 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeER2Score: LLM-based Explainable and Customizable Metric for Assessing Radiology Reports with Reward-Control Loss
Nov 26, 2024



Automated radiology report generation (R2Gen) has advanced significantly, introducing challenges in accurate evaluation due to its complexity. Traditional metrics often fall short by relying on rigid word-matching or focusing only on pathological entities, leading to inconsistencies with human assessments. To bridge this gap, we introduce ER2Score, an automatic evaluation metric designed specifically for R2Gen. Our metric utilizes a reward model, guided by our margin-based reward enforcement loss, along with a tailored training data design that enables customization of evaluation criteria to suit user-defined needs. It not only scores reports according to user-specified criteria but also provides detailed sub-scores, enhancing interpretability and allowing users to adjust the criteria between different aspects of reports. Leveraging GPT-4, we designed an easy-to-use data generation pipeline, enabling us to produce extensive training data based on two distinct scoring systems, each containing reports of varying quality along with corresponding scores. These GPT-generated reports are then paired as accepted and rejected samples through our pairing rule to train an LLM towards our fine-grained reward model, which assigns higher rewards to the report with high quality. Our reward-control loss enables this model to simultaneously output multiple individual rewards corresponding to the number of evaluation criteria, with their summation as our final ER2Score. Our experiments demonstrate ER2Score's heightened correlation with human judgments and superior performance in model selection compared to traditional metrics. Notably, our model provides both an overall score and individual scores for each evaluation item, enhancing interpretability. We also demonstrate its flexible training across various evaluation systems.
KARGEN: Knowledge-enhanced Automated Radiology Report Generation Using Large Language Models
Sep 09, 2024



Harnessing the robust capabilities of Large Language Models (LLMs) for narrative generation, logical reasoning, and common-sense knowledge integration, this study delves into utilizing LLMs to enhance automated radiology report generation (R2Gen). Despite the wealth of knowledge within LLMs, efficiently triggering relevant knowledge within these large models for specific tasks like R2Gen poses a critical research challenge. This paper presents KARGEN, a Knowledge-enhanced Automated radiology Report GENeration framework based on LLMs. Utilizing a frozen LLM to generate reports, the framework integrates a knowledge graph to unlock chest disease-related knowledge within the LLM to enhance the clinical utility of generated reports. This is achieved by leveraging the knowledge graph to distill disease-related features in a designed way. Since a radiology report encompasses both normal and disease-related findings, the extracted graph-enhanced disease-related features are integrated with regional image features, attending to both aspects. We explore two fusion methods to automatically prioritize and select the most relevant features. The fused features are employed by LLM to generate reports that are more sensitive to diseases and of improved quality. Our approach demonstrates promising results on the MIMIC-CXR and IU-Xray datasets.
MRScore: Evaluating Radiology Report Generation with LLM-based Reward System
Apr 27, 2024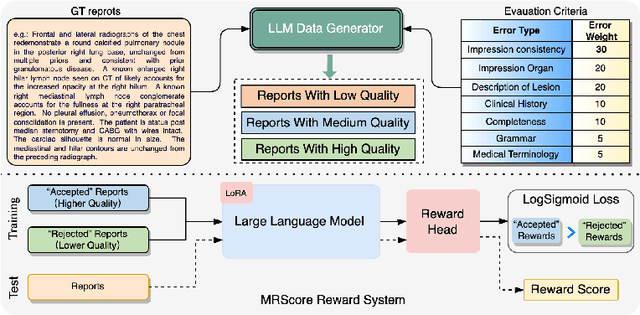
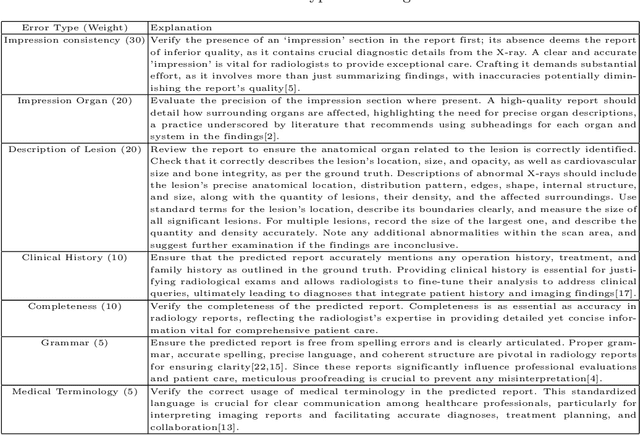
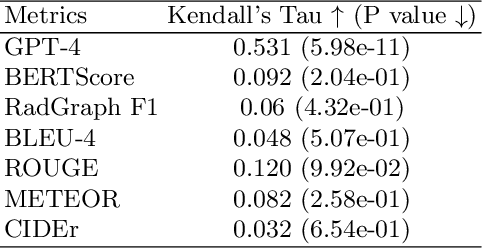
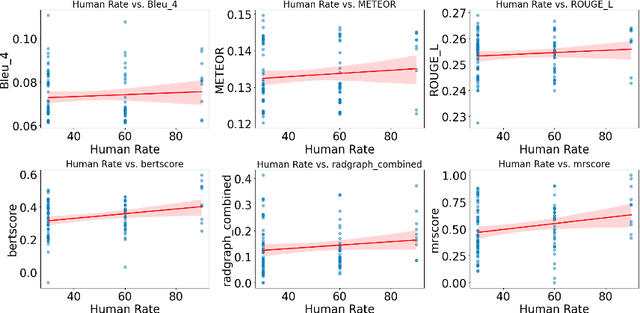
In recent years, automated radiology report generation has experienced significant growth. This paper introduces MRScore, an automatic evaluation metric tailored for radiology report generation by leveraging Large Language Models (LLMs). Conventional NLG (natural language generation) metrics like BLEU are inadequate for accurately assessing the generated radiology reports, as systematically demonstrated by our observations within this paper. To address this challenge, we collaborated with radiologists to develop a framework that guides LLMs for radiology report evaluation, ensuring alignment with human analysis. Our framework includes two key components: i) utilizing GPT to generate large amounts of training data, i.e., reports with different qualities, and ii) pairing GPT-generated reports as accepted and rejected samples and training LLMs to produce MRScore as the model reward. Our experiments demonstrate MRScore's higher correlation with human judgments and superior performance in model selection compared to traditional metrics. Our code and datasets will be available on GitHub.
MedXChat: Bridging CXR Modalities with a Unified Multimodal Large Model
Dec 04, 2023



