 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrchestrating Tokens and Sequences: Dynamic Hybrid Policy Optimization for RLVR
Jan 09, 2026Reinforcement Learning with Verifiable Rewards (RLVR) offers a promising framework for optimizing large language models in reasoning tasks. However, existing RLVR algorithms focus on different granularities, and each has complementary strengths and limitations. Group Relative Policy Optimization (GRPO) updates the policy with token-level importance ratios, which preserves fine-grained credit assignment but often suffers from high variance and instability. In contrast, Group Sequence Policy Optimization (GSPO) applies single sequence-level importance ratios across all tokens in a response that better matches sequence-level rewards, but sacrifices token-wise credit assignment. In this paper, we propose Dynamic Hybrid Policy Optimization (DHPO) to bridge GRPO and GSPO within a single clipped surrogate objective. DHPO combines token-level and sequence-level importance ratios using weighting mechanisms. We explore two variants of the mixing mechanism, including an averaged mixing and an entropy-guided mixing. To further stabilize training, we employ a branch-specific clipping strategy that constrains token-level and sequence-level ratios within separate trust regions before mixing, preventing outliers in either branch from dominating the update. Across seven challenging mathematical reasoning benchmarks, experiments on both dense and MoE models from the Qwen3 series show that DHPO consistently outperforms GRPO and GSPO. We will release our code upon acceptance of this paper.
Mitigating the Negative Impact of Over-association for Conversational Query Production
Sep 29, 2024



Conversational query generation aims at producing search queries from dialogue histories, which are then used to retrieve relevant knowledge from a search engine to help knowledge-based dialogue systems. Trained to maximize the likelihood of gold queries, previous models suffer from the data hunger issue, and they tend to both drop important concepts from dialogue histories and generate irrelevant concepts at inference time. We attribute these issues to the over-association phenomenon where a large number of gold queries are indirectly related to the dialogue topics, because annotators may unconsciously perform reasoning with their background knowledge when generating these gold queries. We carefully analyze the negative effects of this phenomenon on pretrained Seq2seq query producers and then propose effective instance-level weighting strategies for training to mitigate these issues from multiple perspectives. Experiments on two benchmarks, Wizard-of-Internet and DuSinc, show that our strategies effectively alleviate the negative effects and lead to significant performance gains (2%-5% across automatic metrics and human evaluation). Further analysis shows that our model selects better concepts from dialogue histories and is 10 times more data efficient than the baseline. The code is available at https://github.com/DeepLearnXMU/QG-OverAsso.
Retrieval-augmented Multi-modal Chain-of-Thoughts Reasoning for Large Language Models
Dec 04, 2023



The advancement of Large Language Models(LLMs) has brought substantial attention to the Chain of Thought(CoT) approach, primarily due to its ability to enhance the capability of LLMs on tasks requiring complex reasoning. Moreover, the significance of CoT approaches extends to the application of LLMs for multi-modal tasks, such as multi-modal question answering. However, the selection of optimal CoT demonstration examples in multi-modal reasoning for LLMs remains less explored for LLMs due to the inherent complexity of multi-modal examples. In this paper, we introduce a novel approach that addresses this challenge by using retrieval mechanisms to dynamically and automatically select demonstration examples based on cross-modal similarities. This method aims to refine the CoT reasoning process in multi-modal scenarios via informing LLMs with more relevant and informative examples. Furthermore, we employ a stratified sampling method categorising demonstration examples into groups based on their types and retrieving examples from different groups respectively to promote the diversity of demonstration examples. Through a series of experiments, we demonstrate that our approach significantly improves the performance of LLMs, achieving state-of-the-art results in multi-modal reasoning tasks. Specifically, our methods demonstrate significant advancements on the ScienceQA dataset. While our method based on ChatGPT outperforms the Chameleon(ChatGPT) by 2.74% with an accuracy of 82.67%, the GPT4-based approach surpasses the Chameleon(GPT-4) by 0.89%, achieving 87.43% on accuracy under the same setting. Moreover, our best performing show a 6.05% increase over Chameleon for ChatGPT-based models and a 4.57% increase for GPT-4-based models.
Towards Better Document-level Relation Extraction via Iterative Inference
Nov 26, 2022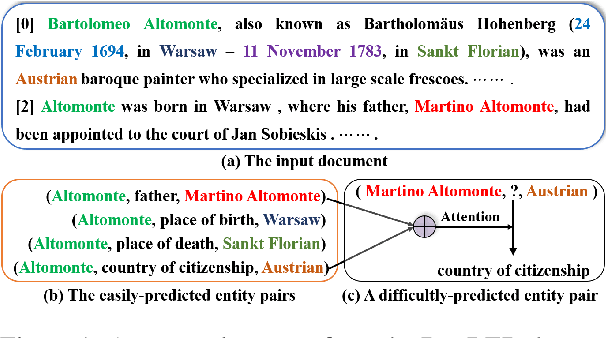
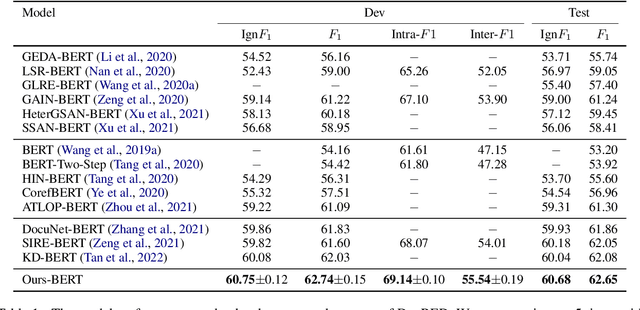
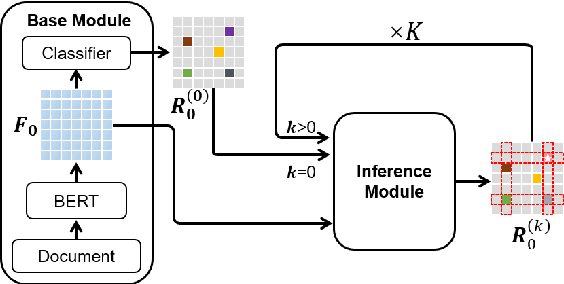
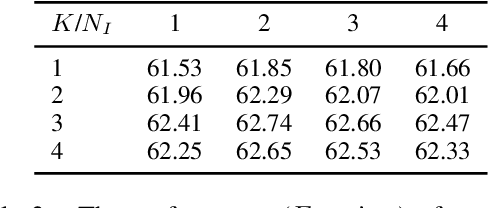
Document-level relation extraction (RE) aims to extract the relations between entities from the input document that usually containing many difficultly-predicted entity pairs whose relations can only be predicted through relational inference. Existing methods usually directly predict the relations of all entity pairs of input document in a one-pass manner, ignoring the fact that predictions of some entity pairs heavily depend on the predicted results of other pairs. To deal with this issue, in this paper, we propose a novel document-level RE model with iterative inference. Our model is mainly composed of two modules: 1) a base module expected to provide preliminary relation predictions on entity pairs; 2) an inference module introduced to refine these preliminary predictions by iteratively dealing with difficultly-predicted entity pairs depending on other pairs in an easy-to-hard manner. Unlike previous methods which only consider feature information of entity pairs, our inference module is equipped with two Extended Cross Attention units, allowing it to exploit both feature information and previous predictions of entity pairs during relational inference. Furthermore, we adopt a two-stage strategy to train our model. At the first stage, we only train our base module. During the second stage, we train the whole model, where contrastive learning is introduced to enhance the training of inference module. Experimental results on three commonly-used datasets show that our model consistently outperforms other competitive baselines.