 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEFA: Parameter-Free Adapters for Large-scale Embedding-based Retrieval Models
Dec 06, 2023

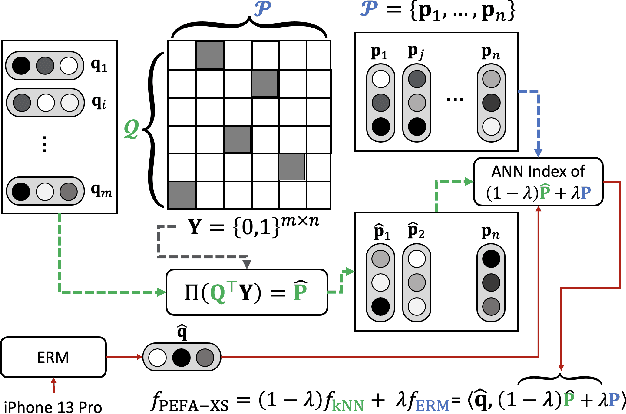

Embedding-based Retrieval Models (ERMs) have emerged as a promising framework for large-scale text retrieval problems due to powerful large language models. Nevertheless, fine-tuning ERMs to reach state-of-the-art results can be expensive due to the extreme scale of data as well as the complexity of multi-stages pipelines (e.g., pre-training, fine-tuning, distillation). In this work, we propose the PEFA framework, namely ParamEter-Free Adapters, for fast tuning of ERMs without any backward pass in the optimization. At index building stage, PEFA equips the ERM with a non-parametric k-nearest neighbor (kNN) component. At inference stage, PEFA performs a convex combination of two scoring functions, one from the ERM and the other from the kNN. Based on the neighborhood definition, PEFA framework induces two realizations, namely PEFA-XL (i.e., extra large) using double ANN indices and PEFA-XS (i.e., extra small) using a single ANN index. Empirically, PEFA achieves significant improvement on two retrieval applications. For document retrieval, regarding Recall@100 metric, PEFA improves not only pre-trained ERMs on Trivia-QA by an average of 13.2%, but also fine-tuned ERMs on NQ-320K by an average of 5.5%, respectively. For product search, PEFA improves the Recall@100 of the fine-tuned ERMs by an average of 5.3% and 14.5%, for PEFA-XS and PEFA-XL, respectively. Our code is available at https://github.com/amzn/pecos/tree/mainline/examples/pefa-wsdm24.
MinPrompt: Graph-based Minimal Prompt Data Augmentation for Few-shot Question Answering
Oct 08, 2023



Few-shot question answering (QA) aims at achieving satisfactory results on machine question answering when only a few training samples are available. Recent advances mostly rely on the power of pre-trained large language models (LLMs) and fine-tuning in specific settings. Although the pre-training stage has already equipped LLMs with powerful reasoning capabilities, LLMs still need to be fine-tuned to adapt to specific domains to achieve the best results. In this paper, we propose to select the most informative data for fine-tuning, thereby improving the efficiency of the fine-tuning process with comparative or even better accuracy on the open-domain QA task. We present MinPrompt, a minimal data augmentation framework for open-domain QA based on an approximate graph algorithm and unsupervised question generation. We transform the raw text into a graph structure to build connections between different factual sentences, then apply graph algorithms to identify the minimal set of sentences needed to cover the most information in the raw text. We then generate QA pairs based on the identified sentence subset and train the model on the selected sentences to obtain the final model. Empirical results on several benchmark datasets and theoretical analysis show that MinPrompt is able to achieve comparable or better results than baselines with a high degree of efficiency, bringing improvements in F-1 scores by up to 27.5%.
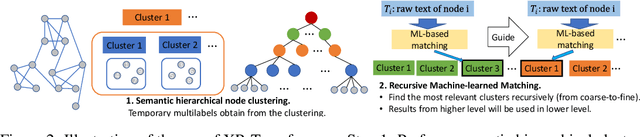
PINA: Leveraging Side Information in eXtreme Multi-label Classification via Predicted Instance Neighborhood Aggregation
May 21, 2023The eXtreme Multi-label Classification~(XMC) problem seeks to find relevant labels from an exceptionally large label space. Most of the existing XMC learners focus on the extraction of semantic features from input query text. However, conventional XMC studies usually neglect the side information of instances and labels, which can be of use in many real-world applications such as recommendation systems and e-commerce product search. We propose Predicted Instance Neighborhood Aggregation (PINA), a data enhancement method for the general XMC problem that leverages beneficial side information. Unlike most existing XMC frameworks that treat labels and input instances as featureless indicators and independent entries, PINA extracts information from the label metadata and the correlations among training instances. Extensive experimental results demonstrate the consistent gain of PINA on various XMC tasks compared to the state-of-the-art methods: PINA offers a gain in accuracy compared to standard XR-Transformers on five public benchmark datasets. Moreover, PINA achieves a $\sim 5\%$ gain in accuracy on the largest dataset LF-AmazonTitles-1.3M. Our implementation is publicly available.
