 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
Scaling Agent Learning via Experience Synthesis
Nov 10, 2025



While reinforcement learning (RL) can empower autonomous agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
Ameliorate Spurious Correlations in Dataset Condensation
Jun 06, 2024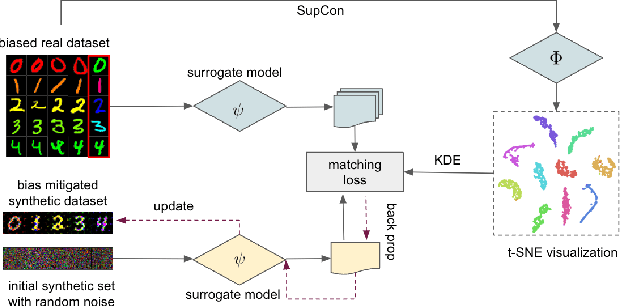
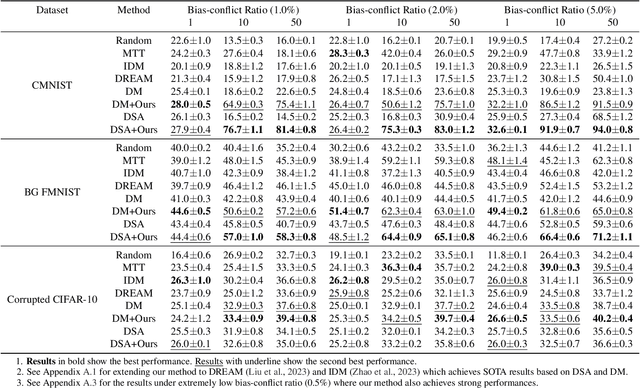


Dataset Condensation has emerged as a technique for compressing large datasets into smaller synthetic counterparts, facilitating downstream training tasks. In this paper, we study the impact of bias inside the original dataset on the performance of dataset condensation. With a comprehensive empirical evaluation on canonical datasets with color, corruption and background biases, we found that color and background biases in the original dataset will be amplified through the condensation process, resulting in a notable decline in the performance of models trained on the condensed dataset, while corruption bias is suppressed through the condensation process. To reduce bias amplification in dataset condensation, we introduce a simple yet highly effective approach based on a sample reweighting scheme utilizing kernel density estimation. Empirical results on multiple real-world and synthetic datasets demonstrate the effectiveness of the proposed method. Notably, on CMNIST with 5% bias-conflict ratio and IPC 50, our method achieves 91.5% test accuracy compared to 23.8% from vanilla DM, boosting the performance by 67.7%, whereas applying state-of-the-art debiasing method on the same dataset only achieves 53.7% accuracy. Our findings highlight the importance of addressing biases in dataset condensation and provide a promising avenue to address bias amplification in the process.
Spatiotemporally Discriminative Video-Language Pre-Training with Text Grounding
Mar 28, 2023



Most of existing video-language pre-training methods focus on instance-level alignment between video clips and captions via global contrastive learning but neglect rich fine-grained local information, which is of importance to downstream tasks requiring temporal localization and semantic reasoning. In this work, we propose a simple yet effective video-language pre-training framework, namely G-ViLM, to learn discriminative spatiotemporal features. Two novel designs involving spatiotemporal grounding and temporal grouping promote learning local region-noun alignment and temporal-aware features simultaneously. Specifically, spatiotemporal grounding aggregates semantically similar video tokens and aligns them with noun phrases extracted from the caption to promote local region-noun correspondences. Moreover, temporal grouping leverages cut-and-paste to manually create temporal scene changes and then learns distinguishable features from different scenes. Comprehensive evaluations demonstrate that G-ViLM performs favorably against existing approaches on four representative downstream tasks, covering text-video retrieval, video question answering, video action recognition and temporal action localization. G-ViLM performs competitively on all evaluated tasks and in particular achieves R@10 of 65.1 on zero-shot MSR-VTT retrieval, over 9% higher than the state-of-the-art method.
