 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Representation Sharpening Framework for Zero Shot Dense Retrieval
Nov 07, 2025Zero-shot dense retrieval is a challenging setting where a document corpus is provided without relevant queries, necessitating a reliance on pretrained dense retrievers (DRs). However, since these DRs are not trained on the target corpus, they struggle to represent semantic differences between similar documents. To address this failing, we introduce a training-free representation sharpening framework that augments a document's representation with information that helps differentiate it from similar documents in the corpus. On over twenty datasets spanning multiple languages, the representation sharpening framework proves consistently superior to traditional retrieval, setting a new state-of-the-art on the BRIGHT benchmark. We show that representation sharpening is compatible with prior approaches to zero-shot dense retrieval and consistently improves their performance. Finally, we address the performance-cost tradeoff presented by our framework and devise an indexing-time approximation that preserves the majority of our performance gains over traditional retrieval, yet suffers no additional inference-time cost.
Exposing Privacy Gaps: Membership Inference Attack on Preference Data for LLM Alignment
Jul 08, 2024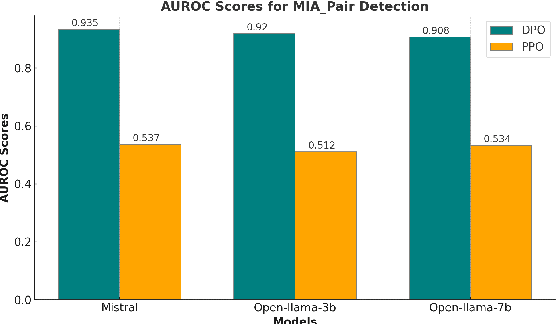
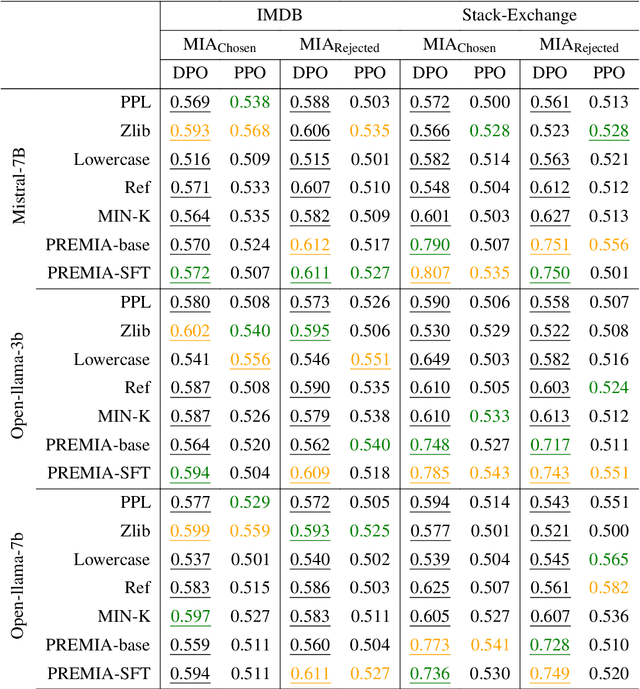
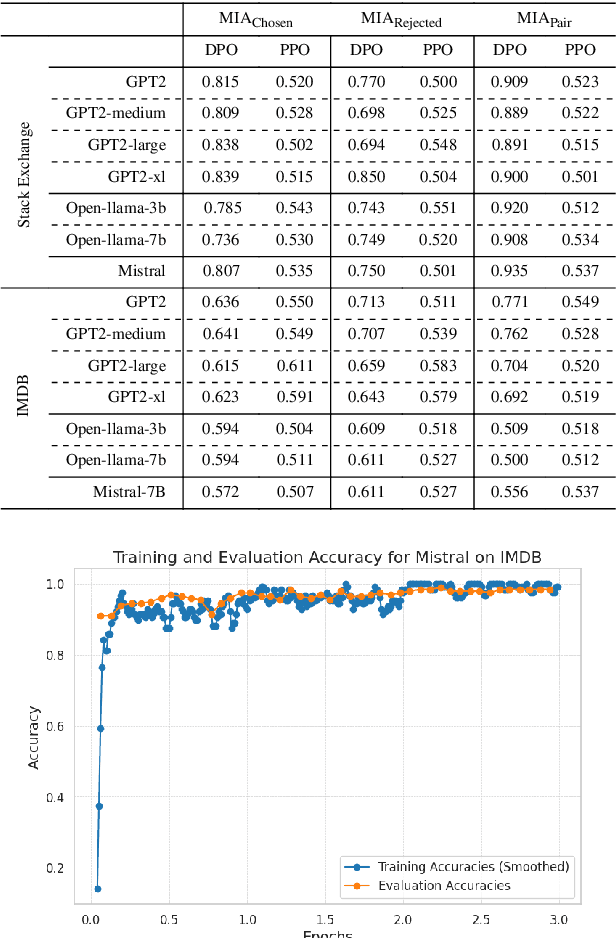
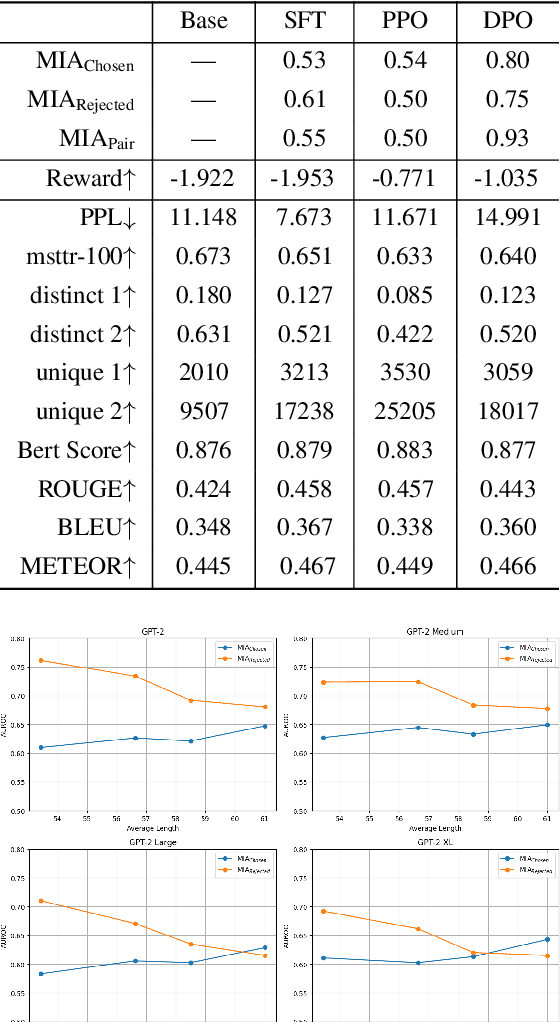
Large Language Models (LLMs) have seen widespread adoption due to their remarkable natural language capabilities. However, when deploying them in real-world settings, it is important to align LLMs to generate texts according to acceptable human standards. Methods such as Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) have made significant progress in refining LLMs using human preference data. However, the privacy concerns inherent in utilizing such preference data have yet to be adequately studied. In this paper, we investigate the vulnerability of LLMs aligned using human preference datasets to membership inference attacks (MIAs), highlighting the shortcomings of previous MIA approaches with respect to preference data. Our study has two main contributions: first, we introduce a novel reference-based attack framework specifically for analyzing preference data called PREMIA (\uline{Pre}ference data \uline{MIA}); second, we provide empirical evidence that DPO models are more vulnerable to MIA compared to PPO models. Our findings highlight gaps in current privacy-preserving practices for LLM alignment.