Uncertainty in Extreme Multi-label Classification
Oct 18, 2022
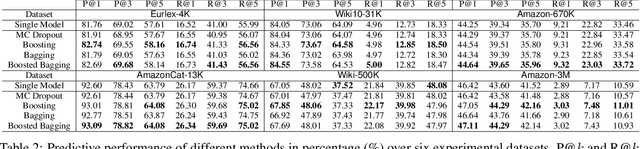
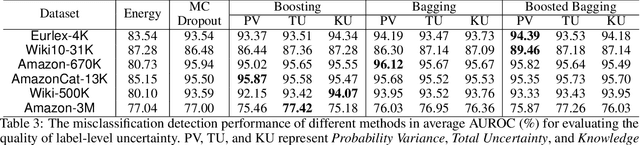
Uncertainty quantification is one of the most crucial tasks to obtain trustworthy and reliable machine learning models for decision making. However, most research in this domain has only focused on problems with small label spaces and ignored eXtreme Multi-label Classification (XMC), which is an essential task in the era of big data for web-scale machine learning applications. Moreover, enormous label spaces could also lead to noisy retrieval results and intractable computational challenges for uncertainty quantification. In this paper, we aim to investigate general uncertainty quantification approaches for tree-based XMC models with a probabilistic ensemble-based framework. In particular, we analyze label-level and instance-level uncertainty in XMC, and propose a general approximation framework based on beam search to efficiently estimate the uncertainty with a theoretical guarantee under long-tail XMC predictions. Empirical studies on six large-scale real-world datasets show that our framework not only outperforms single models in predictive performance, but also can serve as strong uncertainty-based baselines for label misclassification and out-of-distribution detection, with significant speedup. Besides, our framework can further yield better state-of-the-art results based on deep XMC models with uncertainty quantification.
Extreme Zero-Shot Learning for Extreme Text Classification
Dec 16, 2021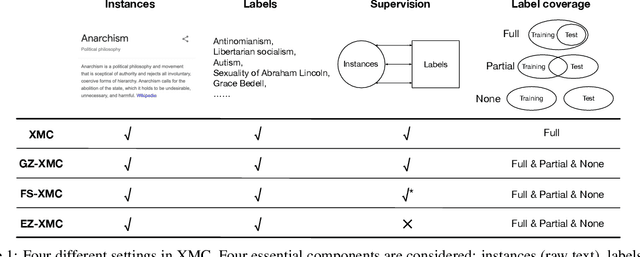
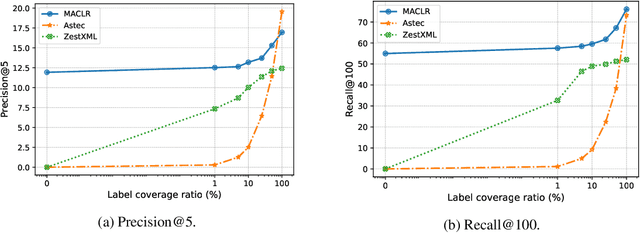
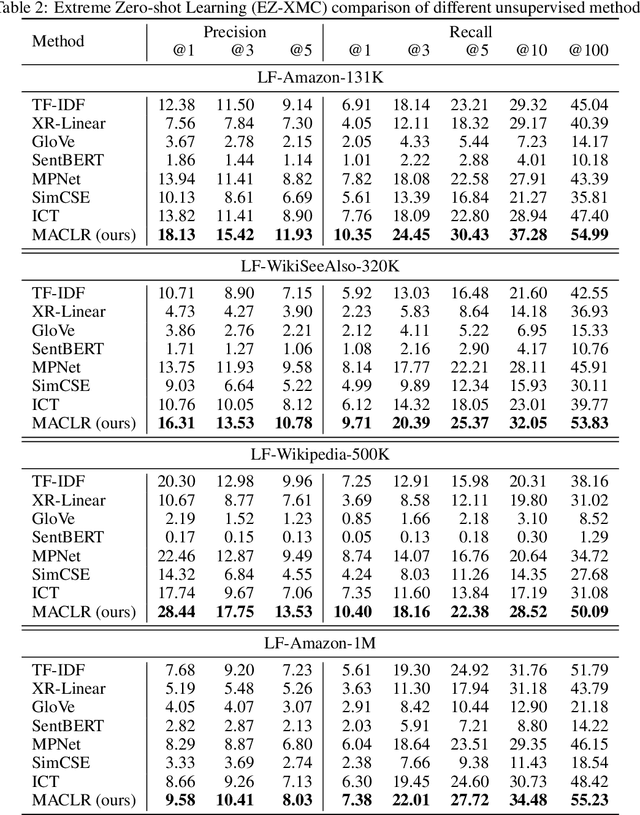
The eXtreme Multi-label text Classification (XMC) problem concerns finding most relevant labels for an input text instance from a large label set. However, the XMC setup faces two challenges: (1) it is not generalizable to predict unseen labels in dynamic environments, and (2) it requires a large amount of supervised (instance, label) pairs, which can be difficult to obtain for emerging domains. Recently, the generalized zero-shot XMC (GZ-XMC) setup has been studied and ZestXML is proposed accordingly to handle the unseen labels, which still requires a large number of annotated (instance, label) pairs. In this paper, we consider a more practical scenario called Extreme Zero-Shot XMC (EZ-XMC), in which no supervision is needed and merely raw text of instances and labels are accessible. Few-Shot XMC (FS-XMC), an extension to EZ-XMC with limited supervision is also investigated. To learn the semantic embeddings of instances and labels with raw