Efficient Non-Parametric Optimizer Search for Diverse Tasks
Sep 27, 2022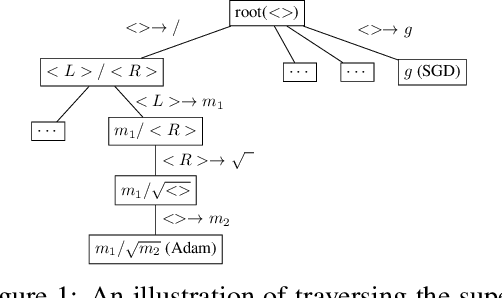
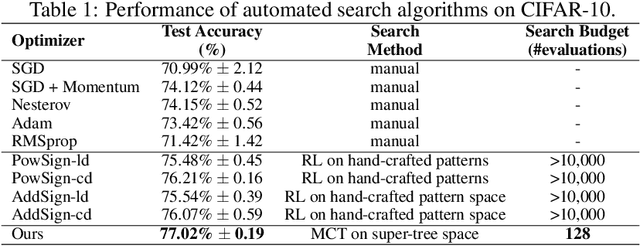
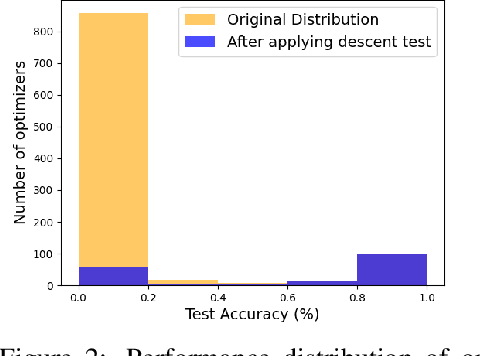
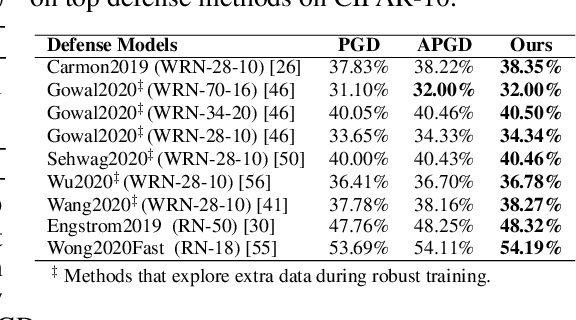
Efficient and automated design of optimizers plays a crucial role in full-stack AutoML systems. However, prior methods in optimizer search are often limited by their scalability, generability, or sample efficiency. With the goal of democratizing research and application of optimizer search, we present the first efficient, scalable and generalizable framework that can directly search on the tasks of interest. We first observe that optimizer updates are fundamentally mathematical expressions applied to the gradient. Inspired by the innate tree structure of the underlying math expressions, we re-arrange the space of optimizers into a super-tree, where each path encodes an optimizer. This way, optimizer search can be naturally formulated as a path-finding problem, allowing a variety of well-established tree traversal methods to be used as the search algorithm. We adopt an adaptation of the Monte Carlo method to tree search, equipped with rejection sampling and equivalent-form detection that leverage the characteristics of optimizer update rules to further boost the sample efficiency. We provide a diverse set of tasks to benchmark our algorithm and demonstrate that, with only 128 evaluations, the proposed framework can discover optimizers that surpass both human-designed counterparts and prior optimizer search methods.