PEFA: Parameter-Free Adapters for Large-scale Embedding-based Retrieval Models
Dec 06, 2023

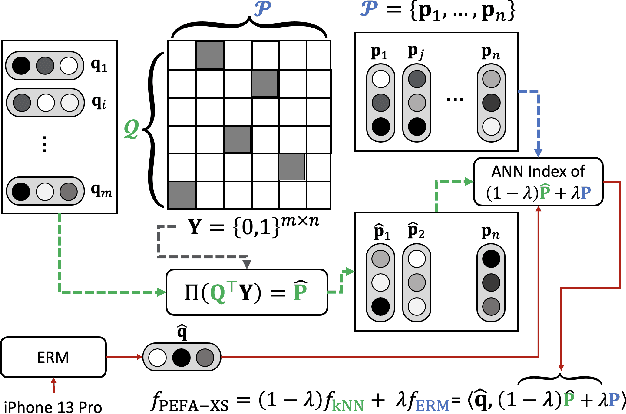

Embedding-based Retrieval Models (ERMs) have emerged as a promising framework for large-scale text retrieval problems due to powerful large language models. Nevertheless, fine-tuning ERMs to reach state-of-the-art results can be expensive due to the extreme scale of data as well as the complexity of multi-stages pipelines (e.g., pre-training, fine-tuning, distillation). In this work, we propose the PEFA framework, namely ParamEter-Free Adapters, for fast tuning of ERMs without any backward pass in the optimization. At index building stage, PEFA equips the ERM with a non-parametric k-nearest neighbor (kNN) component. At inference stage, PEFA performs a convex combination of two scoring functions, one from the ERM and the other from the kNN. Based on the neighborhood definition, PEFA framework induces two realizations, namely PEFA-XL (i.e., extra large) using double ANN indices and PEFA-XS (i.e., extra small) using a single ANN index. Empirically, PEFA achieves significant improvement on two retrieval applications. For document retrieval, regarding Recall@100 metric, PEFA improves not only pre-trained ERMs on Trivia-QA by an average of 13.2%, but also fine-tuned ERMs on NQ-320K by an average of 5.5%, respectively. For product search, PEFA improves the Recall@100 of the fine-tuned ERMs by an average of 5.3% and 14.5%, for PEFA-XS and PEFA-XL, respectively. Our code is available at https://github.com/amzn/pecos/tree/mainline/examples/pefa-wsdm24.
MICO: Selective Search with Mutual Information Co-training
Sep 09, 2022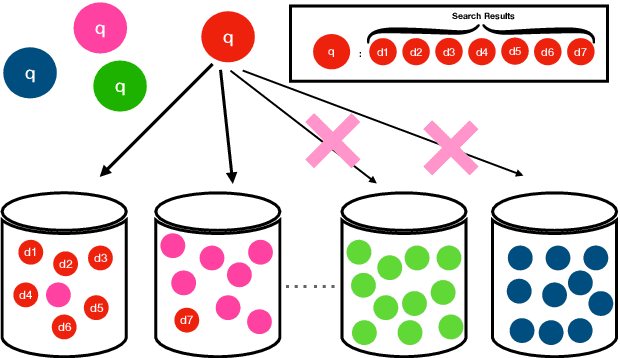
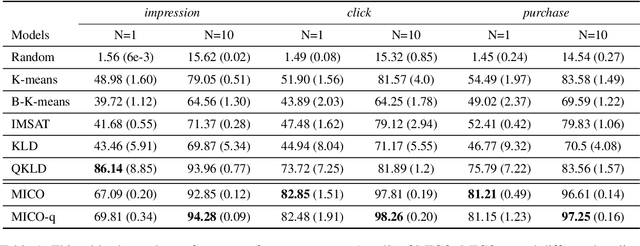
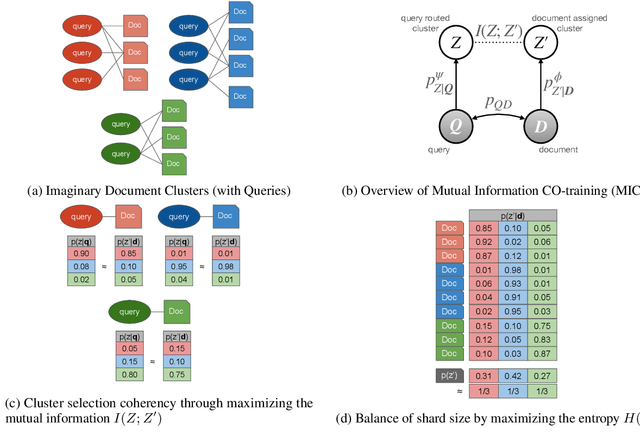
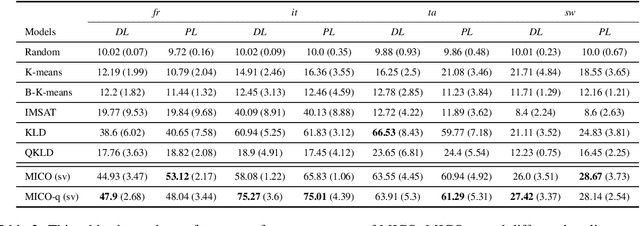
In contrast to traditional exhaustive search, selective search first clusters documents into several groups before all the documents are searched exhaustively by a query, to limit the search executed within one group or only a few groups. Selective search is designed to reduce the latency and computation in modern large-scale search systems. In this study, we propose MICO, a Mutual Information CO-training framework