text, we propose to pre-train Transformer-based encoders with self-supervised contrastive losses. Specifically, we develop a pre-training method MACLR, which thoroughly leverages the raw text with techniques including Multi-scale Adaptive Clustering, Label Regularization, and self-training with pseudo positive pairs. Experimental results on four public EZ-XMC datasets demonstrate that MACLR achieves superior performance compared to all other leading baseline methods, in particular with approximately 5-10% improvement in precision and recall on average. Moreover, we also show that our pre-trained encoder can be further improved on FS-XMC when there are a limited number of ground-truth positive pairs in training. By fine-tuning the encoder on such a few-shot subset, MACLR still outperforms other extreme classifiers significantly.
Node Feature Extraction by Self-Supervised Multi-scale Neighborhood Prediction
Oct 29, 2021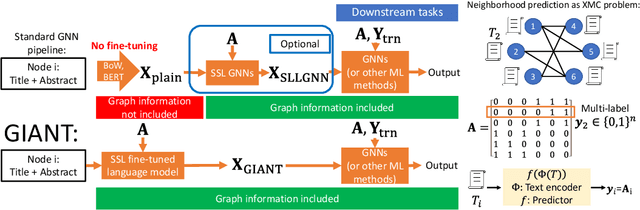

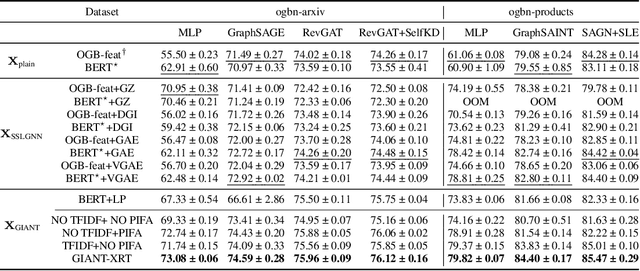
Learning on graphs has attracted significant attention in the learning community due to numerous real-world applications. In particular, graph neural networks (GNNs), which take numerical node features and graph structure as inputs, have been shown to achieve state-of-the-art performance on various graph-related learning tasks. Recent works exploring the correlation between numerical node features and graph structure via self-supervised learning have paved the way for further performance improvements of GNNs. However, methods used for extracting numerical node features from raw data are still graph-agnostic within standard GNN pipelines. This practice is sub-optimal as it prevents one from fully utilizing potential correlations between graph topology and node attributes. To mitigate this issue, we propose a new self-supervised learning framework, Graph Information Aided Node feature exTraction (GIANT). GIANT makes use of the eXtreme Multi-label Classification (XMC) formalism, which is crucial for fine-tuning the language model based on graph information, and scales to large datasets. We also provide a theoretical analysis that justifies the use of XMC over link prediction and motivates integrating XR-Transformers, a powerful method for solving XMC problems, into the GIANT framework. We demonstrate the superior performance of GIANT over the standard GNN pipeline on Open Graph Benchmark datasets: For example, we improve the accuracy of the top-ranked method GAMLP from $68.25\%$ to $69.67\%$, SGC from $63.29\%$ to $66.10\%$ and MLP from $47.24\%$ to $61.10\%$ on the ogbn-papers100M dataset by leveraging GIANT.
