can find. For example, in 19x19 Go and NoGo, we found that for more than half of the states, the best action predicted by DNN remains unchanged even after searching 2 minutes. This implies that a significant amount of resources can be saved if we are able to stop the searching earlier when we are confident with the current searching result. In this paper, we propose to achieve this goal by predicting the uncertainty of the current searching status and use the result to decide whether we should stop searching. With our algorithm, called Dynamic Simulation MCTS (DS-MCTS), we can speed up a NoGo agent trained by AlphaZero 2.5 times faster while maintaining a similar winning rate. Also, under the same average simulation count, our method can achieve a 61% winning rate against the original program.
How much progress have we made in neural network training? A New Evaluation Protocol for Benchmarking Optimizers
Oct 19, 2020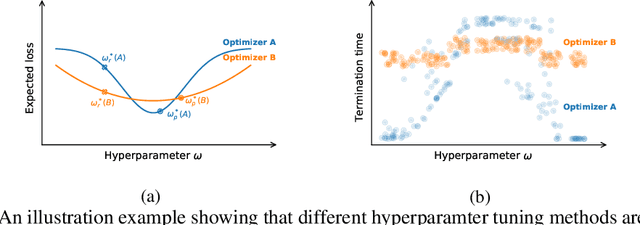

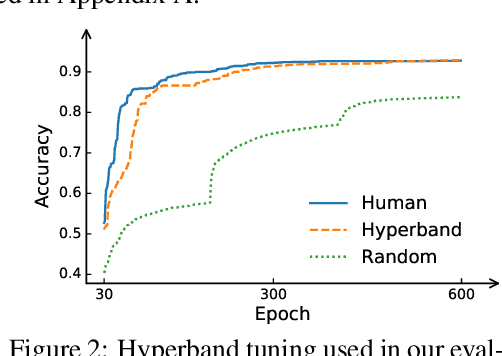
Many optimizers have been proposed for training deep neural networks, and they often have multiple hyperparameters, which make it tricky to benchmark their performance. In this work, we propose a new benchmarking protocol to evaluate both end-to-end efficiency (training a model from scratch without knowing the best hyperparameter) and data-addition training efficiency (the previously selected hyperparameters are used for periodically re-training the model with newly collected data). For end-to-end efficiency, unlike previous work that assumes random hyperparameter tuning, which over-emphasizes the tuning time, we propose to evaluate with a bandit hyperparameter tuning strategy. A human study is conducted to show that our evaluation protocol matches human tuning behavior better than the random search. For data-addition training, we propose a new protocol for assessing the hyperparameter sensitivity to data shift. We then apply the proposed benchmarking framework to 7 optimizers and various tasks, including computer vision, natural language processing, reinforcement learning, and graph mining. Our results show that there is no clear winner across all the tasks.
Multiple Policy Value Monte Carlo Tree Search
May 31, 2019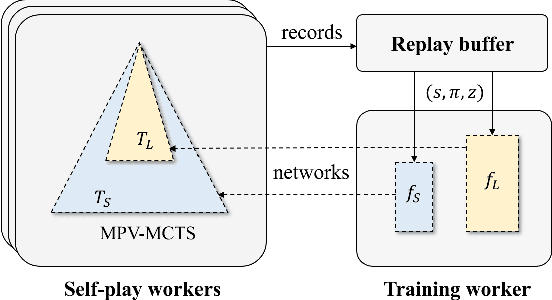
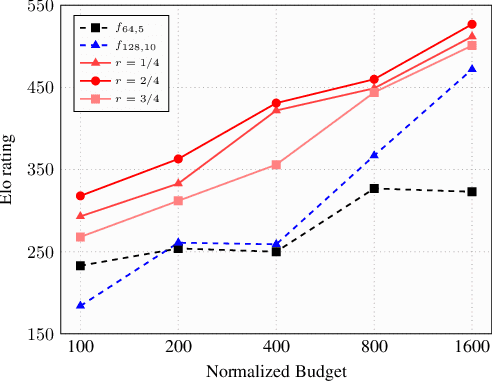
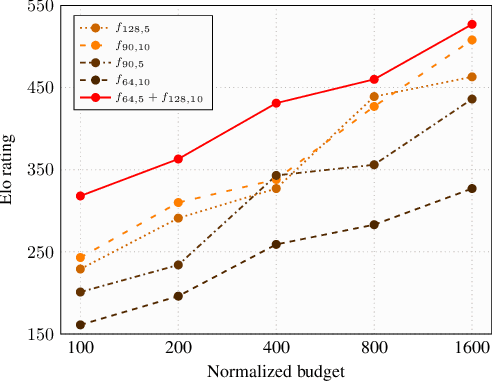
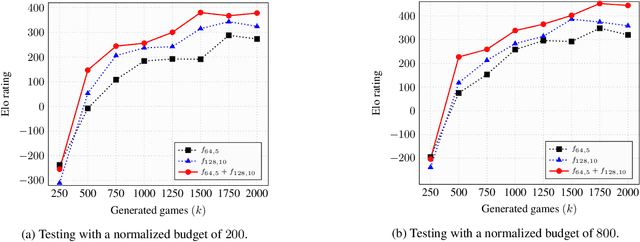