for selective search with minimal supervision using the search logs. After training, MICO does not only cluster the documents, but also routes unseen queries to the relevant clusters for efficient retrieval. In our empirical experiments, MICO significantly improves the performance on multiple metrics of selective search and outperforms a number of existing competitive baselines.
On the Value of Behavioral Representations for Dense Retrieval
Aug 11, 2022


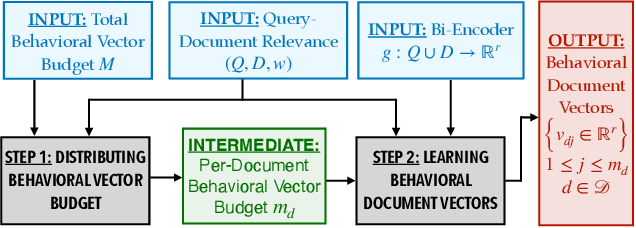
We consider text retrieval within dense representational space in real-world settings such as e-commerce search where (a) document popularity and (b) diversity of queries associated with a document have a skewed distribution. Most of the contemporary dense retrieval literature presents two shortcomings in these settings. (1) They learn an almost equal number of representations per document, agnostic to the fact that a few head documents are disproportionately more critical to achieving a good retrieval performance. (ii) They learn purely semantic document representations inferred from intrinsic document characteristics which may not contain adequate information to determine the queries for which the document is relevant--especially when the document is short. We propose to overcome these limitations by augmenting semantic document representations learned by bi-encoders with behavioral document representations learned by our proposed approach MVG. To do so, MVG (1) determines how to divide the total budget for behavioral representations by drawing a connection to the Pitman-Yor process, and (2) simply clusters the queries related to a given document (based on user behavior) within the representational space learned by a base bi-encoder, and treats the cluster centers as its behavioral representations. Our central contribution is the finding such a simple intuitive light-weight approach leads to substantial gains in key first-stage retrieval metrics by incurring only a marginal memory overhead. We establish this via extensive experiments over three large public datasets comparing several single-vector and multi-vector bi-encoders, a proprietary e-commerce search dataset compared to production-quality bi-encoder, and an A/B test.