FedDM: Iterative Distribution Matching for Communication-Efficient Federated Learning
Jul 20, 2022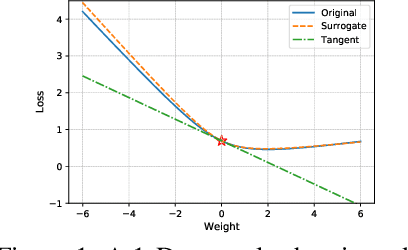

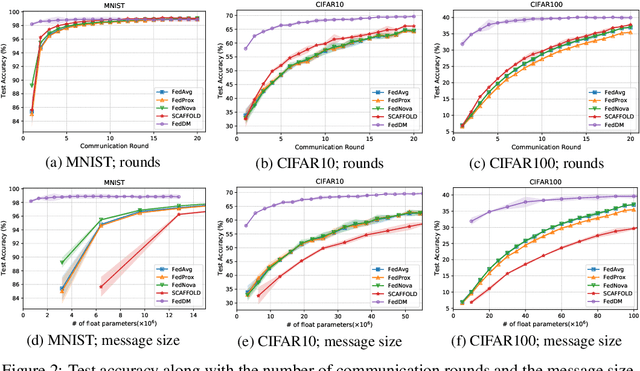
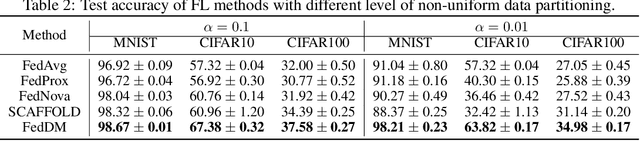
Federated learning~(FL) has recently attracted increasing attention from academia and industry, with the ultimate goal of achieving collaborative training under privacy and communication constraints. Existing iterative model averaging based FL algorithms require a large number of communication rounds to obtain a well-performed model due to extremely unbalanced and non-i.i.d data partitioning among different clients. Thus, we propose FedDM to build the global training objective from multiple local surrogate functions, which enables the server to gain a more global view of the loss landscape. In detail, we construct synthetic sets of data on each client to locally match the loss landscape from original data through distribution matching. FedDM reduces communication rounds and improves model quality by transmitting more informative and smaller synthesized data compared with unwieldy model weights. We conduct extensive experiments on three image classification datasets, and results show that our method can outperform other FL counterparts in terms of efficiency and model performance. Moreover, we demonstrate that FedDM can be adapted to preserve differential privacy with Gaussian mechanism and train a better model under the same privacy budget.
Extreme Zero-Shot Learning for Extreme Text Classification
Dec 16, 2021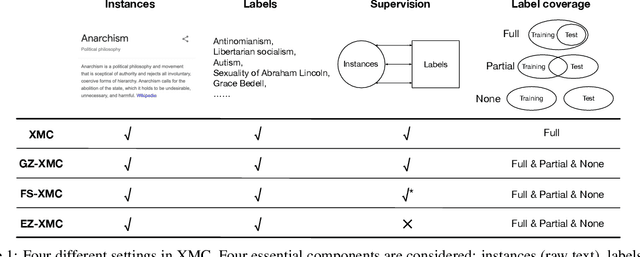
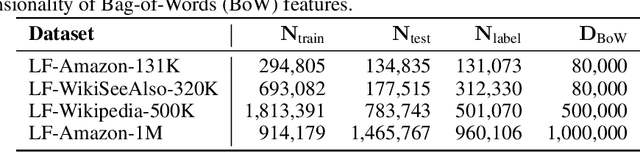
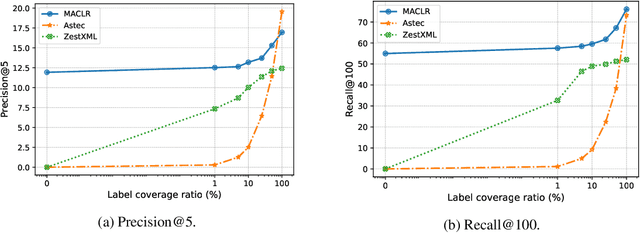