Despite the success of Large Language Models (LLMs) in general image tasks, a gap persists in the medical field for a multimodal large model adept at handling the nuanced diversity of medical images. Addressing this, we propose MedXChat, a unified multimodal large model designed for seamless interactions between medical assistants and users. MedXChat encompasses three key functionalities: CXR(Chest X-ray)-to-Report generation, CXR-based visual question-answering (VQA), and Text-to-CXR synthesis. Our contributions are as follows. Firstly, our model showcases exceptional cross-task adaptability, displaying adeptness across all three defined tasks and outperforming the benchmark models on the MIMIC dataset in medical multimodal applications. Secondly, we introduce an innovative Text-to-CXR synthesis approach that utilizes instruction-following capabilities within the Stable Diffusion (SD) architecture. This technique integrates smoothly with the existing model framework, requiring no extra parameters, thereby maintaining the SD's generative strength while also bestowing upon it the capacity to render fine-grained medical images with high fidelity. Comprehensive experiments validate MedXChat's synergistic enhancement across all tasks. Our instruction data and model will be open-sourced.
Retrieval-augmented Multi-modal Chain-of-Thoughts Reasoning for Large Language Models
Dec 04, 2023



The advancement of Large Language Models(LLMs) has brought substantial attention to the Chain of Thought(CoT) approach, primarily due to its ability to enhance the capability of LLMs on tasks requiring complex reasoning. Moreover, the significance of CoT approaches extends to the application of LLMs for multi-modal tasks, such as multi-modal question answering. However, the selection of optimal CoT demonstration examples in multi-modal reasoning for LLMs remains less explored for LLMs due to the inherent complexity of multi-modal examples. In this paper, we introduce a novel approach that addresses this challenge by using retrieval mechanisms to dynamically and automatically select demonstration examples based on cross-modal similarities. This method aims to refine the CoT reasoning process in multi-modal scenarios via informing LLMs with more relevant and informative examples. Furthermore, we employ a stratified sampling method categorising demonstration examples into groups based on their types and retrieving examples from different groups respectively to promote the diversity of demonstration examples. Through a series of experiments, we demonstrate that our approach significantly improves the performance of LLMs, achieving state-of-the-art results in multi-modal reasoning tasks. Specifically, our methods demonstrate significant advancements on the ScienceQA dataset. While our method based on ChatGPT outperforms the Chameleon(ChatGPT) by 2.74% with an accuracy of 82.67%, the GPT4-based approach surpasses the Chameleon(GPT-4) by 0.89%, achieving 87.43% on accuracy under the same setting. Moreover, our best performing show a 6.05% increase over Chameleon for ChatGPT-based models and a 4.57% increase for GPT-4-based models.
GPT4Video: A Unified Multimodal Large Language Model for lnstruction-Followed Understanding and Safety-Aware Generation
Nov 25, 2023