Label Disentanglement in Partition-based Extreme Multilabel Classification
Jun 24, 2021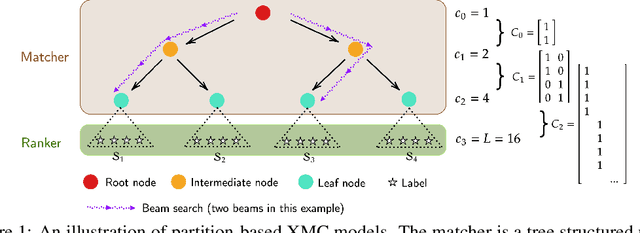
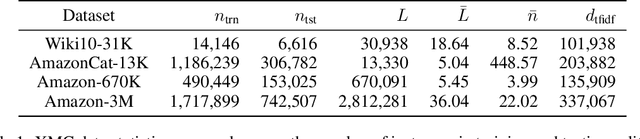
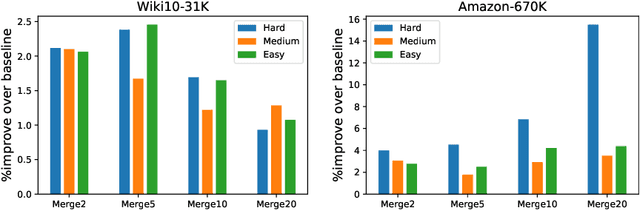
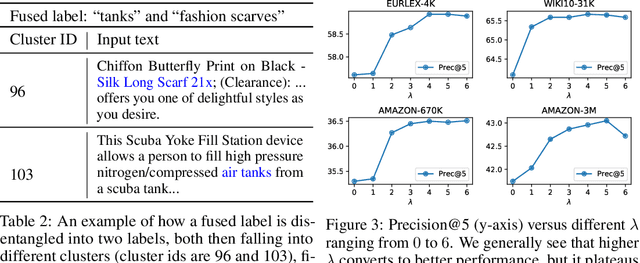
Partition-based methods are increasingly-used in extreme multi-label classification (XMC) problems due to their scalability to large output spaces (e.g., millions or more). However, existing methods partition the large label space into mutually exclusive clusters, which is sub-optimal when labels have multi-modality and rich semantics. For instance, the label "Apple" can be the fruit or the brand name, which leads to the following research question: can we disentangle these multi-modal labels with non-exclusive clustering tailored for downstream XMC tasks? In this paper, we show that the label assignment problem in partition-based XMC can be formulated as an optimization problem, with the objective of maximizing precision rates. This leads to an efficient algorithm to form flexible and overlapped label clusters, and a method that can alternatively optimizes the cluster assignments and the model parameters for partition-based XMC. Experimental results on synthetic and real datasets show that our method can successfully disentangle multi-modal labels, leading to state-of-the-art (SOTA) results on four XMC benchmarks.