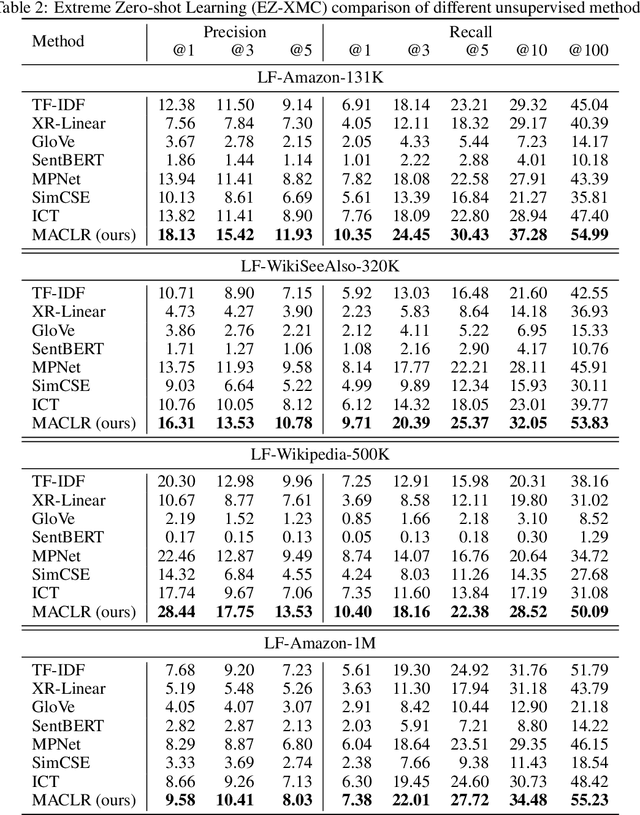
The eXtreme Multi-label text Classification (XMC) problem concerns finding most relevant labels for an input text instance from a large label set. However, the XMC setup faces two challenges: (1) it is not generalizable to predict unseen labels in dynamic environments, and (2) it requires a large amount of supervised (instance, label) pairs, which can be difficult to obtain for emerging domains. Recently, the generalized zero-shot XMC (GZ-XMC) setup has been studied and ZestXML is proposed accordingly to handle the unseen labels, which still requires a large number of annotated (instance, label) pairs. In this paper, we consider a more practical scenario called Extreme Zero-Shot XMC (EZ-XMC), in which no supervision is needed and merely raw text of instances and labels are accessible. Few-Shot XMC (FS-XMC), an extension to EZ-XMC with limited supervision is also investigated. To learn the semantic embeddings of instances and labels with raw text, we propose to pre-train Transformer-based encoders with self-supervised contrastive losses. Specifically, we develop a pre-training method MACLR, which thoroughly leverages the raw text with techniques including Multi-scale Adaptive Clustering, Label Regularization, and self-training with pseudo positive pairs. Experimental results on four public EZ-XMC datasets demonstrate that MACLR achieves superior performance compared to all other leading baseline methods, in particular with approximately 5-10% improvement in precision and recall on average. Moreover, we also show that our pre-trained encoder can be further improved on FS-XMC when there are a limited number of ground-truth positive pairs in training. By fine-tuning the encoder on such a few-shot subset, MACLR still outperforms other extreme classifiers significantly.