While the recent advances in Multimodal Large Language Models (MLLMs) constitute a significant leap forward in the field, these models are predominantly confined to the realm of input-side multimodal comprehension, lacking the capacity for multimodal content generation. To fill this gap, we present GPT4Video, a unified multi-model framework that empowers Large Language Models (LLMs) with the capability of both video understanding and generation. Specifically, we develop an instruction-following-based approach integrated with the stable diffusion generative model, which has demonstrated to effectively and securely handle video generation scenarios. GPT4Video offers the following benefits: 1) It exhibits impressive capabilities in both video understanding and generation scenarios. For example, GPT4Video outperforms Valley by 11.8\% on the Video Question Answering task, and surpasses NExt-GPT by 2.3\% on the Text to Video generation task. 2) it endows the LLM/MLLM with video generation capabilities without requiring additional training parameters and can flexibly interface with a wide range of models to perform video generation. 3) it maintains a safe and healthy conversation not only in output-side but also the input side in an end-to-end manner. Qualitative and qualitative experiments demonstrate that GPT4Video holds the potential to function as a effective, safe and Humanoid-like video assistant that can handle both video understanding and generation scenarios.
A Comprehensive Study of GPT-4V's Multimodal Capabilities in Medical Imaging
Nov 06, 2023This paper presents a comprehensive evaluation of GPT-4V's capabilities across diverse medical imaging tasks, including Radiology Report Generation, Medical Visual Question Answering (VQA), and Visual Grounding. While prior efforts have explored GPT-4V's performance in medical image analysis, to the best of our knowledge, our study represents the first quantitative evaluation on publicly available benchmarks. Our findings highlight GPT-4V's potential in generating descriptive reports for chest X-ray images, particularly when guided by well-structured prompts. Meanwhile, its performance on the MIMIC-CXR dataset benchmark reveals areas for improvement in certain evaluation metrics, such as CIDEr. In the domain of Medical VQA, GPT-4V demonstrates proficiency in distinguishing between question types but falls short of the VQA-RAD benchmark in terms of accuracy. Furthermore, our analysis finds the limitations of conventional evaluation metrics like the BLEU scores, advocating for the development of more semantically robust assessment methods. In the field of Visual Grounding, GPT-4V exhibits preliminary promise in recognizing bounding boxes, but its precision is lacking, especially in identifying specific medical organs and signs. Our evaluation underscores the significant potential of GPT-4V in the medical imaging domain, while also emphasizing the need for targeted refinements to fully unlock its capabilities.
R2GenGPT: Radiology Report Generation with Frozen LLMs
Sep 18, 2023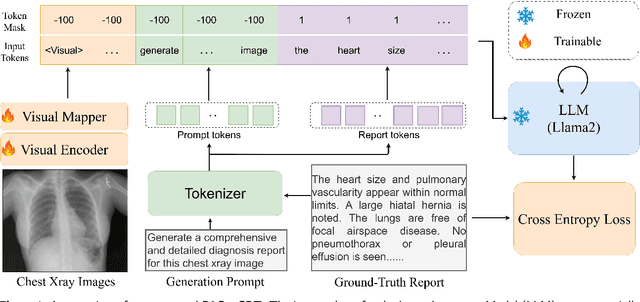
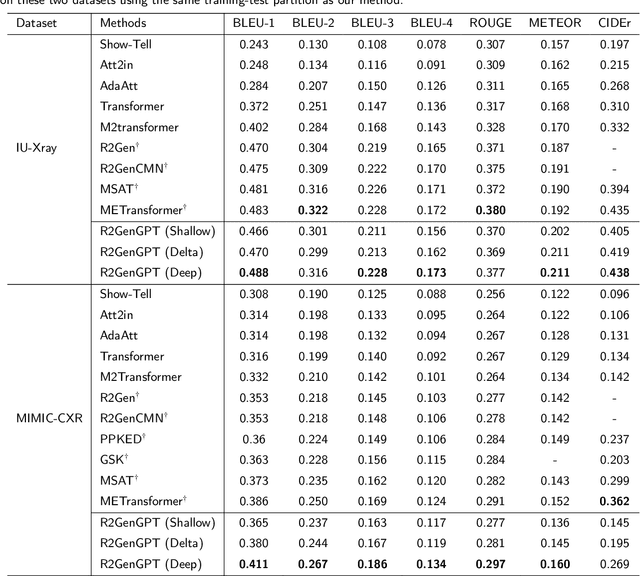
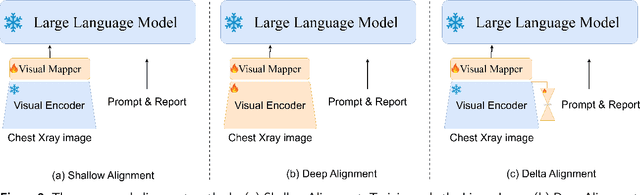
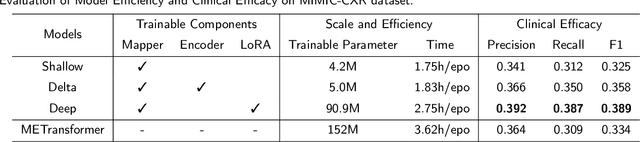
Large Language Models (LLMs) have consistently showcased remarkable generalization capabilities when applied to various language tasks. Nonetheless, harnessing the full potential of LLMs for Radiology Report Generation (R2Gen) still presents a challenge, stemming from the inherent disparity in modality between LLMs and the R2Gen task. To bridge this gap effectively, we propose R2GenGPT, which is a novel solution that aligns visual features with the word embedding space of LLMs using an efficient visual alignment module. This innovative approach empowers the previously static LLM to seamlessly integrate and process image information, marking a step forward in optimizing R2Gen performance. R2GenGPT offers the following benefits. First, it attains state-of-the-art (SOTA) performance by training only the lightweight visual alignment module while freezing all the parameters of LLM. Second, it exhibits high training efficiency, as it requires the training of an exceptionally minimal number of parameters while achieving rapid convergence. By employing delta tuning, our model only trains 5M parameters (which constitute just 0.07\% of the total parameter count) to achieve performance close to the SOTA levels. Our code is available at https://github.com/wang-zhanyu/R2GenGPT.
METransformer: Radiology Report Generation by Transformer with Multiple Learnable Expert Tokens
Apr 05, 2023