Embracing Structure in Data for Billion-Scale Semantic Product Search
Oct 12, 2021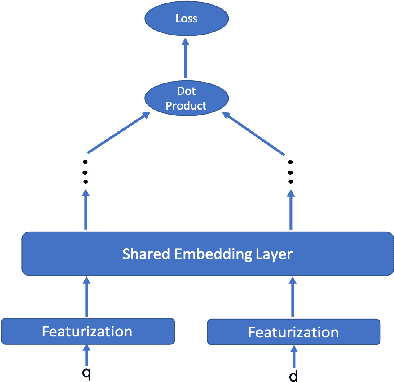
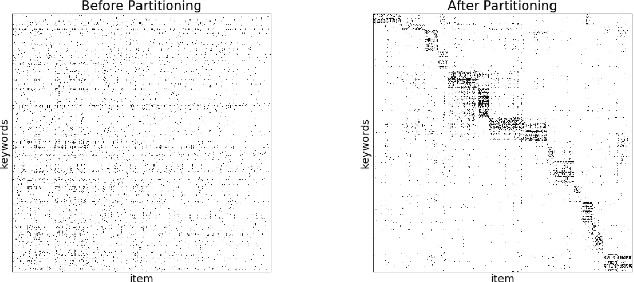
We present principled approaches to train and deploy dyadic neural embedding models at the billion scale, focusing our investigation on the application of semantic product search. When training a dyadic model, one seeks to embed two different types of entities (e.g., queries and documents or users and movies) in a common vector space such that pairs with high relevance are positioned nearby. During inference, given an embedding of one type (e.g., a query or a user), one seeks to retrieve the entities of the other type (e.g., documents or movies, respectively) that are highly relevant. In this work, we show that exploiting the natural structure of real-world datasets helps address both challenges efficiently. Specifically, we model dyadic data as a bipartite graph with edges between pairs with positive associations. We then propose to partition this network into semantically coherent clusters and thus reduce our search space by focusing on a small subset of these partitions for a given input. During training, this technique enables us to efficiently mine hard negative examples while, at inference, we can quickly find the nearest neighbors for a given embedding. We provide offline experimental results that demonstrate the efficacy of our techniques for both training and inference on a billion-scale Amazon.com product search dataset.
Semantic Product Search
Jul 01, 2019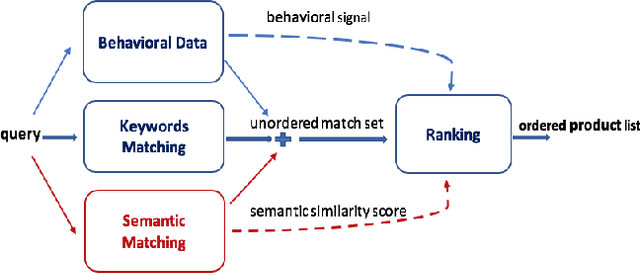
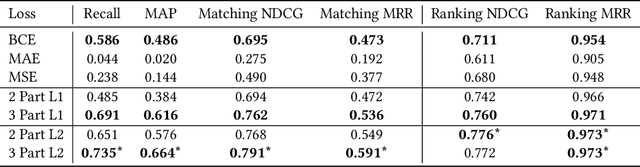
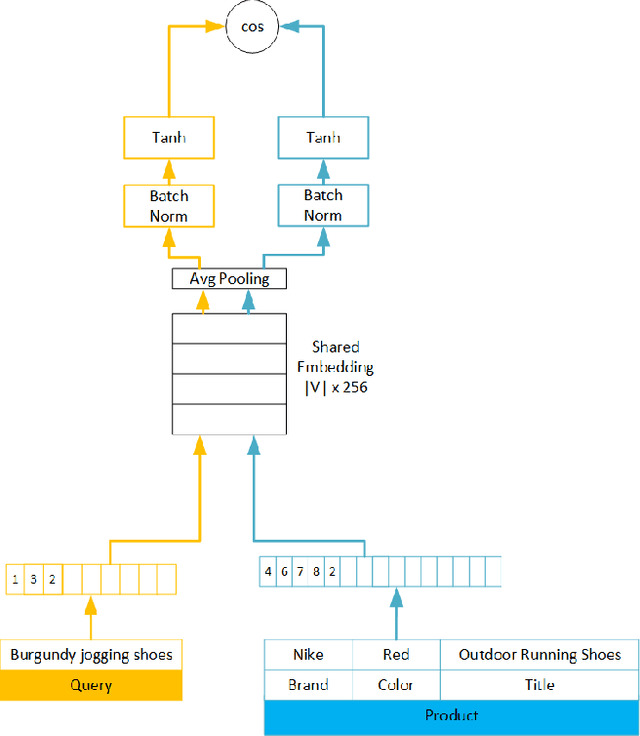
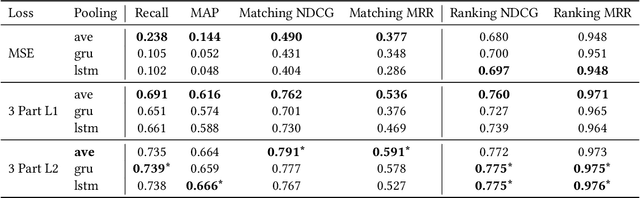
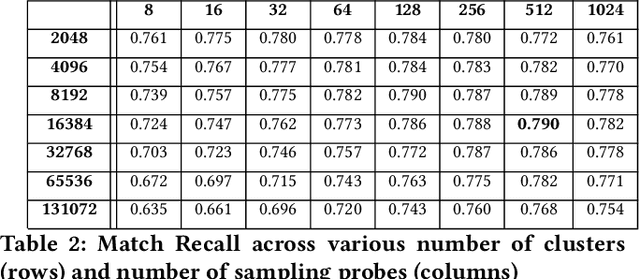
We study the problem of semantic matching in product search, that is, given a customer query, retrieve all semantically related products from the catalog. Pure lexical matching via an inverted index falls short in this respect due to several factors: a) lack of understanding of hypernyms, synonyms, and antonyms, b) fragility to morphological variants (e.g. "woman" vs. "women"), and c) sensitivity to spelling errors. To address these issues, we train a deep learning