Adversarial Attack across Datasets
Oct 13, 2021
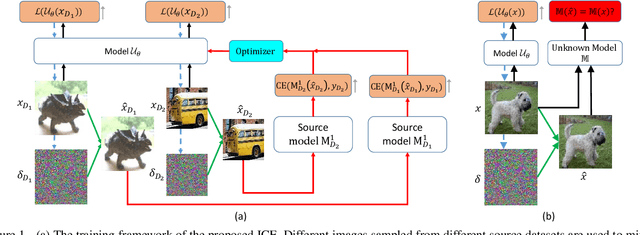
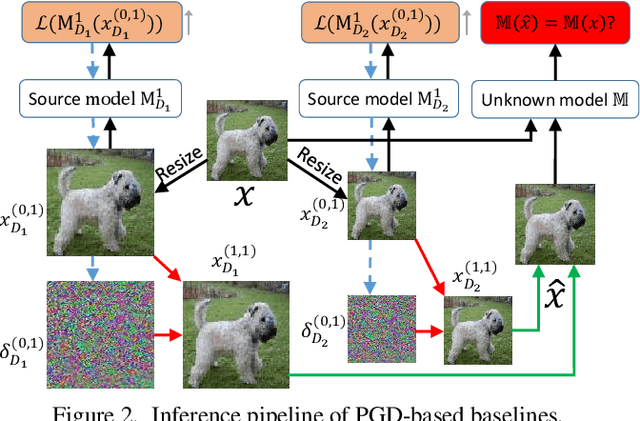
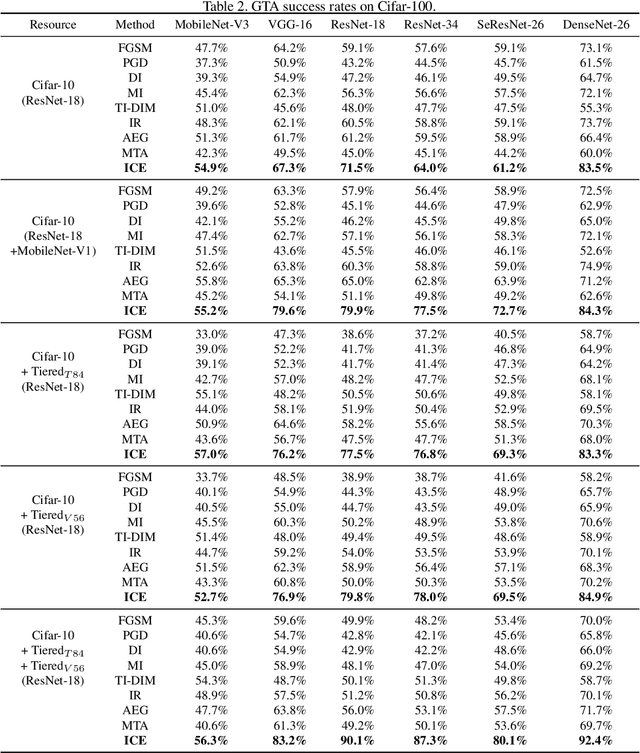
It has been observed that Deep Neural Networks (DNNs) are vulnerable to transfer attacks in the query-free black-box setting. However, all the previous studies on transfer attack assume that the white-box surrogate models possessed by the attacker and the black-box victim models are trained on the same dataset, which means the attacker implicitly knows the label set and the input size of the victim model. However, this assumption is usually unrealistic as the attacker may not know the dataset used by the victim model, and further, the attacker needs to attack any randomly encountered images that may not come from the same dataset. Therefore, in this paper we define a new Generalized Transferable Attack (GTA) problem where we assume the attacker has a set of surrogate models trained on different datasets (with different label sets and image sizes), and none of them is equal to the dataset used by the victim model. We then propose a novel method called Image Classification Eraser (ICE) to erase classification information for any encountered images from arbitrary dataset. Extensive experiments on Cifar-10, Cifar-100, and TieredImageNet demonstrate the effectiveness of the proposed ICE on the GTA problem. Furthermore, we show that existing transfer attack methods can be modified to tackle the GTA problem, but with significantly worse performance compared with ICE.