Extreme Multi-label Learning for Semantic Matching in Product Search
Jun 23, 2021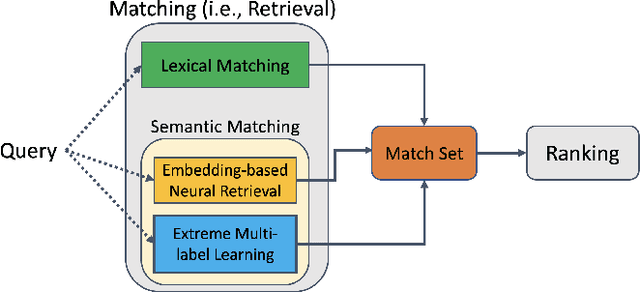

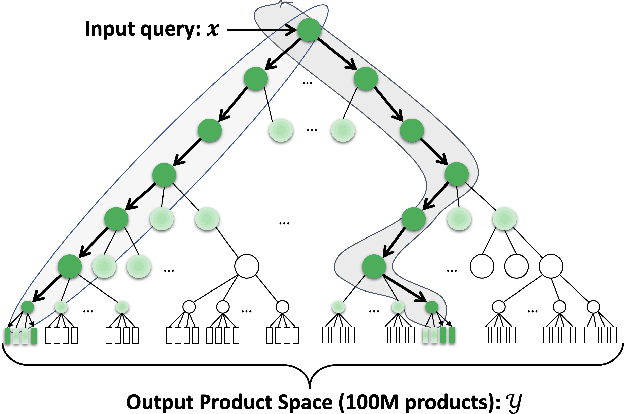
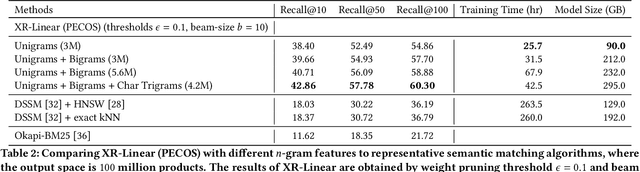
We consider the problem of semantic matching in product search: given a customer query, retrieve all semantically related products from a huge catalog of size 100 million, or more. Because of large catalog spaces and real-time latency constraints, semantic matching algorithms not only desire high recall but also need to have low latency. Conventional lexical matching approaches (e.g., Okapi-BM25) exploit inverted indices to achieve fast inference time, but fail to capture behavioral signals between queries and products. In contrast, embedding-based models learn semantic representations from customer behavior data, but the performance is often limited by shallow neural encoders due to latency constraints. Semantic product search can be viewed as an eXtreme Multi-label Classification (XMC) problem, where customer queries are input instances and products are output labels. In this paper, we aim to improve semantic product search by using tree-based XMC models where inference time complexity is logarithmic in the number of products. We consider hierarchical linear models with n-gram features for fast real-time inference. Quantitatively, our method maintains a low latency of 1.25 milliseconds per query and achieves a 65% improvement of Recall@100 (60.9% v.s. 36.8%) over a competing embedding-based DSSM model. Our model is robust to weight pruning with varying thresholds, which can flexibly meet different system requirements for online deployments. Qualitatively, our method can retrieve products that are complementary to existing product search system and add diversity to the match set.
Kernel Stein Generative Modeling
Jul 06, 2020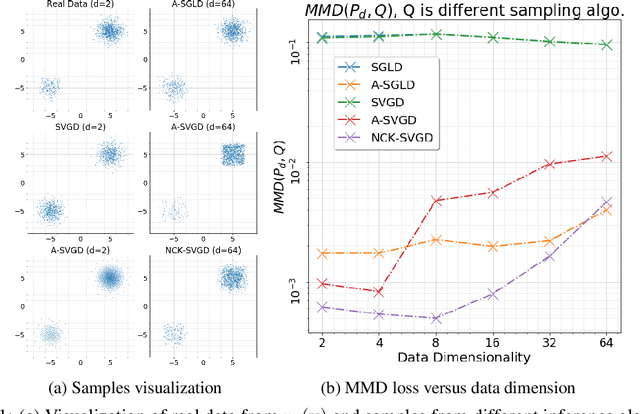
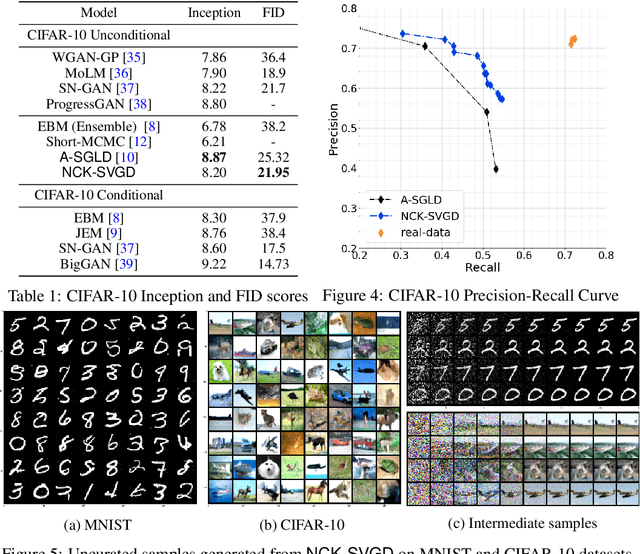
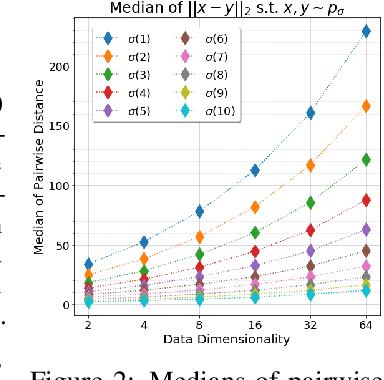
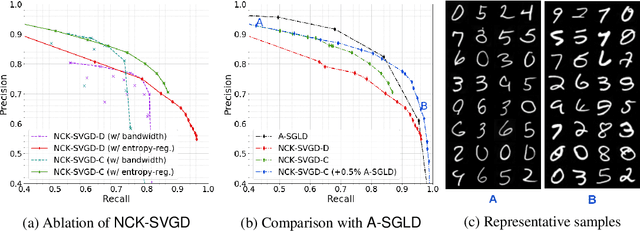
We are interested in gradient-based Explicit Generative Modeling where samples can be derived from iterative gradient updates based on an estimate of the score function of the data distribution. Recent advances in Stochastic Gradient Langevin Dynamics (SGLD) demonstrates impressive results with energy-based models on high-dimensional and complex data distributions. Stein Variational