Many of the strongest game playing programs use a combination of Monte Carlo tree search (MCTS) and deep neural networks (DNN), where the DNNs are used as policy or value evaluators. Given a limited budget, such as online playing or during the self-play phase of AlphaZero (AZ) training, a balance needs to be reached between accurate state estimation and more MCTS simulations, both of which are critical for a strong game playing agent. Typically, larger DNNs are better at generalization and accurate evaluation, while smaller DNNs are less costly, and therefore can lead to more MCTS simulations and bigger search trees with the same budget. This paper introduces a new method called the multiple policy value MCTS (MPV-MCTS), which combines multiple policy value neural networks (PV-NNs) of various sizes to retain advantages of each network, where two PV-NNs f_S and f_L are used in this paper. We show through experiments on the game NoGo that a combined f_S and f_L MPV-MCTS outperforms single PV-NN with policy value MCTS, called PV-MCTS. Additionally, MPV-MCTS also outperforms PV-MCTS for AZ training.
Multi-Labelled Value Networks for Computer Go
May 30, 2017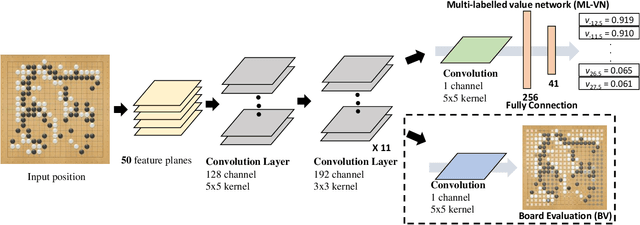
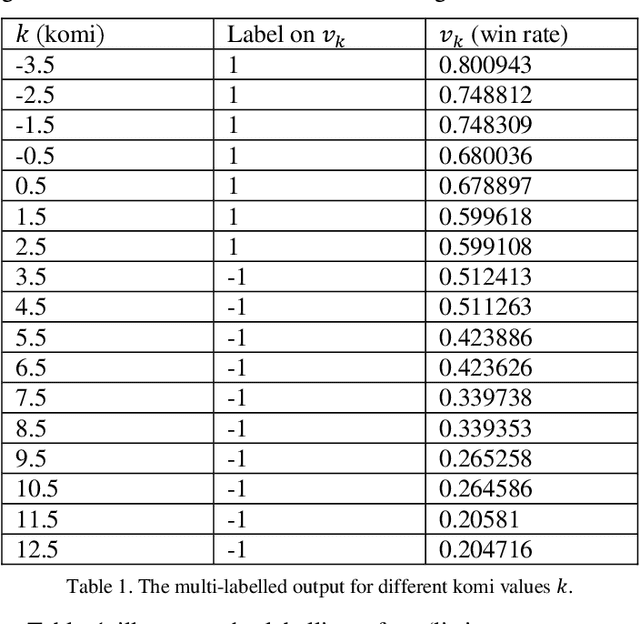

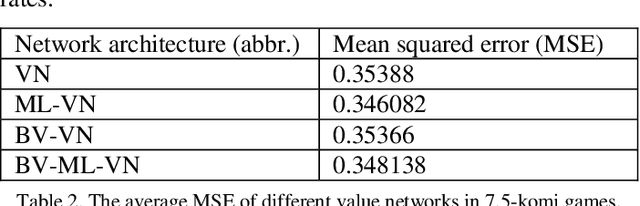
This paper proposes a new approach to a novel value network architecture for the game Go, called a multi-labelled (ML) value network. In the ML value network, different values (win rates) are trained simultaneously for different settings of komi, a compensation given to balance the initiative of playing first. The ML value network has three advantages, (a) it outputs values for different komi, (b) it supports dynamic komi, and (c) it lowers the mean squared error (MSE). This paper also proposes a new dynamic komi method to improve game-playing strength. This paper also performs experiments to demonstrate the merits of the architecture. First, the MSE of the ML value network is generally lower than the value network alone. Second, the program based on the ML value network wins by a rate of 67.6% against the program based on the value network alone. Third, the program with the proposed dynamic komi method significantly improves the playing strength over the baseline that does not use dynamic komi, especially for handicap games. To our knowledge, up to date, no handicap games have been played openly by programs using value networks. This paper provides these programs with a useful approach to playing handicap games.