model for semantic matching using customer behavior data. Much of the recent work on large-scale semantic search using deep learning focuses on ranking for web search. In contrast, semantic matching for product search presents several novel challenges, which we elucidate in this paper. We address these challenges by a) developing a new loss function that has an inbuilt threshold to differentiate between random negative examples, impressed but not purchased examples, and positive examples (purchased items), b) using average pooling in conjunction with n-grams to capture short-range linguistic patterns, c) using hashing to handle out of vocabulary tokens, and d) using a model parallel training architecture to scale across 8 GPUs. We present compelling offline results that demonstrate at least 4.7% improvement in Recall@100 and 14.5% improvement in mean average precision (MAP) over baseline state-of-the-art semantic search methods using the same tokenization method. Moreover, we present results and discuss learnings from online A/B tests which demonstrate the efficacy of our method.
Adaptive, Personalized Diversity for Visual Discovery
Oct 02, 2018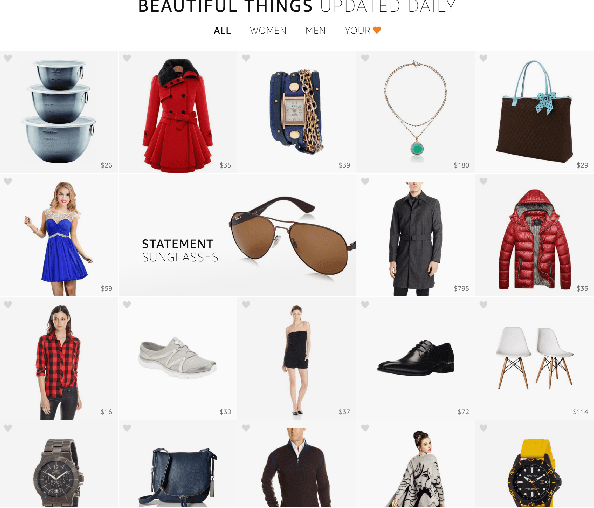

Search queries are appropriate when users have explicit intent, but they perform poorly when the intent is difficult to express or if the user is simply looking to be inspired. Visual browsing systems allow e-commerce platforms to address these scenarios while offering the user an engaging shopping experience. Here we explore extensions in the direction of adaptive personalization and item diversification within Stream, a new form of visual browsing and discovery by Amazon. Our system presents the user with a diverse set of interesting items while adapting to user interactions. Our solution consists of three components (1) a Bayesian regression model for scoring the relevance of items while leveraging uncertainty, (2) a submodular diversification framework that re-ranks the top scoring items based on category, and (3) personalized category preferences learned from the user's behavior. When tested on live traffic, our algorithms show a strong lift in click-through-rate and session duration.
* Best Paper Award