In clinical scenarios, multi-specialist consultation could significantly benefit the diagnosis, especially for intricate cases. This inspires us to explore a "multi-expert joint diagnosis" mechanism to upgrade the existing "single expert" framework commonly seen in the current literature. To this end, we propose METransformer, a method to realize this idea with a transformer-based backbone. The key design of our method is the introduction of multiple learnable "expert" tokens into both the transformer encoder and decoder. In the encoder, each expert token interacts with both vision tokens and other expert tokens to learn to attend different image regions for image representation. These expert tokens are encouraged to capture complementary information by an orthogonal loss that minimizes their overlap. In the decoder, each attended expert token guides the cross-attention between input words and visual tokens, thus influencing the generated report. A metrics-based expert voting strategy is further developed to generate the final report. By the multi-experts concept, our model enjoys the merits of an ensemble-based approach but through a manner that is computationally more efficient and supports more sophisticated interactions among experts. Experimental results demonstrate the promising performance of our proposed model on two widely used benchmarks. Last but not least, the framework-level innovation makes our work ready to incorporate advances on existing "single-expert" models to further improve its performance.
Q2ATransformer: Improving Medical VQA via an Answer Querying Decoder
Apr 04, 2023



Medical Visual Question Answering (VQA) systems play a supporting role to understand clinic-relevant information carried by medical images. The questions to a medical image include two categories: close-end (such as Yes/No question) and open-end. To obtain answers, the majority of the existing medical VQA methods relies on classification approaches, while a few works attempt to use generation approaches or a mixture of the two. The classification approaches are relatively simple but perform poorly on long open-end questions. To bridge this gap, in this paper, we propose a new Transformer based framework for medical VQA (named as Q2ATransformer), which integrates the advantages of both the classification and the generation approaches and provides a unified treatment for the close-end and open-end questions. Specifically, we introduce an additional Transformer decoder with a set of learnable candidate answer embeddings to query the existence of each answer class to a given image-question pair. Through the Transformer attention, the candidate answer embeddings interact with the fused features of the image-question pair to make the decision. In this way, despite being a classification-based approach, our method provides a mechanism to interact with the answer information for prediction like the generation-based approaches. On the other hand, by classification, we mitigate the task difficulty by reducing the search space of answers. Our method achieves new state-of-the-art performance on two medical VQA benchmarks. Especially, for the open-end questions, we achieve 79.19% on VQA-RAD and 54.85% on PathVQA, with 16.09% and 41.45% absolute improvements, respectively.