Training Meta-Surrogate Model for Transferable Adversarial Attack
Sep 07, 2021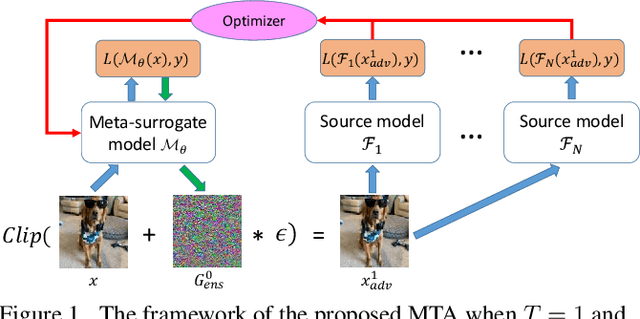
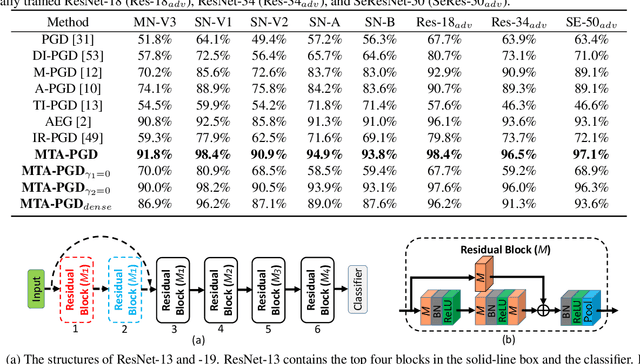
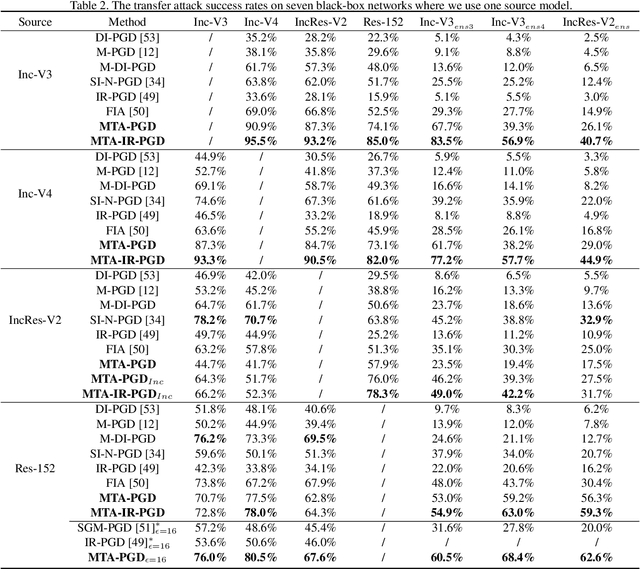
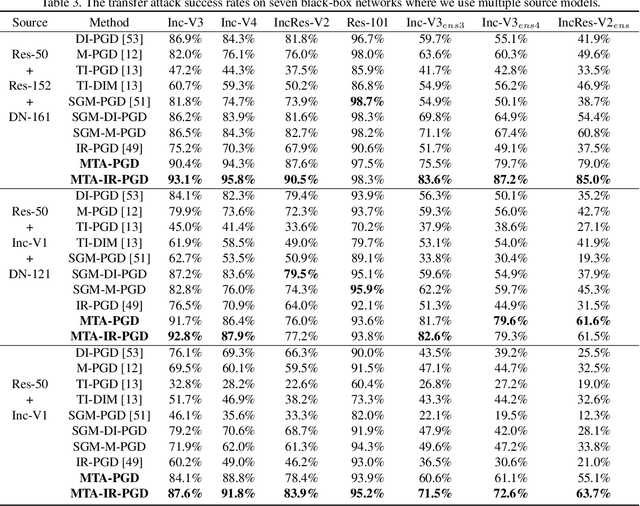
We consider adversarial attacks to a black-box model when no queries are allowed. In this setting, many methods directly attack surrogate models and transfer the obtained adversarial examples to fool the target model. Plenty of previous works investigated what kind of attacks to the surrogate model can generate more transferable adversarial examples, but their performances are still limited due to the mismatches between surrogate models and the target model. In this paper, we tackle this problem from a novel angle -- instead of using the original surrogate models, can we obtain a Meta-Surrogate Model (MSM) such that attacks to this model can be easier transferred to other models? We show that this goal can be mathematically formulated as a well-posed (bi-level-like) optimization problem and design a differentiable attacker to make training feasible. Given one or a set of surrogate models, our method can thus obtain an MSM such that adversarial examples generated on MSM enjoy eximious transferability. Comprehensive experiments on Cifar-10 and ImageNet demonstrate that by attacking the MSM, we can obtain stronger transferable adversarial examples to fool black-box models including adversarially trained ones, with much higher success rates than existing methods. The proposed method reveals significant security challenges of deep models and is promising to be served as a state-of-the-art benchmark for evaluating the robustness of deep models in the black-box setting.