 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrchestrating Tokens and Sequences: Dynamic Hybrid Policy Optimization for RLVR
Jan 09, 2026Reinforcement Learning with Verifiable Rewards (RLVR) offers a promising framework for optimizing large language models in reasoning tasks. However, existing RLVR algorithms focus on different granularities, and each has complementary strengths and limitations. Group Relative Policy Optimization (GRPO) updates the policy with token-level importance ratios, which preserves fine-grained credit assignment but often suffers from high variance and instability. In contrast, Group Sequence Policy Optimization (GSPO) applies single sequence-level importance ratios across all tokens in a response that better matches sequence-level rewards, but sacrifices token-wise credit assignment. In this paper, we propose Dynamic Hybrid Policy Optimization (DHPO) to bridge GRPO and GSPO within a single clipped surrogate objective. DHPO combines token-level and sequence-level importance ratios using weighting mechanisms. We explore two variants of the mixing mechanism, including an averaged mixing and an entropy-guided mixing. To further stabilize training, we employ a branch-specific clipping strategy that constrains token-level and sequence-level ratios within separate trust regions before mixing, preventing outliers in either branch from dominating the update. Across seven challenging mathematical reasoning benchmarks, experiments on both dense and MoE models from the Qwen3 series show that DHPO consistently outperforms GRPO and GSPO. We will release our code upon acceptance of this paper.
Retrieval-augmented Multi-modal Chain-of-Thoughts Reasoning for Large Language Models
Dec 04, 2023



The advancement of Large Language Models(LLMs) has brought substantial attention to the Chain of Thought(CoT) approach, primarily due to its ability to enhance the capability of LLMs on tasks requiring complex reasoning. Moreover, the significance of CoT approaches extends to the application of LLMs for multi-modal tasks, such as multi-modal question answering. However, the selection of optimal CoT demonstration examples in multi-modal reasoning for LLMs remains less explored for LLMs due to the inherent complexity of multi-modal examples. In this paper, we introduce a novel approach that addresses this challenge by using retrieval mechanisms to dynamically and automatically select demonstration examples based on cross-modal similarities. This method aims to refine the CoT reasoning process in multi-modal scenarios via informing LLMs with more relevant and informative examples. Furthermore, we employ a stratified sampling method categorising demonstration examples into groups based on their types and retrieving examples from different groups respectively to promote the diversity of demonstration examples. Through a series of experiments, we demonstrate that our approach significantly improves the performance of LLMs, achieving state-of-the-art results in multi-modal reasoning tasks. Specifically, our methods demonstrate significant advancements on the ScienceQA dataset. While our method based on ChatGPT outperforms the Chameleon(ChatGPT) by 2.74% with an accuracy of 82.67%, the GPT4-based approach surpasses the Chameleon(GPT-4) by 0.89%, achieving 87.43% on accuracy under the same setting. Moreover, our best performing show a 6.05% increase over Chameleon for ChatGPT-based models and a 4.57% increase for GPT-4-based models.
On the Cultural Gap in Text-to-Image Generation
Jul 06, 2023


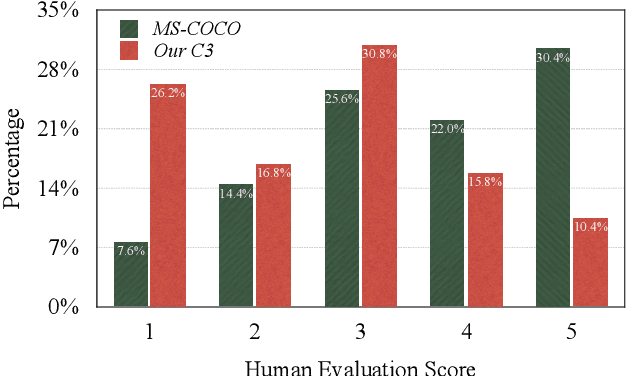
One challenge in text-to-image (T2I) generation is the inadvertent reflection of culture gaps present in the training data, which signifies the disparity in generated image quality when the cultural elements of the input text are rarely collected in the training set. Although various T2I models have shown impressive but arbitrary examples, there is no benchmark to systematically evaluate a T2I model's ability to generate cross-cultural images. To bridge the gap, we propose a Challenging Cross-Cultural (C3) benchmark with comprehensive evaluation criteria, which can assess how well-suited a model is to a target culture. By analyzing the flawed images generated by the Stable Diffusion model on the C3 benchmark, we find that the model often fails to generate certain cultural objects. Accordingly, we propose a novel multi-modal metric that considers object-text alignment to filter the fine-tuning data in the target culture, which is used to fine-tune a T2I model to improve cross-cultural generation. Experimental results show that our multi-modal metric provides stronger data selection performance on the C3 benchmark than existing metrics, in which the object-text alignment is crucial. We release the benchmark, data, code, and generated images to facilitate future research on culturally diverse T2I generation (https://github.com/longyuewangdcu/C3-Bench).
Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration
Jun 15, 2023Although instruction-tuned large language models (LLMs) have exhibited remarkable capabilities across various NLP tasks, their effectiveness on other data modalities beyond text has not been fully studied. In this work, we propose Macaw-LLM, a novel multi-modal LLM that seamlessly integrates visual, audio, and textual information. Macaw-LLM consists of three main components: a modality module for encoding multi-modal data, a cognitive module for harnessing pretrained LLMs, and an alignment module for harmonizing diverse representations. Our novel alignment module seamlessly bridges multi-modal features to textual features, simplifying the adaptation process from the modality modules to the cognitive module. In addition, we construct a large-scale multi-modal instruction dataset in terms of multi-turn dialogue, including 69K image instances and 50K video instances. We have made our data, code and model publicly available, which we hope can pave the way for future research in multi-modal LLMs and expand the capabilities of LLMs to handle diverse data modalities and address complex real-world scenarios.