Gradient Descent (SVGD) is a deterministic sampling algorithm that iteratively transports a set of particles to approximate a given distribution, based on functional gradient descent that decreases the KL divergence. SVGD has promising results on several Bayesian inference applications. However, applying SVGD on high dimensional problems is still under-explored. The goal of this work is to study high dimensional inference with SVGD. We first identify key challenges in practical kernel SVGD inference in high-dimension. We propose noise conditional kernel SVGD (NCK-SVGD), that works in tandem with the recently introduced Noise Conditional Score Network estimator. NCK is crucial for successful inference with SVGD in high dimension, as it adapts the kernel to the noise level of the score estimate. As we anneal the noise, NCK-SVGD targets the real data distribution. We then extend the annealed SVGD with an entropic regularization. We show that this offers a flexible control between sample quality and diversity, and verify it empirically by precision and recall evaluations. The NCK-SVGD produces samples comparable to GANs and annealed SGLD on computer vision benchmarks, including MNIST and CIFAR-10.
Explainable Unsupervised Change-point Detection via Graph Neural Networks
Apr 24, 2020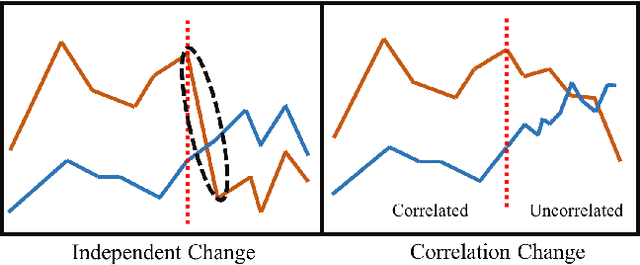
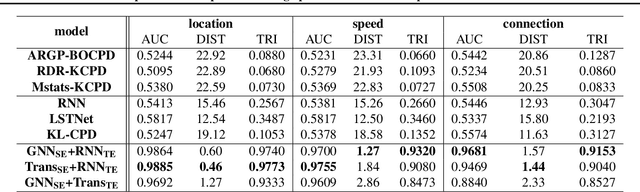
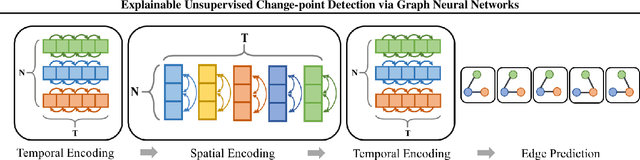

Change-point detection (CPD) aims at detecting the abrupt property changes lying behind time series data. The property changes in a multivariate time series often result from highly entangled reasons, ranging from independent changes of variables to correlation changes between variables. Learning to uncover the reasons behind the changes in an unsupervised setting is a new and challenging task. Previous CPD methods usually detect change-points by a divergence estimation of statistical features, without delving into the reasons behind the detected changes. In this paper, we propose a correlation-aware dynamics model which separately predicts the correlation change and independent change by incorporating graph neural networks into the encoder-decoder framework. Through experiments on synthetic and real-world datasets, we demonstrate the enhanced performance of our model on the CPD tasks as well as its ability to interpret the nature and degree of the predicted changes.